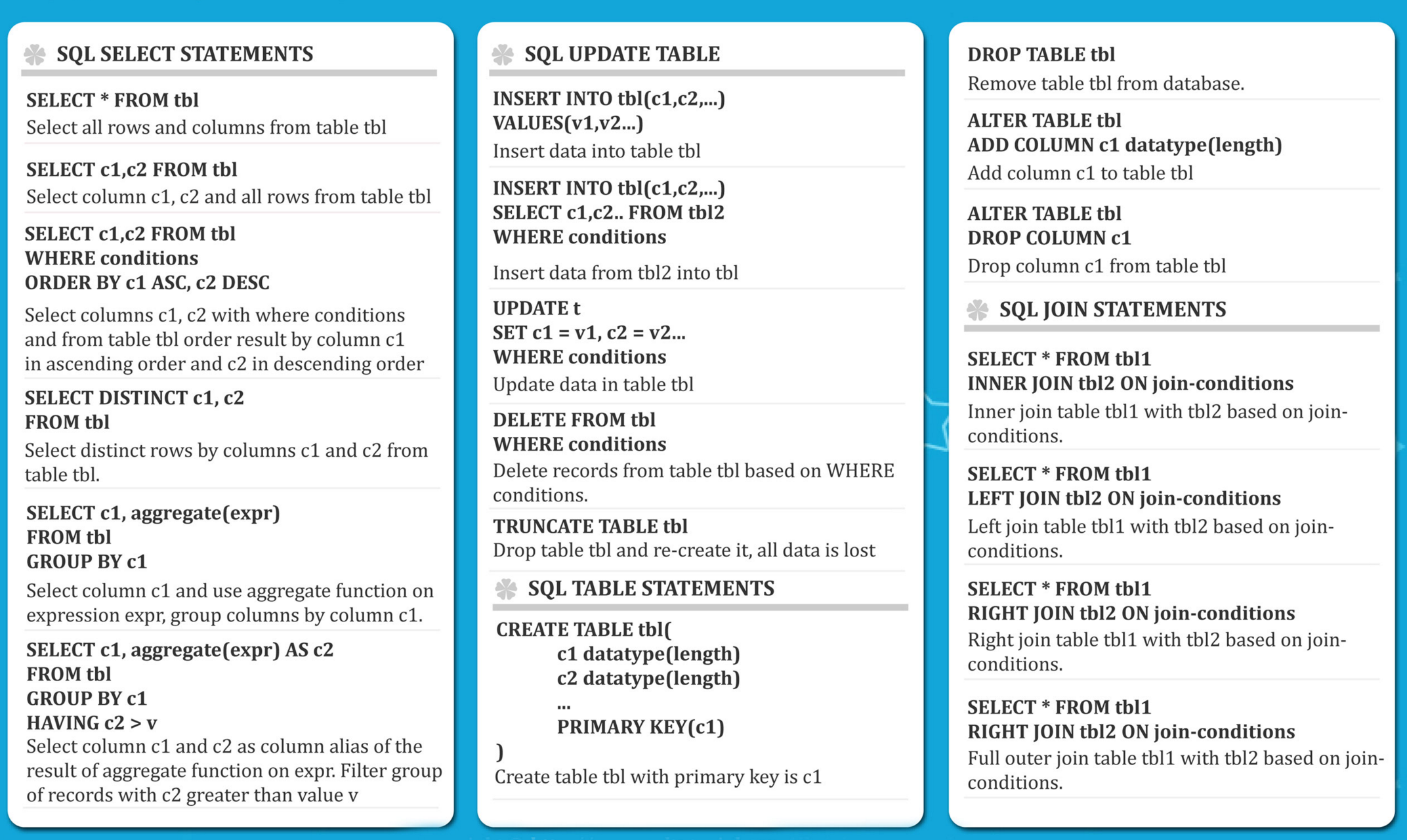
SQL Syntax
Schema
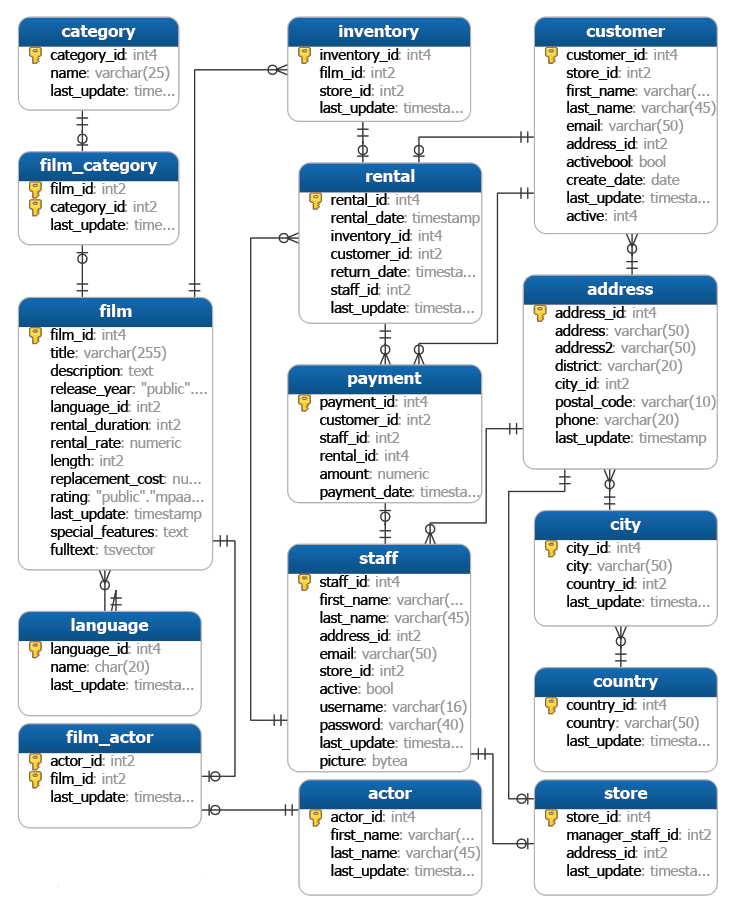
例子中用到的Schema和sample database
SQL Basic Syntax
SELECT
- SELECT
SELECT column1, column2,...FROM table_name;
查询包含某列所有的行数据(包含重复信息)
SELECT * FROM actors;
SELECT actor_id, first_name FROM actors;
SELECT actor_id FROM actors;
- SELECT DISTINCT
SELECT DISTINCT column1, column2,...FROM table_name;
查询包含某列的所有行数据(去重)
<!-- 查询所有电影发布年限的取值 -->
SELECT DISTINCT release_year FROM film;
<!-- 查询所有电影分级的取值 -->
SELECT DISTINCT rating FROM film;
- SELECT WHERE
SELECT column_1, column_2,...column_n FROM table_name WHERE conditions
根据条件查询某条行数据,过滤条件不一定要包含查询的属性。PostgreSQL提供一系列的条件判断操作符:
| OPERATOR | DESCRIPTION |
| = | Equal |
| > | Greater than |
| < | Less than |
| >= | Greater than or equal |
| <= | Less than or equal |
| <> or != | Not equal |
| AND | Logical operator AND |
| OR | logicl operator OR |
SELECT last_name, first_name
FROM customer
WHERE first_name = 'Jamie';
SELECT last_name, first_name
FROM customer
WHERE first_name = 'Jamie' AND last_name = 'Rice';
SELECT customer_id, amount,payment_date
FROM payment
WHERE amount<=1 OR amount>=8;
<!-- 过滤条件不一定包含查询的信息 -->
SELECT email
FROM customer
WHERE first_name = 'Jared' AND last_name='Thomas';
- COUNT
SELECT COUNT(*) FROM table;
SELECt COUNT(colunm) FROM table;
SELECT COUNT(DISTINCT colunmn) FROM table;
COUNT返回SELECT查询结果的数量
SELECT COUNT(*) FROM payment;
SELECT COUNT(DISTINCT amount) FROM payment;
- LIMIT
查询包含某列的有限条的行数据(包含重复信息),顺序从上到下
SELECT * FROM customer LIMIT 5;
- ORDER BY
SELECT column_1, column_2 FROM table_name
ORDER BY column_3 ASC/DESC, column4 ASC/DESC;
对查询得到的行数据进行某个属性进行升序或者降序的排序,默认为升序排列
<!-- 对first_name升序排列 -->
SELECT first_name, last_name FROM customer
ORDER BY first_name ASC;
<!-- 对last_name进行降序排列后,再对first_name进行升序排雷 -->
SELECT first_name, last_name FROM customer
ORDER BY last_name DESC, first_name ASC;
<!-- 对所有first_name='Kelly'的last_name降序 -->
SELECT first_name, last_name FROM customer
WHERE first_name = 'Kelly'
ORDER BY last_name DESC
<!-- -->
SELECT customer_id,amount FROM payment
ORDER BY amount DESC
LIMIT 10;
PostgreSQL允许ORDER BY的字段和SELECT的字段不相同,例如 SELECT first_name FROM user ORDER BY last_name;其它数据库不允许这种情况
- BETWEEN
value BETWEEN A AND B
value NOT BETWEEN A AND B
通常和WHERE一起使用,用来做过滤条件,查询具备某个列属性的闭区间值的所有行数据,
SELECT customer_id, amount FROM payment
WHERE amount BETWEEN 8 AND 9;
SELECT customer_id, amount FROM payment
WHERE amount NOT BETWEEN 8 AND 9;
SELECT amount,payment_date FROM payment
WHERE payment_date BETWEEN '2007-02-07' AND '2007-02-15';
- IN
value IN (value1, value2, ...)
value NOT IN (value1, value2, ...)
value IN (SELECT value FROM table_name)
value NOT IN (SELECT value FROM table_name)
通常和WHERE一起使用,用来做过滤条件,相当于OR,对于过滤值较多的情况,使用IN写法更简洁
SELECT customer_id,rental_id,return_date
FROM rental
WHERE customer_id IN (1,2)
ORDER BY return_date DESC;
SELECT customer_id,rental_id,return_date
FROM rental
WHERE customer_id NOT IN (7,12,19)
ORDER BY return_date DESC;
- LIKE
SELECT column1, column2 FROM table_name
WHERE column1 LIKE 'str%';
通常和WHERE一起使用,用来模糊查询,对查询条件进行模式匹配
%用来匹配任意序列Jen%开头为Jen的任意序列y%以y为结尾的任意序列%er%以er为中间字符的任意序列
_用来匹配单个字符%_en%%以任意字符开头+en+任意字符
<!-- 返回Jen开头的名字 -->
SELECT first_name, last_name FROM customer
WHERE first_name LIKE 'Jen%';
postgreSQL提供ILIKE,可以忽略字符大小写
GOURP BUY
- AVG/MAX/MIN/SUM
SELECT ROUND(AVG(amount),5) FROM payment;
SELECT MIN(amount) FROM payment;
SELECT MAX(amount) FROM payment;
SELECT SUM(amount) FROM payment;
- GROUP BY
GROUP BY将查询结果根据某种规则分成多个group,每个group可以使用上面提到的函数来进行计算。
- 单独使用GROUP BY相当于DISTINCT
SELECT customer_id
FROM payment
GROUP BY customer_id;
上述例子相当于按照customer_id查询所有记录,然后按照customer_id分组,因此得到的是customer_id去重后的记录
- 和Aggregate函数一起使用
SELECT customer_id, SUM(amount)
FROM payment
GROUP BY customer_id
ORDER BY SUM(amount);
将所有行数据按照customer_id进行分组,同一个customer_id可能有多条记录,相同customer_id的记录分在同一组,分组后对每组数据的amount字段进行求和。上述SQL的实际意义是统计每个用户消费的总金额,从高到低排列。
SELECT staff_id, COUNT(payment_id),SUM(amount)
FROM payment
GROUP BY staff_id
ORDER BY COUNT(payment_id) DESC;
上述例子对所有员工中,处理交易次数的统计以及处理交易金额的统计,并按照交易次数从高到低排列
- HAVING
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY colunm1
HAVING condition;
HAVING通常和GROUP一起使用,来过滤不满足条件的结果,类似于WHERE。和WHERE的区别在于,HAVING是在GROUP BY之后对分组后的每组数据进行过滤,WHERE实在GROUP_BY之前,对分组前的每组数据进行过滤。
SELECT customer_id, SUM(amount)
FROM payment
GROUP BY customer_id
HAVING SUM(amount) > 200;
在统计用户消费的基础上增加消费金额大于200的条件
SELECT rating,AVG(rental_rate)
FROM film
WHERE rating IN('R','G','PG')
GROUP BY rating
HAVING AVG(rental_rate)<3;
GROUP之前应用WHERE来做搜条件,GROUP之后用HAVING来做搜索结果的过滤条件
JOIN
- AS
给query重命名
SELECT payment_id AS my_payment_column FROM payment;
SELECT customer_id, SUM(amount) AS total_spent
FROM payment
GROUP BY customer_id;
- INNER JOINS
假设有两张表结构如下:
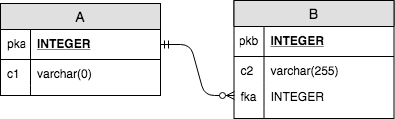
表A主键是pka,在B中fka是外键,想要查询AB中的数据,需要使用INNER JOIN
SELECT A.pka, A.c1, B.pkb, B.c2
FROM A
INNER JOIN B ON A.pka = B.fka
SELECT两个表中需要查询的column,A表中pka和c1字段,B表中pkb和c2字段。对A中的每条数据,在B中check是否有A.kpa = B.fka的数据,如果有将B中的该条数据和A中的该条数据合并后放入set返回。有时,AB中某项column会重名,因此需要使用table_name.column_name的形式,如果表名太长或者字段太长刻意使用alias。
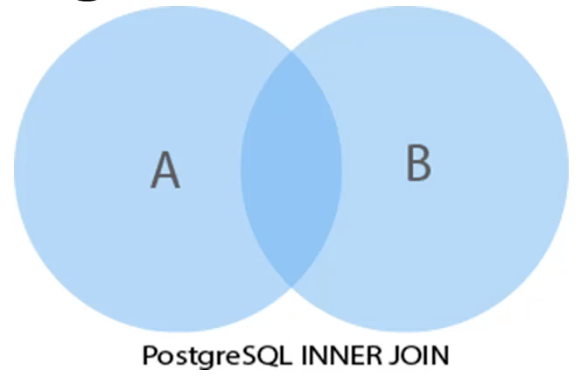
如果用文氏图表示,INNTER JOIN的关系可表示为下图:
<!-- Join customer table with payment table -->
SELECT
customer.customer_id, first_name,last_name,email,
amount,payment_date
FROM customer
INNER JOIN payment ON payment.customer_id = customer.customer_id;
上面查询语句中用来查询每个用户的交易记录,first_name,last_name,email来自customer表,amount,payment_date来自payment表,两个表之间通过customer_id进行关联。
也可增加WHERE语句查询某个人的交易记录
SELECT
customer.customer_id, first_name,last_name,email,
amount,payment_date
FROM customer
INNER JOIN payment ON payment.customer_id = customer.customer_id
WHERE first_name='Patricia';
另外,上述查询是令customer join payment,也可以反过来用payment join customer,结果一致。实际使用中,通常可以使用AS简化复杂命名操作,或者用空格代替AS,INNER JOIN也可以直接写为JOIN。
SELECT title, description, release_year,name AS move_language
FROM film
JOIN language AS lan ON film.language_id = lan.language_id;
JOIN TYPES
- INNTER JOIN
INNTER JOIN返回两个集合有公共colunm数据的交集
id nmae id name -- ------ --- ----- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja SELECT * FROM TableA INNTER JOIN TableB ON TableA.name = TableB.name id name id name -- ----- --- ---- 1 Pirate 2 Priate 3 Ninja 4 Ninja
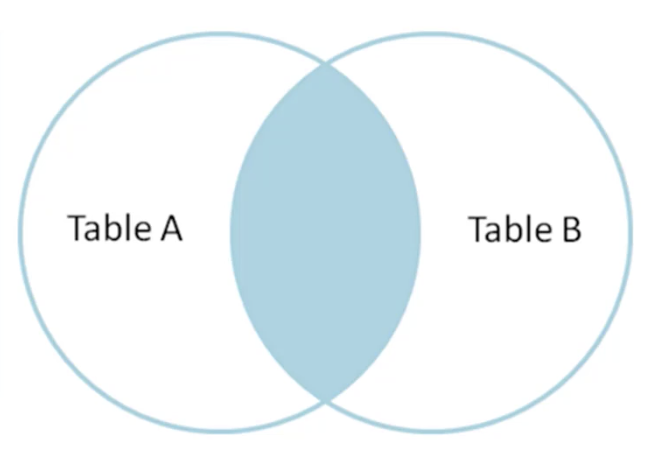
以一个实际例子看一下
- FULL OUTER JOIN
FULL OUTER JOIN返回两个集合的并集,对于两个集合没有交集的column,用null代替
id nmae id name -- ------ --- ----- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name id name id name -- ----- --- ---- 1 Pirate 2 Priate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vader
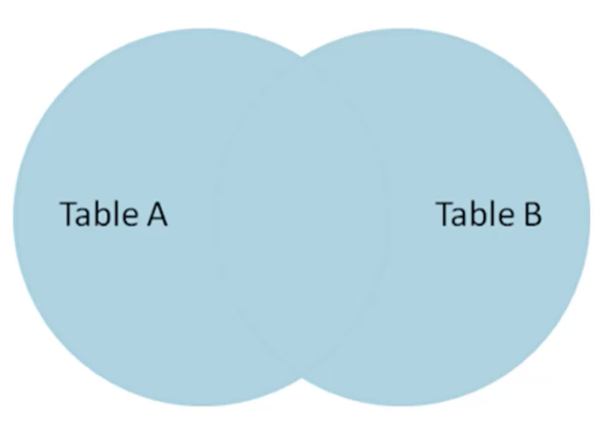
- FULL OUTER JOIN WITH WHERE
FULL OUTER JOIN WHERE 返回两个集合的非交集部分,对于没有交集的column,用null代替
id nmae id name -- ------ --- ----- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableA.id IS null OR TableB.id IS null id name id name -- ----- --- ---- 2 Monkey null null 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vader
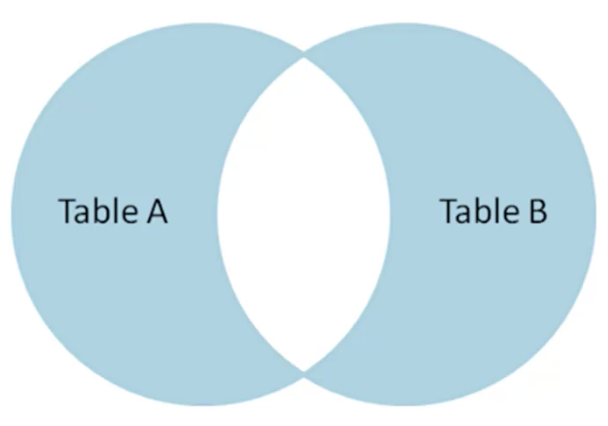
- LEFT OUTER JOIN
LEFT OUTER JOIN返回左边集合的全集,对于没有交集的colunm用null代替
id nmae id name -- ------ --- ----- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name id name id name -- ----- --- ---- 1 Pirate 2 Priate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null
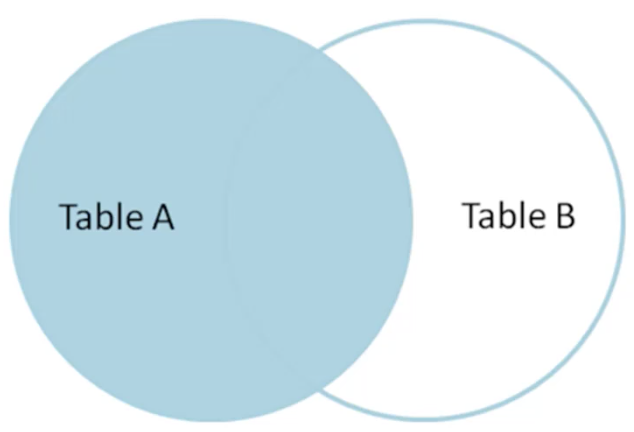
看下面例子,从前面的schema表中可以看出,每个film_id对应多个inventory_id,即每个影片有多个拷贝保存在不同的店里,因此在inventory表中,同一个film_id会有多条记录,现在希望查找。每个film的所有拷贝的库存ID。
SELECT film.film_id, film.title,inventory_id
FROM film
LEFT OUTER JOIN inventory ON inventory.film_id = film.film_id;
上面使用LEFT JOIN对所有film都找到了对应的库存ID,由于是LEFT JOIN,因此会有film对应的inventory_id为NULL的情况。一个更直观的方法查看方式是统计每个影片的库存,再按照库存数量排序
SELECT film.film_id, film.title, COUNT(inventory_id) AS TOTAL
FROM film
LEFT OUTER JOIN inventory ON inventory.film_id = film.film_id
GROUP BY film.film_id
ORDER BY TOTAL ASC;
- LEFT OUTER JOIN WITH WHERE
LEFT OUTER JOIN返回左边除去右边集合的数据,对于没有交集的colunm用null代替
id nmae id name -- ------ --- ----- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableB.id IS null id name id name -- ----- --- ---- 2 Monkey null null 4 Spaghetti null null
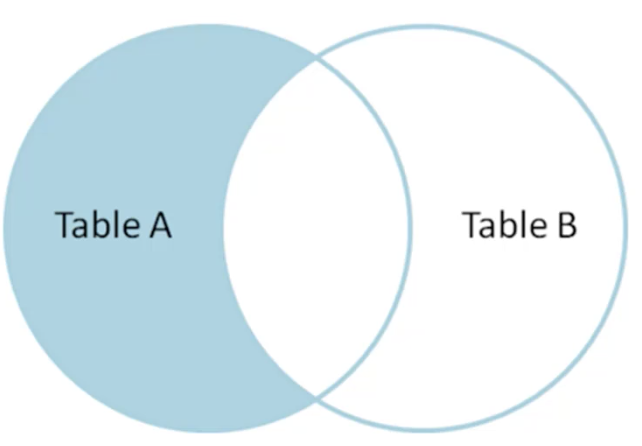
接着上面的例子,如果要找出那些电影没有库存Id,只需要用Where语句进行过滤
SELECT film.film_id, film.title,inventory_id
FROM film
LEFT OUTER JOIN inventory ON inventory.film_id = film.film_id
WHERE inventory_id IS NULL;
UNION
UNION用来合并多个SELECT的查询结果,将过个set合并成一个set,合并的过程中回去掉重复的row,如果想要保留需要使用UNION ALL
SELECT colunm_1, colunm_2
FROM tbl_name_1
UNION
SELECT colunm_1, column_2
FROM tbl_name_2
UION的一个场景是合并多张表的数据,将数据拼接成一个row,假设有下面一个例子
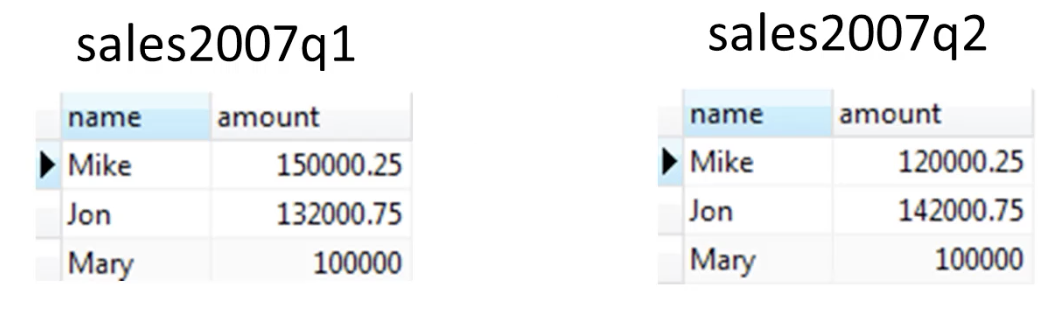
现在想统计每个员工全面的销售总额,因此,需要将几张表的数据进行UNION
SELECT * FROM sales2007q1
UNION ALL
SELECT * FROM sales2007q2
Advanced SQL Commands
- Timestamps
SQL允许在查询时获取timestamp信息,可以通过extract函数提取。例如,想要统计每个月份的支出有多少
SELECT SUM(amount), extract(month from payment_date) AS month
FROM payment
GROUP BY month
ORDER BY SUM(amount);
- Function
- Subquery
Subquery的意思是一个将查询任务分为几个子的查询,例如,要寻找所有rental_rate高于平均rantal_rate的电影,这个任务将分两步:
-
使用SELECT和AVG函数计算平均rental_rate
SELECT AVG(rental_rate) AS avg FROM film; -
将上一步得到的结果作为条件,过滤出rental_rate高于平均值的film
SELECT title,rental_rate FROM film; WHERE rental_rate > 2.92;
Subquery可以让上述两条语句合并成一条,Subquery允许使用括号将条件SQL插入
SELECT title,rental_rate FROM film;
WHERE rental_rate > (SELECT AVG(rental_rate) FROM film;);
- SELF JOIN
SELF JOIN用来在同一个表中找寻符合某种关系的记录,例如,在一个user表中查找所有FIRST_NAME等于LAST_NAME的用户
SELECT a.first_name, a.last_name , b.first_name, b.last_name FROM
customer AS a, customer AS b
WHERE a.first_name = b.last_name;
对于上面的query语句也可以使用JOIN
SELECT a.first_name, a.last_name , b.first_name, b.last_name FROM
customer AS a
INNER JOIN customer AS b
ON a.first_name = b.last_name;
Other SQL Commands
CREATE TABLE
- SQL syntax
CREATE TABLE table_name( colunm_name1 TYPE column_constraint, colunm_name2 TYPE column_constraint, ... table_constraint) - column_constraint
- 每个colunm的限制条件
NOT NULLUNIQUE,该column的值不能重复,但可以是NULLPRIMARY KEY,不空+唯一。如果PRIMARY KEY由多个colunm构成,则要在table constraint中说明CHECK,当插入或更新数据时会自动check是否合法REFERENCES,表示当前colunm也存在于别的表中,表明该column是外键
- table constraint
UNIQUE(column_listPRIMARY KEY(column_list)CHECK(condition)REFERENCES
- INHERITES
- 指定TABLE的继承关系,如果从某个表继承,则当前表有其所有colunm属性
- LIKE
- 拷贝另一个表的schema(不拷贝数据)
<!-- copy schema from link --> CREATE TABLE link_copy (LIKE link); -
Demo
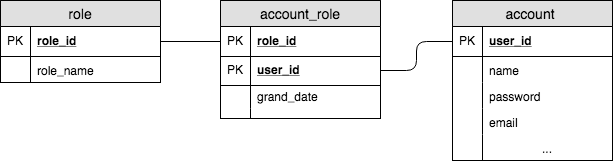
CREATE TABLE account( user_id serial PRIMARY KEY, username VARCHAR(50) UNIQUE NOT NULL, password VARCHAR(50) NOT NULL, email VARCHAR(335) UNIQUE NOT NULL, created_on TIMESTAMP NOT NULL, last_login TIMESTAMP ); CREATE TABLE role( role_id serial PRIMARY KEY, role_name VARCHAR(255) UNIQUE NOT NULL ); CREATE TABLE account_role( user_id integer NOT NULL, role_id integer NOT NULL, grant_date timestamp without time zone, PRIMARY KEY(user_id, role_id), CONSTRAINT account_role_role_id_fKey FOREIGN KEY(role_id) REFERENCES role (role_id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION, CONSTRAINT account_role_user_id_fKey FOREIGN KEY(user_id) REFERENCES account (role_id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION );
INSERT
- syntax
INSERT INTO table(colunm1, colunm2,...)
VALUES(value1, value2,...),
(value1, value2,...);
INSERT INTO table
SELECT colunm1, colunm2,...
FROM another_table
WHERE condition;
- demo
INSERT INTO link(url,name)
VALUES('www.yahoo.com','Yahoo'),
('www.youtube.com','Youtube'),
('www.amazon.com','Amazon');
<!-- Insert value from another table-->
INSERT INTO link_copy
SELECT * FROM link
WHERE name = 'Youtube';
UPDATE
- syntax
UPDATE table
SET colunm1 = value1,
colunm2 = value2, ...
WHERE condition;
- demo
<!-- 更新所有数据的description字段 -->
UPDATE link
SET description = 'Empty Descripiton';
UPDATE link
SET description = name;
UPDATE link
SET description = "An online video platform"
WHERE name='youtube';
<!-- 返回执行结果 -->
UPDATE link
SET description = 'unknown'
WHERE id=1
RETURNING id,url,name,description;
DELETE
- syntax
DELETE FROM table
WHERE condition
- Demo
DELETE FROM link
WHERE id = 1;
<!-- 删除所有数据, 返回被删除数据结果 -->
DELETE FROM link
RETURNING * ;
ALTER TABLE
ALTER TABLE用来修改表结构
- 增加,删除,重命名column
- 给每个column设定默认值
- CHECKT colunm的constraint
- 重命名table
- syntax
ALTER TABLE table
action
- ADD COLUMN
<!-- 增加active字段,类型为boolean -->
ALTER TABLE link
ADD COLUMN active boolean;
- DROP COLUNM
ALTER TABLE link
DROP COLUMN active;
- RENAME
<!-- 重命名某个字段 -->
ALTER TABLE link
RENAME COLUMN title TO title_name;
<!-- 重命名整张表 -->
ALTER TABLE link RENAME TO url_table;
DROP TABLE
- syntax
DROP TABLE IF EXISTS table_name RESTRICT;
CHECK constraint
CHECK用来检查某个colunm的值是否合法
CREATE TABLE new_users(
id serial PRIMARY KEY,
first_name VARCHAR(40),
birth_date DATE CHECK(birth_date > '1900-01-01'),
join_date DATE CHECK(join_date > birth_date),
salary integer CHECK(salary > 0)
);
<!-- 插入一条非法数据 -->
insert into new_users(first_name,birth_date,join_date,salary)
VALUES('Joe','1980-02-01','1994-01-01',-10);
SQL Command CheatSheet