
二叉搜索树
从这一篇开始我们将围绕一种特殊的二叉树及其变种进行长时间的讨论,先从最基本的二叉搜索树开始,所谓二叉搜索树(Binary Search Tree)是具有下列性质的二叉树:
- 对于任意节点,设其值为
K - 该节点的左子树(若不空)的任意一个节点的值都小于
K - 该节点的 右子树(若不空)的任意一个节点的值都大于
K - 该节点的左右子树也是BST
- BST的中序遍历即是节点的正序排列(从小到大排列)
二叉搜索树及其变种是内存中一种重要的树形索引(关于索引,在后面文章中会提到),常用的BST变种有红黑树,伸展树,AVL树等,从这篇文章开始将会依次介绍这些树的特性及其实际应用。
BST的三种操作
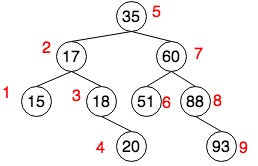
- 搜索
上图中,假如我们要搜索20,根据BST的性质,每次只需要检索两个子树之一,直到20被被找到,或者走到叶子节点停。我们如果将BST的中序遍历序列用数组表示,搜索过程实际上就是二分法:
15 17 18 20 35 51 60 88 93
由于每次搜索都是target和该节点的value,而且这个过程是重复的,因此可以使用递归来实现,思路为:
后面的例子中,统一使用TreeNode来表示二叉树的节点,可将TreeNode理解为:
typedef TreeNode BinaryTreeNode<int>
TreeNode* search(TreeNode* node, int target){
if(!node || node->val == target){
return node;
}
//递归
if(target < node->val){
return search(node->left,target);
}else{
return search(node->right,target);
}
}
查找的运算时间正比于待查找节点的深度,时间复杂度和二分法相同,均为$O(log_2^{N})$,最坏情况下不超过树的高度,BST退化为单调序列,时间复杂度为$O(N)$。
- 插入
插入算法的实现思路是先借助搜索找到插入位置,再进行节点插入,值得注意的是,对于插入节点的位置一定是某个叶子节点左孩子或右孩子为NULL的位置
- 从根节点开始搜索,在停止位置插入一个新叶子节点。
- 假如我们要插入
17,如下图搜索树,直到遇到19搜索停止,17成为19左叶子节点。 - 插入新节点后的二叉树依然保持BST的性质和性能
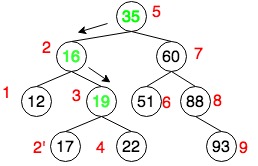
按照上面步骤,其插入的实现思路为:
void insert(TreeNode* node,int target){
if( target == node->val ){
return; //禁止重复元素插入
}else if(target < node->val){
if(!node->left){
node ->left = new TreeNode(target);
return;
}else{
insert(node->left,target);
}
}else{
if(!node->right){
node->right = new TreeNode(target);
return;
}else{
insert(node->right,target);
}
}
}
插入的运算时间主要来自两部分,一部分是search,一部分是插入节点。最好的时间复杂度为$O(log_2^{N})$,最坏情况下为$O(N)$
- 删除
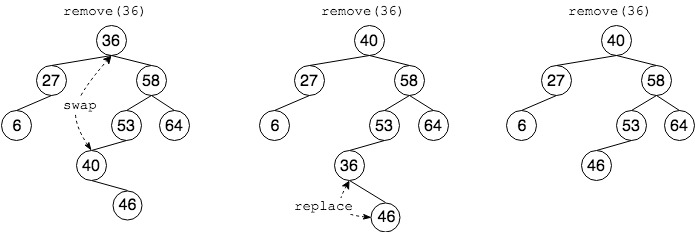
相对于插入操作,节点的删除操作则略为复杂,但仍是基于搜索为主要框架,找到待删除元素后,再根据不同分支做不同的处理:
- 如果该节点没有左子树,则使用右子树替换该节点
- 如果该节点没有右子树,则使用左子树替换该节点
- 如果该节点既有左子树也有右子树,则找到右子树中最小的节点,将该节点的值替换为待删除节点的值,删除该节点
TreeNode* deleteNode(TreeNode* root, int key) {
if(!root){
return NULL;
};
if(root->val < key){
root->right = deleteNode(root->right,key);
}else if(root->val > key){
root->left = deleteNode(root->left,key);
}else{
if(!root->left && !root->right){
delete root;
return NULL;
}else if(!root->left){
TreeNode* right = root->right;
delete root;
return right;
}else if(!root->right){
TreeNode* left = root->left;
delete root;
return left;
}else{
//找到右子树中最小的节点
TreeNode* rt = root->right;
while(rt->left){
rt = rt->left;
}
//替换为该节点的值
root->val = rt->val;
//重复删除过程
root->right = deleteNode(root->right,rt->val);
}
}
return root;
}
对于删除算法,同插入操作一样,最好的时间复杂度为$O(log_2^{N})$,最坏情况下为$O(N)$。
实际上,关于BST删除操作,还有个取巧的方法,就是将要删除的节点标记为“已删除”,但是并不真正从树中删除这个节点。这样原本删除的节点还需要存储在内存中,比较浪费内存空间,但是删除操作就变得简单了很多。而且,这种处理方法对插入,查找操作也没有影响。
重复元素
上面的讨论假设BST中没有重复的元素,如果有重复的关键码BST该如何存储呢?有两种方案,第一种是令BST中每个节点保存一个双向链表,相同的数据存放在链表中。第二种方式则是将重复的元素当值更大的节点存入到右子树中,如下图所示
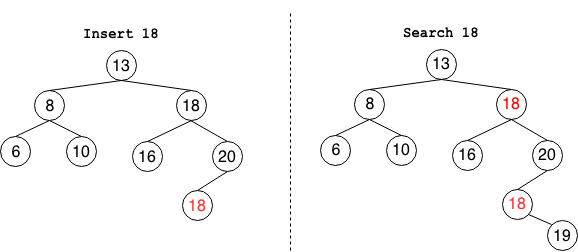
当要查找数据的时候,遇到值相同的节点,我们并不停止查找操作,而是继续在右子树中查找,直到遇到叶子节点才停止。这样就可以把键值等于要查找值的所有节点都找出来。