
静态索引
索引相当于图书馆的卡片目录,有了卡片目录之后,就不需要在整个书库中搜索某一本书,而可以在卡片目录中检索到该书的位置。
索引概述
索引主要是针对外层文件系统或者数据库文件而设计的一种查询技术。在数据库系统中,每条记录存在文件系统中,文件本质上是一种线性存储结构,如果要查找某个记录,需要从文件头开始逐个去查找,由于是外存访问,效率非常的低。因此我们可以考虑,对于经常需要查找的数据是不是可以建立有效的索引。
- 主码
对于数据库中的每条记录,如果他有某种key可以使得它能够唯一的区分其它记录,那么可以考虑为这个key建立索引。这种key叫做主码( primary key ) 是数据库中的每条记录的唯一标识,对于数据库中的表都要指定其主码,便于检索。例如,公司职员信息的记录的主码可以是职员的身份证号码,通过检索身份证号,可以定位到该条员工记录。
- 辅码
但是如果只有主码,还是不能够进行灵活的检索。需要引入辅码的概念,所谓辅码是指是数据库中可以出现重复值的码,例如,不同员工的生日可能相同,这个生日字段就就可作为一个辅码信息。辅码索引把一个辅码值与具有这个辅
码值的每一条记录的主码值关联起来,例如通过辅码,可以将所有生日为2011-05-04的员工关联起来。数据库中的大多数检索都是利用辅码索引来完成的
- 索引
索引( indexing ) 是把一个关键码与它对应的数据记录的位置相关联的过程,其形式为<key,pointer>,指针指向主要数据库中的完整记录。索引的信息就是由若干个上述二元组组成的,这些二元组又可以组成索引文件(index file),索引技术是组织大型数据库中的一种重要技术。
- 索引文件
一个主文件可以有多个相关索引文件
- 主索引文件只有一个
- 对于辅码,如果需要经常查找,可以对其建立多个索引文件,每个索引文件支持一个辅码字段
- 多个索引文件在数据库做插入删除操作时,也需要更新,有代价
- 稠密索引/稀疏索引
- 稠密索引: 如果主索引文件没有按照关键码的顺序进行排序,则对每个记录都建立一个
<key,pointer>的索引对 - 稀疏索引:主索引文件排序后,由于磁盘中每条记录是连续存储的,因此只需要给出头部(记录起始位置)索引对,通过指针偏移即可定位到其它记录
线性索引
所谓线性索引,是指对数据库中的每条记录建立<key,pointer>的索引,然后按照关键码(key)的顺序进行排序后形成线性索引文件。文件中的指针指向存储在磁盘上的文件记录起始位置或者主索引中主码的起始位置。
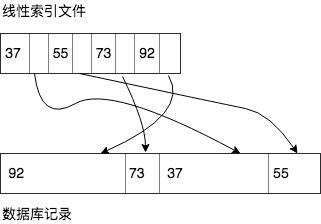
上述例子中,我们可以先在检索文件中对key进行二分查找,找到key值后根据pointer找到对应的记录。
二级索引
但是,随着数据库文件的增多,索引文件也会增大时,当大到没法一次读入内存时,便只能放入磁盘中进行I/O读写,效率很低。针对这种情况,可以建立二级索引,即索引的索引。在二级索引中,关键码与一级索引中第一条记录的关键码值相同,指针指向相应磁盘块的起始位置。
例如,磁盘块大小为1024个字节,即一次I/O操作读写的大小为1024字节,一个索引对<key,pointer>需要8个字节,则磁盘每块能存储1024/8 = 128个索引对。如果一个数据库有10000条记录需要约为10000/128 = 79个磁盘块,因此我们需要79个磁盘快来建立这样一个密集的索引,这也意味着将索引表读入内存就需要79次I/O,效率太低。这时如果使用二次索引,二级索引文件中只有79个索引对,使用一个磁盘块存储即可。
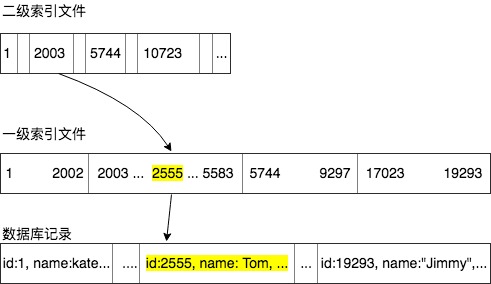
如上例,如果检索key=2555所在记录,则检索步骤如下:
- 二级线性索引文件读入内存
- 二分法找关键码的值小于等于
2555的最大关键码所在一级索引磁盘块地址, 即关键码为2003的记录 - 根据记录
2003中的地址指针找到其对应的一级线性索引文件的磁盘块,并把该块读入内存 - 按照二分法对该块进行检索,找到所需要的记录在磁盘上的位置
- 最后把所需记录读入,完成检索操作
静态索引
所谓静态索引,是指索引结构在文件创建、初始装入记录时生成,一旦生成就固定下来,在系统运行(例如插入和删除记录)过程中索引结构并不改变。只有当文件再组织时才允许改变索引结构,基于静态索引的一些小的变种可以支持小量的更新。
静态索引的一种实现方式是使用多分树,多分树和BST类似,相比于BST多分树更适合外存。假如索引文件中的关键码已经排好序,其结构可以用一棵BST来表示:
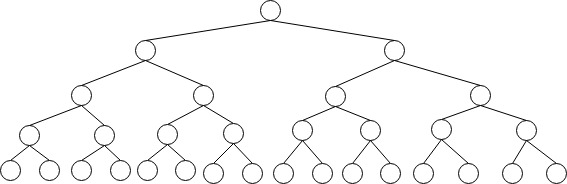
BST构成了一个多级索引结构,树中每个叶节点表示数据库中每条记录的位置,每个兄弟节点表示索引文件中某个key在下一级索引文件中的位置。当数据库文件创建好后,即可生成这样一个静态索引结构