哈希表
搜索概述
检索是指在一组记录集合中根据key来寻找value的过程。对于搜索来说,最关键的是搜索效率,尤其是对于大数据量,需要对待检索数据进行特殊的存储处理(比如搜索引擎有上千万的query,对应后端有几十亿的网页)来保证检索时间。为了提高搜索效率,常用的方法有:
-
预排序
排序算法本身比较耗时,无法实时来进行,因此排序只能作为预处理手段,在检索之前完成
-
建索引
如果对某种数据需要反复查找,则需要建立比较高效的索引,检索时充分利用辅助索引信息。代价是牺牲一定的空间,以空间换时间。同时维护成本也有所提高,当数据变化时,索引也要改变
-
散列
所谓散列就是把数据组织到一个表中,将Query通过某种算法(hash)得出它的value在表中的位置,从而完成检索。这种方式的优点是查询时间为
O(1),缺点是不适合进行范围查询,一般也不允许出现重复的关键码。另外,散列也不适合对磁盘文件进行检索(可以选择 B 树方法)。
平均检索长度
检索运算的主要操作为关键码的比较,所谓平均检索长度(Average Search Length)是指检索过程中对关键码的平均比较次数,它是衡量检索算法优劣的时间标准。
其中, $P_i$为检索第i个元素的概率,$C_i$为找到第i个元素所需的关键码值与给定值的比较次数
顺序检索
我们以顺序检索为例,看下平均检索长度是如何定义以及计算的。所谓线性表检索,其方法就是检索针对线性表里的所有记录,逐个进行关键码和给定值的比较,若某个记录的关键码和给定值比较相等,则检索成功,否则检索失败。
顺序检索可以用用于向量和列表,对数组是否有序没有要求。由于遍历算法相对简单,这里不做赘述,给出其性能分析
-
检索成功/失败
假设每个关键码等概率出现: $P_i=1/n$,从后向前遍历,如果最后一个数字恰好为关键码,则只需比较一次,如果关键码在第一个数字的位置,则需要比较$n-1$次,因此检索成功的概率为$p$,检索失败的概率为${1-p}$:
-
平均检索长度 将$p$,$q$带入公式可得到 $(n+1)/2 < ASL < (n+1)$
显然顺序检索的时间复杂度在$\Theta(n)$量级,时间略长,优化方式可采用给数组排序后,进行二分检索。对于二分检索和其性能分析可参考之前文章。二分检索过程可用一颗BST来表示,其中每个parent节点的值为数组每次二分mid位置对应的值:
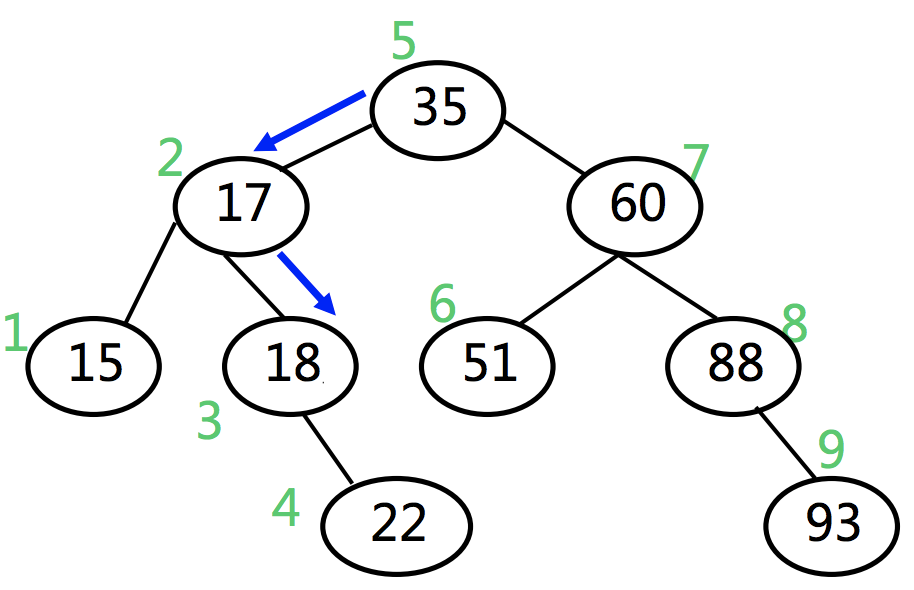
观察这棵树可发现,其最大的检索位置为叶节点22的位置,推而广之,可知二分法最大检索长度为$\lfloor \log{n+1} \rfloor$。其失败的检索位置有15,51,22,93因此,最大失败检索长度也为$\lfloor \log{n+1} \rfloor$。则其平均检索长度为:
散列搜索
通过上面线性表的检索可以看出,检索的过程是通过元素之间的比较来完成的,而基于比较的运算为无论怎么优化时间代价都是很高的(因为无论怎样都和n)相关,当n很大时,如果是实时搜索的场景,上述检索时间效率基本是无法接受的。那么一个比较理想的情况是怎样呢?我们希望
- 根据关键码值,直接找到记录的存储地址
- 不需要把待查关键码与候选记录集合的某些记录进行逐个比较
具有上述特征的数据结构在前面介绍向量时曾接触过,就是vector,vector可以通过下标访问可直接找到数据在内存中的位置,其原因是vector在内存是连续存储的,下标访问实际上是指针运算,因此可以快速寻址。
散列使用了相同的原理,只不过散列不是通过下标来访问的,通过对某个key的某种运算(“哈希”)得到地址(可理解为数组下标),然后根据该地址直接访问数据。因此使用散列搜索需要:
- 有一个散列函数
h,以结点的关键码K为自变量,函数值h(K)作为结点的存储地址,Address = Hash(key) - 需要一个存储空间,通常是一个一维数组,散列地址是数组的下标
假设我们有一组数据[1,32,43,24,95,86,77,108,249,10],我们要将它们映射到一个10个元素大小的vector内,可以另散列函数h(k) = key % 10,这样上述数据便可映射到散列表中。
key: 1 32 43 24 95 86 77 108 249 10
hashCode: 1 2 3 4 5 6 7 8 9 0
hashMap: <1,1> <2,32> <3,43> <4,24> <5,95> <6,86> <7,77> <8,108> <9,249> <0,10>
但是上述策略也并不完美,仍然存在很多问题,比如
- hashCode冲突如何处理(例如
32,42) - 数据多了,散列表大小怎么调整
- key的分布情况
- value的检索频率,例如对检索频率较高的key放到基地址,等等
散列函数的选取
从理论上讲,hashCode冲突是无法被解决的,那该怎么设计和评判散列函数呢?可以从如下几方面考虑:
- 确定性:同一关键码总是被映射到同一地址
- 快速:
O(1) - 满射:尽可能充分的覆盖整个散列空间
- 均匀:关键码映射到散列表中各个位置的概率尽量接近,也就是要将所有可能的key尽量均匀的压缩到散列空间,避免局部汇聚的情况
总的来说,对于散列函数,越是随机越好,随机意味着出现在任何位置的概率均相同。
- 除余法
所谓除余法是指对整数key除以某个整数M,并取余数作为散列地址。散列函数为:
通常选择一个小于散列表长的一个最大质数作为$M$值,这种方式数据对散列表的覆盖更充分,分布最均匀。前面提到的例子用的就是一个最简单的除余法,只使用了key的个位来求余数,实际的除余法中,函数值依赖于自变量 key 的所有位,而不仅仅是最右边 k 个低位。
这种简单的除余法自然有一些缺陷:
- 不动点: 无论$M$如何选取,总有
hash(0)= 0,这和所有key等概率映射的条件相矛盾 - 零阶均匀: 设key的取值范围从
[0,R),平均分配到M个桶,则相邻的key的散列地址也必然相邻。我们希望能找到更高阶的均匀,即相邻的key在散列后的位置不再相邻
可以修改上述散列函数稍作修改,除了$M$外,再寻找另外两个素数$a,b$,满足$ a>0, b>0, a \% M ≠ 0 $,则修改后的散列函数为:
新引入的$a$相当于步长的作用,$b$相当于偏移量,则原先相邻key在散列后距离为$a$,变得不再相邻,这种方法也叫做MAD法。另一种对除余法的改进策略是乘余取整法,这里就不展开介绍了。
Knuth认为:A 可以取任何值,与待排序的数据特征有关。一般情况下取黄金分割最理想
- 平方取中法
所谓平方取中法是值先通过求关键码的平方来扩大差别,再取其中的几位或其组合作为散列地址,例如
hash( 123 ) = 512 // 123^2 = 1[512]9 ,保留中间三位做散列地址
hash( 1234567 ) = 556 //1234567^2 = 15241[556]77489,保留中间三位做散列地址
- 折叠法
如果key所含的位数很多,采用平方取中法计算太复杂,这时可以使用折叠法。所谓折叠法是指将key分割成等宽的若干段分(最后一部分的宽度可以不同),然后取这几部分的叠加和(舍去进位)作为散列地址。叠加有两种方式:
- 移位叠加 — 把各部分的最后一位对齐相加
- 分界叠加 — 各部分不折断,沿各部分的分界来回折叠(zigzag order),然后对齐相加,将相加的结果当做散列地址
//移位叠加 //分界叠加
key = 123456789 key = 12345678
123 123
456 654
+ 789 + 789
----------- -------------
hash(123456789) = 1368 hash(123456789) = 1566
- 多项式法
针对以字符串为key的散列计算,其公式为:
上述式子可以在$O(n)$的时间内计算完成,可以用下面代码来近似上面的计算:
static size_t hashCode(char s[]){ //近似多项式计算,用位运算代替乘法运算
int h=0;
for(size_t n = strlen(s), i=0; i<n; i++){
h = (h<<5) | (h>>27); //交换h的前5个bit和后27个bit
h += (int)s[i];
}
return (size_t)h;
}
上述计算hashCode的方式更适合英文字符串,计算过程还是很复杂的
在实际应用中是很难找到一个对所有数据都能保持随机化的Hash函数,对于如何寻找Universal Hash Function的问题是一个数学问题,有很多学者都做过这方面的研究,这里就不展开讨论了,如果感兴趣,可参考本文最后一节中所附的资源
冲突解决
- Chaining
对于散列表,将每个key索引的对象设计成一个数组或者一个链表,用来存放冲突的词条。如果使用数组,只要数组或者链表的槽位不多,依然能保证查找的时间复杂度为$O(1)$
//使用数组
k1 : [v1,v1'v1'',...]
k2 : [v2,v2'v2'',...]
...
kn : [vn,vn',vn'',...]
使用数组的方式有也有缺点:
- 如果使用数组的方式,该预留多少个槽位给冲突的元素呢?
- 无论预留多少,极端情况下仍然可能不够用
另一种组织形式是使用链表,每个桶存放一个指针,重复的词条追加在一个指针链表上。假设给定一个大小为$M$存储 $n$个记录的表,散列函数(在理想情况下)将把记录在表中$M$个位置平均放置,使得平均每一个链表中有$n/M$ 个记录。当$M>n$时,散列方法的平均代价就是$Θ(1)$
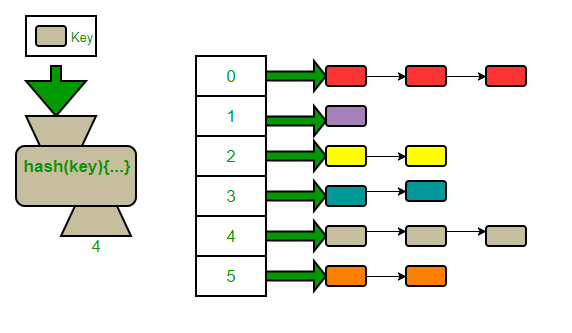
显然,使用链表的的好处是无需为每个key预留多个槽位,而且对冲突次数较多的key也能通过插入头指针的方式简单解决。实际应用中多采用使用链表的实现方式。但是这种方式的却点也很明显,比如节点需要额外申请空间,节点存储不连续等
- Open Addressing
对于开散列法,每个value归属于哪个桶是固定的,即先根据key找到指针链,然后再查找某个value,或者将value挂载上去。这种方式下,散列表内部对value的存储是不连续的。
所谓闭散列法(开放定制法),指的是散列表内部的存储空间是连续的,所有的value都存放在这片内存空间中,冲突也都在这一片内存中解决,而无需再申请新的内存空间。因此,和开散列法不同的是,对某个value,它存放某个桶的位置是不固定的,可以在这片内存中的任意位置。那么对于闭散列法,其冲突解决的策略是怎样的呢?
-
线性试探
所谓线性试探是指,当插入或者查找某个value时,一旦hashCode发生冲突,则试探其(基地址)后面的单元(探查序列),其试探的方式为key生成一个散列地址序列$d_1,d_2,…,d_{m-1}$(所有$d_i (0<i<m$ 是后继散列地址)
//基地址: hash(key) % M //试探地址: d1 = [hash(key) + 1] % M d2 = [hash(key) + 2] % M d3 = [hash(key) + 3] % M ... dn = [hash(key) + n] % M具体来说,以存储为例(查找的步骤类似):
- 首先根据其散列函数计算hashcode(基地址)
- 根据基地址先找到对应的存储位置(内存位置),如果是空的,则放入
- 如果发该位置已被占用(冲突),则重新计算hashCode,向后不断试探,直到找到一个空桶放入。
无论是插入还是查找,都假定每个关键码的探查序列中至少有一个存储位置是空的作为结束标记,否则可能会进入死循环。接下来看一个具体的查找的例子:
M = 15, hash(key) = key % 13 key : | 26 | 25 | 41| 15| 68| 44| 6 | | | | 36 | | 38 | 12 | 51 | index: | 0 | 1 | 2 | 3 | 4| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | -------|----|----|---|---|---|---|---|---|---|---|----|----|----|----|----| value: | x | y | z | a | b | c | d | | | | e | | f | g | h |上述例子中
-
平方试探
线性探查的优点是表中所有的存储位置都可以作为插入新记录的候选位置。其缺点是每次探查步长为1,对于同义词表较长的情况(“聚集”现象)探测效率很低。解决办法是增加探测步长,我们可以平方数为步长来确定下一步探测的位置,由于依旧是对$M$取模,因此不会超出数组范围
d1 = [hash(key) + 1^2] % M d2 = [hash(key) + 2^2] % M d3 = [hash(key) + 3^3] % M ... dn = [hash(key) + n^2] % M当采用平方试探后,在查找链上,步长线性递增,一旦冲突,可聪明的逃离是非之地,因此可以有效的避免数据聚集。但是步长的增加又会带来另一个的问题,即当发生冲突后不再是逐个位置去试探,这样即使冲突位置的下一个位置是空位,也会被跳过,因此即使散列表中还有空位,按照这种方式也不一定能被试探出来。
看这样一个例子,散列表
map<int,char>,其容量$M = 12$,令hash函数为 $ hash(key) = key \% 12 $,假设已经插入的key为{0,1,4,9},现在要插入{12,b},此时key=12算出插入位置为0,发生冲突,按照平方步长向后试探,则会依次尝试的位置有1,4,9,0,1,4,9,0...,一直循环下去。而此时散列表还有8个空位未被利用,显然这个策略是失效的。key : | 0 | 1 | | | 4 | | | | | 9 | | | | -------|----|----|---|---|---|---|---|---|---|---|----|----|----| index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | -------|----|----|---|---|---|---|---|---|---|---|----|----|----| value: | x | y | | | z | | a | | | |可以证明,若M为合数,$n^2/M$ 可能的取值必然少于 $ \lfloor M/2 \rfloor $ 种
若取质数$M = 11$作为散列表长度,假设散列表中已经插入的key为
{0,1,3,4,5,9},当插入{11,b}时,按照平方步长向后试探,则会依次尝试的位置有:0,1,4,9,5,3,3,5,9,4,1,0,4...最多只有6个位置,此时有接近一半的位置是空的。key : | 0 | 1 | | 25| 4 | 16| | | | 9 | | | | -------|----|----|---|---|---|---|---|---|---|---|----|----|----| index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | -------|----|----|---|---|---|---|---|---|---|---|----|----|----| value: | x | y | | | z | c | | a | | | |可以证明,若M为素数,$n^2/M$ 可能的取值恰好有 $ \lceil M/2 \rceil $ 种,位置恰好是查找链的前$ \lceil M/2 \rceil $ 项,因此,如果要使用平方试探法,当$M$为素数时,装填因子$\lambda $ (key的个数和散列表长度的比值 )必须小于等于 $0.5$
-
双向平方试探
为了解决上述平方试探的问题,可以使用双向平方试探。具体来说,如果一旦发生冲突,则交替的向前,向后进行单向平方试探。
d1 = [hash(key) + 1^2] % M d2 = [hash(key) - 1^2] % M d3 = [hash(key) + 2^2] % M d4 = [hash(key) - 2^2] % M d5 = [hash(key) + 3^3] % M d6 = [hash(key) - 3^3] % M ... dn-1 = [hash(key) + n^2] % M dn = [hash(key) - n^2] % M还是上面的例子,$M=11$,如果在位置
0出现冲突,按照双向平方试探的方法,则试探过程为index | | | | | | 0| | | | | | | | ------|--|--|--|--|--|--|--|--|--|--|--|--|--| 1st | | | | | | 0| 1| | | | | | | ------|--|--|--|--|--|--|--|--|--|--|--|--|--| 2nd | | | | |10| 0| 1| | | | | | | ------|--|--|--|--|--|--|--|--|--|--|--|--|--| 3rd | | | | |10| 0| 1| | | 4| | | | ------|--|--|--|--|--|--|--|--|--|--|--|--|--| 4th | | 8| | |10| 0| 1| | | 4| | | | ------|--|--|--|--|--|--|--|--|--|--|--|--|--|考察当$M=5,7,11,13$时,双向平方探测所能覆盖的位置如下:
---|--|--|--|--|--|--|--|--|--|--|--|--|--| 5 | | | | | 1|4 |0 | 1|4 | | | | | ---|--|--|--|--|--|--|--|--|--|--|--|--|--| 7 | | | |5 |3 |6 | 0| 1|4 |2 | | | | ---|--|--|--|--|--|--|--|--|--|--|--|--|--| 11 | |8 |6 |2 |7 |10| 0| 1|4 |9 |5 |3 | | ---|--|--|--|--|--|--|--|--|--|--|--|--|--| 13 |3 |1 |10|4 |9 |12| 0| 1|4 |9 |3 |12|10|可见,当$M=5,7$时,双向平方探测可覆盖全部空位,而且位置互异,但是当$M=5,13$时,依旧会出现重复。因此,对于素数$M$要想满足$key % M$的结果互异,必然存在某种限制条件。而这个限制就是$M$满足:
-
双散列探查
无论是线性探查还是平方探查,对步长的计算都是基于基地址的,所谓双散列探查是指在计算探查序列函数时,引入另一个散列函数数,使探测步长和key的值做关联:
若key在地址$h_1(key)= d$发生冲突,则再计算$h_2(key)$,得到探查序列为:
(d+h2(key))%M
(d+2*h2(key))%M
(d+3*h2(key))%M
...
$h_2(key)$尽量与$M$互质,这样可使发生冲突的同义词地址尽量分布在整个表中,否则可能造成同义词地址的循环计算。对于$M$和$h_2(k)$的选择可以参考如下方法:
- 选择$M$为一个素数,$h_2$ 返回的值在$1 ≤ h_2(K) ≤ M – 1$范围之间
- 设置$M=2^m$,让$h_2$返回一个$1$到$2^m$之间的奇数
- 若$M$为素数,$h_1(k) = k \thinspace mod \thinspace M$
- $h_2(k) = k \thinspace mod \thinspace (M-2) + 1$
- 或者 $h_2(k) = [k/M] \thinspace mod \thinspace (M-2) + 1$
- 若$M$为任意数,$h_1(k)= K \thinspace mod \thinspace p $, (除余法,$p$是小于$M$的最大素数)
- $h_2(k) = k \thinspace mod \thinspace q+1$ (q是小于p的最大素数。+1为了避免0的出现)
如何选择冲突解决方案
装载因子
对于Hash Table有一个重要的指标称作装载因子,其定义如下
这个指标代表Hash Table的装载率,装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
通常来说装载因子有一个阈值,当哈希表超过这个阈值时,需要对hash表进行动态扩容。假设每次扩容我们都申请一个原来散列表大小两倍的空间。如果原来散列表的装载因子是0.8,那经过扩容之后,新散列表的装载因子就下降为原来的一半,变成了0.4。
但是扩容会带来一个问题,就是原先的key映射的槽位可能会发生改变,导致我们需要通过散列函数重新计算每个元素数据的存放位置。
对于使用chaining实现的Hash Table这个$\alpha$数值可以大于1,这说明会有某些bucket的链表长度大于1。但通常情况下,最好保持这个值远小于1,这意味着,当插入的数据增加时,Hash Table的空位也要跟着增加,比如当$\alpha=0.5$时,可令空位数量跟着增大一倍
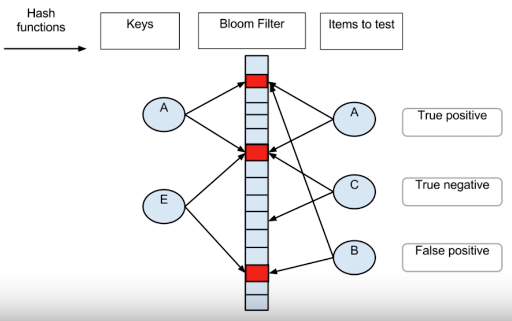
Bloom Filter
Bloom Filter是Burton Bloom在1970年发明的一种数据结构。它和Hash Table相比,它占用空间更小,查询速度更快,但是无法进行Key-Value存储,功能类似Hash Set,可以用于快速检索一个元素是否在集合中。
Blloom Filter最早被用来做拼写检查,检查一个单词是否在字典中,这种场景要求对用户输入的单词做快速的检查,因此速度是第一位的,同时也允许有一定的查询错误。另一个场景是用来检查用户输入的密码是否在无效的密码列表中,做法是预先向Bloom Filter中存入可能的无效密码,当用户输入密码时,实时在Bloom Filter中进行匹配,这种场景同样也要求速度快,也允许有一定的错误率,比如错误率为0.1%,即1000个人中有一个人输入了正确的密码但被判定为错误密码,这种情况下对用户的操作不会带来太大的影响。在现代的应用中,Bloom Filter可以用来实现network router,对Packet进行实时过滤。
总的来说,Bloom Filter适用的场景为:对空间有限制 ,对查询速度有要求以及允许一定的错误率。Bloom Filter的优点是空间利用率和查询时间都远超一般算法,缺点是有一定的误识别率以及删除困难。
Bloom Filter的实现
布隆滤波器使用一个二进制向量作为容器,每当有一个元素进入容器时,计算该元素的二进制,并将对应的容器位置为1,如下图所示: