
Overview
编译器和解释器的区别
- Compiler:
- program -> compiler -> exec + data -> output
- Interpreters:
- program+data -> Interpreter -> output
历史
- 1954 IBM develops the 704
- 这个时候发现software取代hardware,成了性能的瓶颈。
- Speedcoding:
- 1953, by Jon Backus
- 解释型语言
- 优势是提高了开发效率
- 劣势是代码执行效率很低
- 比直接手写代码慢10-20倍
- 解释器占了300字节,相当于全部内存的30%
实际上,Speedcoding并没有流行起来,但John Backus认为自己的思路是有正确的,并将它用到了另一个项目中。由于当时的重要的application主要是scientific application。学术界通常都需要计算机能直接执行公式(Formulas),John Backus认为Speedcoding最大的问题是使用了解释器去实时解析公式,于是他这次改变了思路:将公式(Formulas)先变成可执行的机器码(Translate),这样能加快程序的执行速度,同时又能保持开发的高效,于是便有了FORTRAN 1。
- FORTRAN 1
- 1954 - 1957
- 1958 : 50% 的代码都是通过FORTRAN写的
- 世界上第一个编译器诞生了
- FORTRAN成了世界上第一个比较成功的高级编程语言,对计算机科学产生了深远的影响
- 现代的编译器保留了FORTRAN 1的一些框架:
- Lexical Analysis
- Parsing
- Sementic Analysis
- Optimization
- Code Generation
How Compiler Works
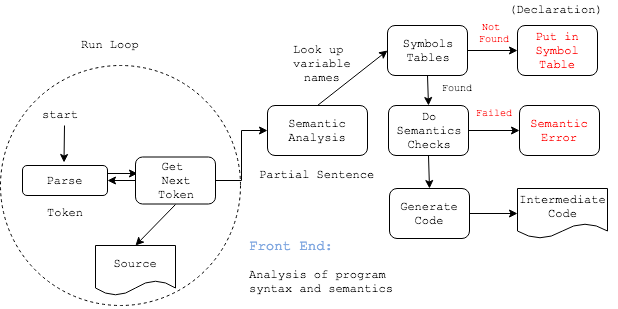
Lexical Analysis
LA也叫词法分析,LA的输入是程序字符串,输出是一系列的词法单元(token),例如:
main(){
printf("Hello World");
}
LA会依次读取程序的每一个字符,并将其存入token buffer中,然后不断check当前buffer中的token是否存在于token表中(对于任何一门编程语言都有一组可参考的token符号表)。例如,读到main时,buffer状态如下:
--------------------
| Token Buffer |
|--------------------
| niam |
---------------------
查token表发现,main属于关键字,因此标记为一个token, 依次类推,上面代码可以分解为以下的一些tokens:
Keyword: main, printf
Operator: (, ), {, }, ;
Constant: "Hello World"
Seperator: space
每个token都可以用一个tuple来表示:
<token-name,attribute-value>
token的name代表这个token的类型,value用来记录该token在符号表中的index。例如下面语句的token表示为
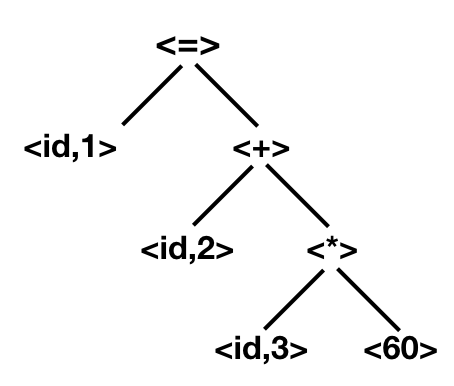
pos = initial + rate * 60
pos是一个token,用<id,1>,id表示这个token是一个符号,1表示它在符号表的第一个位置=是一个token,用<=>表示,因为它不是符号,因此不计入符号表initial是token,用<id,2>表示+是一个token,用<+>表示rate是token,用<id,3>表示*是一个token,用<*>表示60是一个token,用<number,4>表示,严格意义来说它不计入符号表
上述语句经过LA之后变成:[ <id,1>, <=>, <id,2>, <+>, <id,3>, <*>, <60> ],其语法树结构如下:
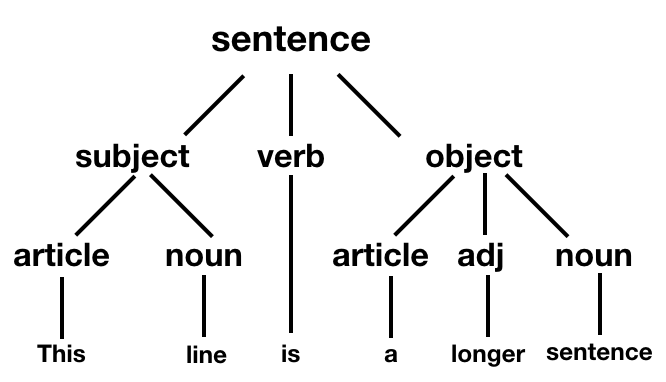
Parsing
Parsing也叫语法分析(syntax analysis),Parsing的目的是将LA产生的一系列token形成语法树。 假如我们要解析一个英文句子,可以把它的结构用树形结构来描述,例如下面句子的树形结构为
This line is a long sentence
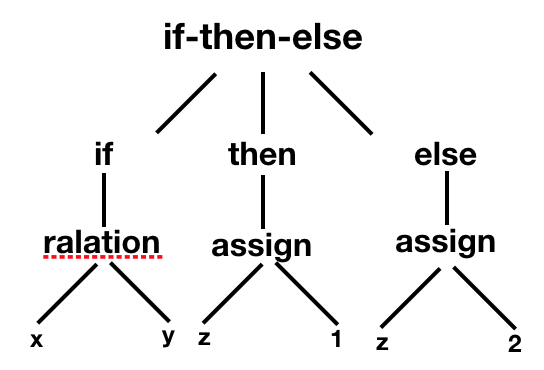
我们分析代码语句成分也是类似的,例如下面语句:
if x==y then
z = 1;
else
z = 2;
类似的树形结构为:
Semantic Analysis
一旦树形结构确定,接下来就是最难的语义分析,编译器在这方面很难保持它的理解和programmer的理解是一致的,以英语为例:
“Jack said Jerry left his assignment at home.”
编译器很难理解his指的是jack还是jerrry。再来看一种极端情况:
“Jack said Jack left his assignment at home?”
编译器不理解,到底有几个人,两个Jack是不是同一个人,his只谁?
这种问题对于编译器来说,是variable binding,编译器在处理这类变量名称模糊的情况,是由严格语法规定的:
{
int jack = 3;
{
int jack = 4;
cout<<jack;
}
}
上面的例子中两个jack都是相同的类型,因此编译器需要通过scope来判断输出哪一个jack。除了通过variable binding之外,还可以使用类型判断语义。比如:
“Jack left her homework at home.”
Jack的类型为male,her显然类型为female。由此,编译器便可以知道句子中Jack和her不是同一个人,对应到程序中,便是有两个不同类型的变量。
Optimization
优化通常是用来减少代码体积,例如:”But a little bit like editing” 可被优化成:”But akin to editing”,节省了代码容量,代码能运行的更快,消耗内存较少,编译器的优化是有针对性的,比如:
x = y*0
在满足一定条件时才会会被优化成:
x = 0
仅仅当,x,y是整数的时候,编译器才会这么优化。当x或y为浮点型时,x,y为NAN类型,而
NAN * 0 = NAN
Code Generation:生成代码
- 生成汇编代码
- 转换成平台相关语言
小结
- 基本上所有的compiler都会遵从上面几个步骤
- 但是从FORTRAN开始,上面5部分的比重却在发生变化:
- 对于比较老的编译器来说,L,P所占的比重会很高,S,O会很低
- 对于现代编译器来说,由于有了工具,L,P所在比重明显下降,而O所占的比重却大幅度上升
Economy of Programming Language
- 为什么有很多种编程语言?
- 科学计算,需要大量计算,需要对float point numbers支持,需要对array支持的很好和并行计算。并不是每种语言都能很好的支持上面的需求,FORTRAN在这方面做的很好。
- 商用:需要持久化存储,report generation,数据分析。SQL在这方面做的很好 - 系统编程:low level control of resource,real time constrains。C/C++ - 需求很多,很难设计一种语言满足所有场景。
- 为什么还有新的编程语言不断涌现?
- 传统语言改变的很慢,学习新语言很容易。如果新语言能更快的解决问题,那么它就有存在的价值
附录 Cool Overview
- Cool是用来学习编译器的语言:(Classroom Object Oriented Language)。
- Compiler很容易被实现
- 特性:抽象,静态类型,继承,内存管理等。
- 目标 : 生成MIPS汇编代码
demo
- 使用emacs:
%emacs 1.cl
- 编译cool:
%coolc 1.cl- 生成
1.s的汇编代码
- 运行cool:
%spim 1.s