
多线程问题的根源
新年伊始,我们来聊一聊iOS中的多线程问题,准确来说是并发编程的问题。并发编程在各个语言中都是一个很高阶的话题,这方面相关的书籍和教程非常少,其原因在于它是一个非常复杂的问题,想真正的讲清楚它并不容易,涉及到的知识点非常多,而且非常零散,彼此之间的相关度也比较低。从底层的CPU体系结构到操作系统原理再到上层的编程语言,每一个环节都有可能出错,而且错误往往是随机的,没有规律可循。因此想分析清楚一个并发问题,需要将底层知识和上层知识融汇贯通,有时还可能涉及到一点硬件和汇编语言的知识,甚至还要用到一些高级的调试技术,这些都大大提高了学习并发编程的门槛。
并发问题的根源
如果从硬件的角度来看,并发问题的根源实际上是CPU,内存,I/O这三者读写速度的的差异。这个矛盾一直存在但往往却被我们所忽视。为了平衡这三者之间的速度差异,计算机体系结构,操作系统以及编译原理均作出各自的贡献,主要体现为:
- CPU增加了高速缓存,以均衡与内存读写速度的差异。读写内存和高速缓存的时间差距是两个数量级,例如读一次缓存需要0.5ns,而读一次内存可能要50ns。
- 操作系统增加了进程,线程,分时复用等技术用来均衡CPU和I/O设备的速度差异
- 编译技术优化指令的执行次序,使得缓存可以得到更加合理的利用
这些技术虽然极大的提升了程序的运行效率,却也带来了很多诡异的问题,具体来说可以分为三类,分别是可见性问题,原子性问题和有序性问题,搞清楚这些问题是解决并发问题的根源
可见性问题
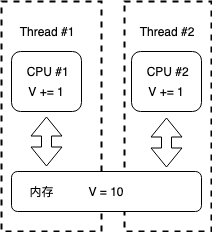
在单核时代,所有线程都在同一颗CPU上执行,CPU的缓存与内存的数据一致性容易解决。因为所有线程并不是真正的并行执行,本质上还都是串行的(依靠CPU的时间片轮询),因此它们实际上是对同一个CPU缓存进行操作,一个线程对缓存的写操作对另一个线程来说是可见的。但是到了多核时代,每颗CPU都有自己的缓存,这时CPU与内存的数据一致性就会有问题。当多个线程在不同CPU上执行时,它们操作的是不同CPU的缓存,对于同一份内存数据,线程1的操作的是CPU#1的缓存,线程2操作的是CPU#2的缓存,它们对各自数据的修改对彼此不可见的。如下图中,#1线程操作的是CPU#1的寄存器,#2线程操作的是CPU#2的寄存器,这时线程#1对变量V的操作对线程#2来说就不具备可见性了,这会带来什么结果呢?由于两个线程的时序性,变量V的最终结果可能是不确定的,比如线程#1和线程#2在并发时都将V=10从内存读入到了各自的CPU寄存器中,线程#1先在执行了V+1,然后将V=11写入到了内存中,而此时线程#2也完成了V+1的计算,也将V=11写入内存,这样V的值就被覆盖,最终得到了错误的结果。
为了更好的理解多核CPU的可见性问题,我们可看下面的例子。在下面代码中,我们并发了两个线程,每个线程执行add10k()方法,该方法会循环10k次self.data+1操作。当两个线程均执行完毕后,我们来观察self.data的值
@property(nonatomic,assign) int data;
- (void)add10K {
int idx = 0;
while( idx++ < 10000 ){
self.data += 1;
}
}
- (void)calculate {
self.data = 0;
dispatch_group_t group = dispatch_group_create();
//run task #1
dispatch_group_enter(group);
dispatch_async( dispatch_get_global_queue( 0, 0 ), ^{
[self add10K];
dispatch_group_leave(group);
} );
//run task #2
dispatch_group_enter(group);
dispatch_async( dispatch_get_global_queue( 0, 0 ), ^{
[self add10K];
dispatch_group_leave(group);
} );
//sychronization point
dispatch_group_notify( group, dispatch_get_main_queue(), ^{
NSLog( @"data: %d", self.data );
} );
}
运行上述代码,我们得到data的值是一个10000-20000之间的随机数,而不是我们直觉上认为的20000。其原因就在于这两个线程会在各自的CPU中计算self.data,并将结果以互相覆盖的方式写入内存。