树与森林
树与线性结构
前一节介绍了二叉树,它是一种特殊的树形结构,有很多应用的场景,但是我们没有回答一问题,为什么要有树这种结构?在树之前我们一直采用线性结构对数据进行存储和操作,包括数组和链表,但是对于这两种结构来说,它们都有各自的优势和劣势,对于数组,查找很快,但是插入删除要O(n),对于列表,则反过来。有没有一种数据结构可以做到查找和插入删除操作效率都很高呢?答案就是使用树,对于树来说,可以把它看做是列表的列表list<list<T>>,即树的每个节点只有唯一一个前驱节点,而可能有多个后继节点,因此我们可以说树是一种“半线性”结构。而当树的每个节点只有一个子节点(后继)时,树则退化为链表。
树的特性
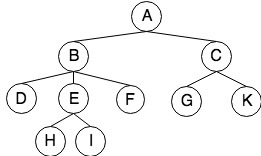
从数学角度来看, 树是一种特殊的图 $T=(V,E)$,节点数 $| V |=n$,边数 $ | E | =e $,它表述了一组元素之间的二元关系。每棵树它可以有根,这里主要讨论有根的树。对于“树”有下面几个特点
- 使用集合来描述
- 树(tree)是包括n个节点的有限集合T(n≥1),它有一个特定的节点,称为根,除了根之外的节点被划分成$m$个不想交的集合,$T_1,T_2,…,T_m$,每个集合又都是树,称为$T$的子树
- 树也可以用集合表示,例如上面的树,用集合表示为:
- 节点结合
K={ A,B,C,D,E,F,G,H,I,J } - $K$上的关系 `r= { <A,B>,<A,C>,<B,D>,<B,E>,<B,F>,<C,G>,<C,H>,<E,I>,<E,J>}
- 节点结合
- 树是有序有向的
- 树的兄弟节点之间是有序的,对于子树来说,和它平行的子树称为兄弟(sibling),兄弟之间亦有次序,可以从最左子树开始编号,向右递增
- 此外,度为2的有序树并不是二叉树。因为第一子节点被删除后,第二子节点自然顶替成为第一
- 连通无环图
- 从图论的角度讲,树是一种在连通和无环之间达到平衡的一种图。在保证连通的前提下,由于树不成环,它的边数能达到最少,因此它是一种极小的连通图;但是由于没有环路,树又可以使用最多的边,因此,它又是一种极大的无环图
- 在有根节点的前提下,任一节点$v$与根节点之间存在唯一路径 $path(v,r) = path(v)$,即每个节点可用到达该节点的边数来表示,我们称这个值为$c$。如果同一类的节点具有相同的$c$值,我们称这些节点为等价类,例如上图中深度为2的等价对有$<D,E>,<E,F>,<F,G>,<G,K>$
- 树的深度和层次
- 根节点是所有节点的公共祖先,深度为0
- 没有后代的节点称为叶子节点,树中必然存在叶子节点
- 所有叶子节点中深度最大者称为树的高度 $height(v) = height(subtree(v))$
- 树的规模
- 令一棵树中的节点数为$n$,对每个节点 $r$ 的度数为$degree(r)$, 边的数目为$e$,他们之间有如下关系:
这个公式可以表明$n$个节点的树有 $n-1$条边,树的边数和节点数是同阶的,一棵树的规模如果可以度量为节点数+边数 $(n+e)$,那么从渐进的角度来看,树的规模也是和节点数或者边数是同阶的,因此后面讨论时间复杂度时可以以树节点的数目为参照
- 森林
- 零棵或者多棵不相交的树的集合
- 一棵树,删掉树根,其子树就构成了森林
- 加入一个节点作为根,森林就转化成了一棵树
- 零棵或者多棵不相交的树的集合
森林和二叉树
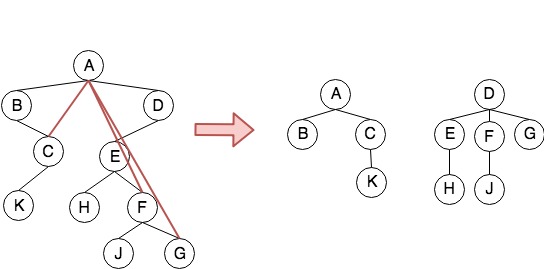
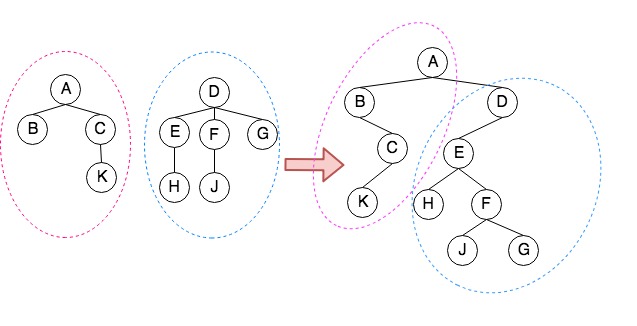
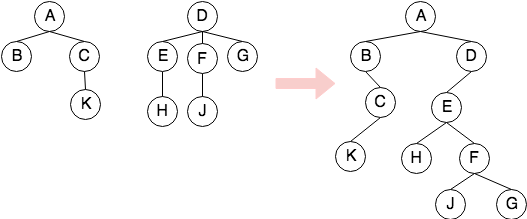
- 森林转二叉树
假设现在有一个森林,由三个集合组成,记作:$F={T_1,T_2,T_3}$。现在希望将这个森林转换成一颗二叉树$B(F)$,规则如下:
- $B(F)$的根是$T_1$的根
- $B(F)$的左子树为$T_1$除去根节点后的子树组成的二叉树3
- $B(F)$的右子树为${T_2,T_3}$组成的二叉树。
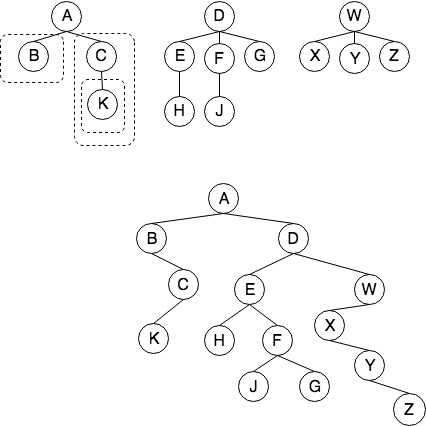
如上图所示,不难发现将上面虚线部分是一个递归合并的过程(将两棵子树合并成一课二叉树,而每棵子树又有自己的子树)。对于任意两棵子树,其合并的过程为:
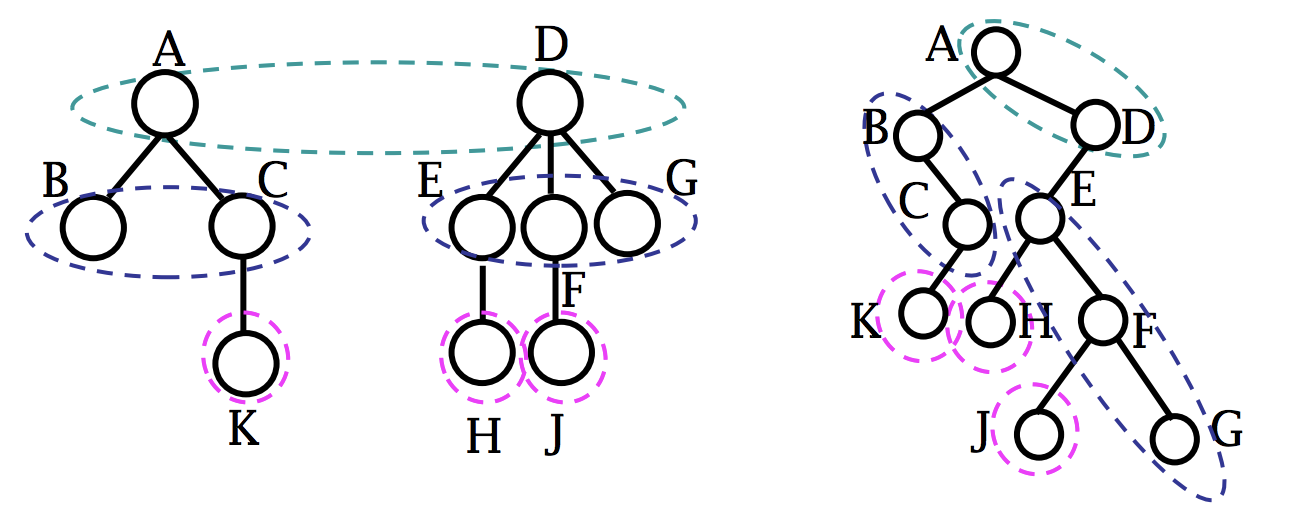
- 在森林中的所有兄弟节点之间加一连线
- 对每个节点,去掉除了与第一个孩子之外的其他所有连线
- 调整位置
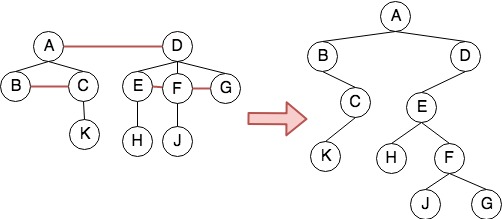
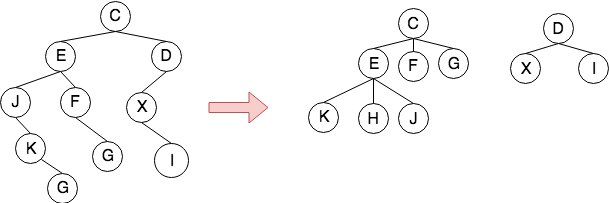
- 二叉树转森林
类似的,设$B$是一棵二叉树,root是$B$的根,$B_L$ 是root的左子树,$B_R$ 是root的右子树,则对应于二叉树$B$的森林或树$F(B)$的规则为:
- 若$B$为空,则$F(B)$是空的森林
- 若$B$不为空,则$F(B)$是一棵树$T_1$加上森林$F(B_R)$其中树$T_1$ 的根为root,root的子树为$F(B_L )$
对于二叉树的任意一个非叶子节点,将其拆成森林的过程为:
- 将除根节点以外的右子节点都与根节点相连
- 去掉所有父节点和其右子节点的连线
- 调整位置
树的Interface
template<class T>
class Tree {
public:
Tree(); // 构造函数
virtual ~Tree(); // 析构函数
void CreateRoot(const T& rootValue); // 创建值为rootValue的根节点
bool isEmpty(); // 判断是否为空树
//
TreeNode<T>* getRoot(); // 返回树中的根节点
TreeNode<T>* Parent(TreeNode<T> *current); // 返回父节点
TreeNode<T>* PrevSibling(TreeNode<T> *current); //返回前一个兄弟
//修改操作
void DeleteSubTree(TreeNode<T> *subroot); // 删除以subroot子树
void Insert
//遍历
void RootFirstTraverse(TreeNode<T> *root); // 先根深度优先遍历树
void RootLastTraverse(TreeNode<T> *root); // 后根深度优先遍历树
void WidthTraverse(TreeNode<T> *root); // 广度优先遍历树
};
树的几种实现方式
- 父节点表示法
如果对于树中的节点,只需要知道它的父节点信息,不需要保存子节点的信息,则可以使用父节点表示法,使用一个数组来存储其所有节点,其节点存储顺序可以任意指定,父节点的位置通过数组下标来表示。
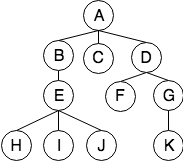
假如上面一棵树,可以使用下面数组来进行存储:
index: 0 1 2 3 4 5 6 7 8 9 10
data: A B C D E F G H I J K
parent: -1 0 0 0 1 3 3 4 4 4 6
于是可以把data+parent合并成一个结构作为树的节点,而数组可以放到树里维护
template<class T>
class TreeNode { // 树节点的ADT
T data;
int parent;
};
template<class T>
class Tree {
vector<TreeNode> nodes; //数组
int n; //节点数
Tree
}
父节点表示法的性能分析:
- 空间复杂度:$O(n)$
- 时间复杂度:
- 查找
parent()节点: $O(1)$ - 查找
root()节点: $O(n)$或$O(1)$ - 查找
leftMostChild()节点:$O(n)$ - 查找
sibling()节点:$O(n)$
- 查找
- 动态数组表示法
在父节点表示法中,查找子节点相对困难,需要遍历整个数组,效率较低,因此可以考虑在上述节点中加入子节点数组,这样在查找子节点时只需遍历子节点数组即可。
index: 0 1 2 3 4 5 6 7 8 9 10
data: A B C D E F G H I J K
parent: -1 0 0 0 1 3 3 4 4 4 6
children: | | | | |
[1,2,3 ][4] [5,6] [7,8,9] [10]
template<class T>
class TreeNode { // 树节点的ADT
int parent;
T data;
vector<TreeNode* >children; //可以用数组,也可以用链表
};
//Rootfirst Traverse
void traverse(TreeNode* root){
visit(root);
for(auto child : root->children){
traverse(child);
}
}
这种方式比适用于:
- 森林中只有以一棵树
- 适合构造一颗静态的树,用于遍历或者搜索
- 不适合动态插入或者删除节点
- 二叉链表示法
对每个节点维护两个指针:纵向”最左孩子”节点和横向”下一个右兄弟节点”,这种方式实际上是上面提到的,将一片森林或者一个k叉树转为了二叉树(实际上任何树都可以用二叉树表示),由于这种方式不是很直观,将规则归纳如下:
- 森林中最左边的子树,记为
T1,它的根节点为树T的根节点 T的左子节点为T1的最左子树,T的右子节点是T1的右侧兄弟节点T2- 对于
T2,重复第2步,它的左节点为自己的最左子树,它的右节点为T2的右侧兄弟节点T3 T3, T4...以此类推
对森林中的一个棵子树来说,最重要的是它自己第一个左孩子(pChild),和下一个兄弟节点(pSibling);此时森林转化为一颗二叉树,pChild对应二叉树的左子节点,pSibling对应二叉树的右子节点。对原先森林中的每个子树它所有的子节点均退化到二叉树根节点的pChild上,而根节点的右子节点pSibling连接的是其兄弟子树,也即所有非根左节点上的右链均为其它子树,理解了上述概念对理解这种方表示法很重要
template<class T>
class TreeNode { // 树节点的ADT
private:
T m_Value; // 树节点的值
TreeNode<T> *pChild; // 第一个左孩子指针
TreeNode<T> *pSibling; // 右兄弟指针
public:
TreeNode(const T& value); // 拷贝构造函数
virtual ~TreeNode() {}; // 析构函数
...
};
对于森林来说,如果想找到任何一个节点的父节点比较麻烦,因为没有维护指向父节点的指针。可以按照如下思路操作
- 采用宽搜
- 令森林中所有子树的根节点入队
- 访问队列,对于每个弹出的根节点,检查它的
LeftMostChild,如果和待查找节点相同,则返回该根节点。不同则入栈该,指针指向其兄弟节点,即在该层上进行宽搜 - 重复过程3,直到找到该节点
TreeNode<T>* Parent(TreeNode<T> *current){
queue<TreeNode<T>*> aQueue;
TreeNode<T>* pointer = root; //树的根节点
TreeNode<T>* father = upperLevelPointer = NULL;
//森林中所有子树根节点进队列
if(current != NULL && pointer != current){
while(pointer != NULL){
if(current == pointer){
break;
}
aQueue.push(pointer); //入队
pointer = pointer->RightSibling(); //该树根节点的右兄弟节点
}
}
while(!aQueue.empty()){
pointer = aQueue.front();
aQueue.pop();
upperLevelPointer = pointer;//维护该层指针
pointer = pointer -> LeftMostChild(); //水平遍历下一层
while(pointer){
if(current == pointer){
father = upperLevelPointer ;
break;
}else{
aQueue.push(pointer);
pointer = pointer -> RightSibling();
}
}
}
return father;
}
树的遍历
森林的遍历也可以从深度和广度两个维度来实现
- 深度优先遍历
- 先根遍历,对应二叉树的前序遍历
- 后根遍历,对应二叉树的中序遍历
例如上图中先根序列为:A B C K D E H F J G,后根序列B K C A H E J F G D
//对于先根遍历,其思路是先根节点,然后左孩子树,然后右兄弟节点
void RootFirstTraverse(TreeNode<T>* root){
while(root != NULL){
//访问节点
visit(root);
// 遍历第1棵树根的子树森林(树根除外)
RootFirstTraverse(root->LeftMostChild);
RootFirstTraverse(root->RightSibling);
}
}
//后根遍历
RootLastTraverse(TreeNode<T> * root) {
while (root != NULL) {
// 遍历第一棵树根的子树森林
RootLastTraverse(root->LeftMostChild());
Visit(root->Value()); // 访问当前节点
root = root->RightSibling(); // 遍历其他树
}
}
- 宽度优先遍历森林
- 首先依次访问层数为0的节点
- 然后依次访问层数为1的节点
- 直到访问完最下一层的所有节点
上图中的广度优先遍历顺序为A D B C E F G K H J,其遍历顺序对应二叉树结构的右斜线,是一种右子节点优先的遍历方式,注意森林的广度优先遍历不等于二叉树的广度优先遍历,对应上图中,二叉树的广度优先遍历次序为A B D C E K H F J G
void WidthTraverse(TreeNode<T> * root) {
queue<TreeNode<T>* > aQueue;
TreeNode<T> * pointer = root;
//森林中所有子树的根节点入队
while (pointer != NULL) {
aQueue.push(pointer); // 当前节点进入队列
pointer = pointer->RightSibling(); // pointer指向右兄弟
}
while(!aQueue.empty()){
pointer = aQueue.front();
aQueue.pop(); // 当前节点出队列
Visit(pointer->Value()); // 访问当前节点
pointer = pointer-> LeftMostChild(); // pointer指向最左孩子
while(pointer != NULL){ // 当前节点的子节点进队列
aQueue.push(pointer);
pointer = pointer->RightSibling();
}
}
}
树的序列化
所谓树的序列化指的是如何存储一棵树以及如何从一段数据中恢复出树结构。树的序列化与反序列化的方法有很多,主要有两大类,一类是使用节点的度,另一类是使用节点的左右孩子标记,这里介绍后一种
为了存储方便,我们将每个节点按照下面结构进行组织
-----------------------
| ltag | info | rtag |
-----------------------
`info`:结点的数据
`rtag`:二叉树结点没有右子结点,`rtag`为 1,否则为0
`ltag`:二叉树结点没有左子结点,`ltag`为 1,否则为0
假如我们有下面两棵树,将其合并成二叉树后进行序列化,可得到
rtag 0 0 1 1 1 0 1 0 1 1
info A B C K D E H F J G
ltag 0 1 0 1 0 0 1 0 1 1
显然,将一棵树序列化是比较容易的,而反序列化则要麻烦很多,如果原先是先跟序列存储的,需要使用栈来做中间存储工具,如果是按照层次序列则需要用队列做中间存储工具。假如们有下面数据(按先根序存储),我们研究如何将其反序列化为一棵树
rtag 0 0 0 0 1 0 1 1 0 1
info C E J K L F G D X I
ltag 0 0 1 1 1 1 1 0 1 1
- 逐个读取存储节点,new一个新节点
- C节点左右tag的值都为0,说明它有左右节点,但是还不知道是谁,先入栈保存,重复1
- E节挂载到C的左节点,此时C的ltag为1。E和C一样,左右tag的值都为0,先入栈,重复1
- J节点挂在到E的左节点,此时E的ltag为1。J的ltag为1,没有左孩子,但是右孩子为0,需要填补,因此入栈,重复1
- K节点挂载到J的右结点,此时J的左右tag都为1,J出栈;同时K的rtag为0,需要填补,入栈,重复1。
- L节点挂载到K的右结点,此时K的左右tag都为1,K出栈;同时L的左右tag也为1;不需入栈,重复1
- 此时栈顶为E节点,将F节点挂载到E的右节点,此时E的左右tag都为1,E出栈;F的rtag为0,需要填补,入栈,重复1
- G的操作和L类似,重复1
- 此时栈中只剩C,因此D要挂在到C的右结点
- D,X,I的恢复过程类似