
ARM32的汇编基础
ARM基础
ARM的寄存器
r0 - r3 : 存放函数的传参
r4 - r11 : 存放局部变量
r7 (FP) : frame pointer,通常用来保存之前的sp和lr
r12 : 通用寄存器
r13 (SP) : stack pointer ,栈底指针,很重要
r14 (LR) : link register ,保存下一条指令地址
r15 (PC) : program counter,存放当前指令的地址,当指令执行完后,会自增加
常用的汇编指令
mov r0, r1 => r0 = r1
mov r0, #10 => r0 = 10
ldr r0, [sp] => r0 = *sp
str r0, [sp] => *sp = r0
add r0, r1, r2 =>r0 = r1 + r2
add r0, r1 => r0 = r0 + r1
push {r0, r1, r2} => Push r0, r1 and r2 onto the stack.
pop {r0, r1, r2} => Pop three values off the stack, putting them into r0, r1 and r2.
b _label =>pc = _label
bl _label =>lr = pc + 4; pc = _label
Stack frame
函数调用是基于stack的,stack是从高到低生长的,假如函数A内部要调用B,首先要将A的sp存起来,然后在stack上开辟一块空间,执行B,B执行完后在将sp取出来继续执行。整个过程如下图:
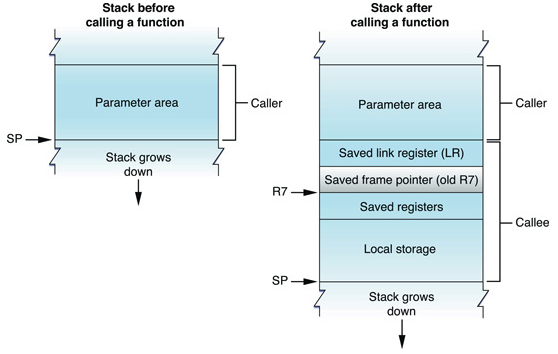
- Parameter area
存放了B(callee)函数需要的参数,这一块空间需要由A来分配(caller),这个过程叫做prologue。prologue通常做下面几件事
- 将staci pointer和frame pointer入栈,对应图中的LR,R7
- 将SP赋给R7
- 保存当前寄存器的值
- 分配空间给B函数
- linkage area 用来存放A在调用完B后下一条指令的地址
- saved frame pointer 用来存放了A调用B前的SP地址
- local storage area 用来存放函数B需要的参数
通常来说,prologue不属于汇编本身,它的代码相对固定,不同的平台有不同的convention,因此产生prologue的代码也不同。
Assembly指令分析
查看下面代码
__attribute__((noinline))int addFunction(int a, int b) {
int c = a + b;
return c;
}
void fooFunction() {
int add = addFunction(50, 51);
printf("add = %i", add);
}
其汇编指令为
.globl _fooFunction
.align 2
.code 16 @ @fooFunction
.thumb_func _fooFunction
_fooFunction:
.cfi_startproc
Lfunc_begin1:
.loc 1 19 0
@ BB#0:
push {r7, lr}
mov r7, sp
sub sp, #12
movs r0, #50
movt r0, #0
movs r1, #51
movt r1, #0
.loc 1 20 0 prologue_end
Ltmp2:
bl _addFunction
movw r1, :lower16:(L_.str-(LPC1_0+4))
movt r1, :upper16:(L_.str-(LPC1_0+4))
LPC1_0:
add r1, pc
str r0, [sp, #8]
.loc 1 21 0
ldr r0, [sp, #8]
str r0, [sp, #4] @ 4-byte Spill
mov r0, r1
ldr r1, [sp, #4] @ 4-byte Reload
bl _printf
.loc 1 22 0
str r0, [sp] @ 4-byte Spill
add sp, #12
pop {r7, pc}
Ltmp3:
Lfunc_end1:
.cfi_endproc
头信息
我们先来看头信息,所谓的头信息也叫ARM Machine Directives:
.globl _fooFunction
.align 2
.code 16 @ @fooFunction
.thumb_func _fooFunction
_fooFunction:
.cfi_startproc
.globl声明的符号为外部符号,外部符号是.c或.m中可见的符号,_fooFunction为fooFunction()方法。.align 2代表后面的代码会以2的平方=4字节对齐,没有padding.code 16意思是下面的汇编指令集是Thumb的不是ARM的(32)。现代的ARM处理器有两种模式:ARM和Thumb,ARM是32bit宽,Thumb是16bit宽,Thumb的指令很少,使用Thumb模式,通常会使代码量更小,和更有效的CPU缓存- .thumb_func 意思是告诉后面的_fooFunction中的指令是用Thumb编码的
labels
接下来就是_fooFunction的内容,在汇编中,以冒号为结尾的行,如_fooFunction: ,Lfunc_begin1: ,Ltmp3:,Ltmp4:,Lfunc_end1 称为Labels
用来标识一段汇编代码的名字,为某段代码的入口地址,例如:_fooFunction:是函数的入口位置。
程序中可以call 这些label,来执行函数。
用_开头的是函数入口的label,用L开头的是函数中的内部跳转位置,包含在函数内部。
注释是以@开头。
一般函数开头都会以.cfi_startproc开始。cfi是call frame information的缩写。
我们继续:
Lfunc_begin1:
.loc 1 19 0
@ BB#0:
push {r7, lr}
mov r7, sp
sub sp, #12
movs r0, #50
movt r0, #0
movs r1, #51
movt r1, #0
.loc 1 20 0 prologue_end
Ltmp2:
bl _addFunction
这一段也很好理解: 记得前面第三点讨论的内容,在_fooFunction的stack中,首先的一段应该是Parameter Area。也就是眼前的这一段,根据规定,这一段stack需要由_fooFunction分配出来,保存它要调用的addFunction(50,51)的入参,这一过程成为prologs。
prologs的第一步便是:将R7和LR入栈:push{r7,lr}。由于r7和lr都是32bit,4byte,因此sp会自动减少8字节,此句相当于
str r7, [sp, #8]
str lr , [sp, #4]
mov r7, sp :由于上一步r7中的值已经保存到栈里了,因此现在可以用r7来保存当前sp的地址。 sub sp, #12:从sp当前地址,向下开辟12字节的空间,其中前8个字节用来存放r7和lr的值
movs r0, #50
movt r0, #0
movs r1, #51
movt r1, #0
.loc 1 20 0 prologue_end
然后将传入的参数50,51分别放到寄存器r0,r1中:r0,r1均为32bit宽,movt将高16bit填充为0. 最后是prolog过程结束,到此为止,caller的任务就完成了。 bl _addFunction:bl(branch with link)用来执行函数调用,属于Thumb指令集。显然下面就去进入addFunction的函数栈了。
我们先不管addFunction,假设现在addFunction已经执行完了,返回值保存在了r0中。
movw r1, :lower16:(L_.str-(LPC1_0+4))
movt r1, :upper16:(L_.str-(LPC1_0+4))
LPC1_0:
add r1, pc
str r0, [sp, #8]
.loc 1 21 0
ldr r0, [sp, #8]
str r0, [sp, #4] @ 4-byte Spill
mov r0, r1
ldr r1, [sp, #4] @ 4-byte Reload
bl _printf
前两句是把”add = %i”这个字符串放到r1中,其中L_.str定义在了常量段:
.section __TEXT,__cstring,cstring_literals
L_.str: @ @.str
.asciz "add = %i"
然后先把r0中的值保存到stack上(sp + 4)的位置,再把r1中的”add = %i”放到r0中,最后再把(sp + 4)中的值存到r1中。 这个过程很冗余,我们为了看起来更详细,用了Testing模式,如果是Archiving模式,则这段代码会被优化掉。
这是,调用printf的参数在寄存器中就准备好了。接下来bl printf
str r0, [sp] @ 4-byte Spill
add sp, #12
pop {r7, pc}
最后是一个出栈的过程,由于之前sp减掉了12字节,现在要加回来。
然后我们再来分析addFunction函数内部的调用过程:
.globl _addFunction
.align 2
.code 16 @ @addFunction
.thumb_func _addFunction
_addFunction:
.cfi_startproc
Lfunc_begin0:
.loc 1 14 0
@ BB#0:
sub sp, #12
str r0, [sp, #8]
str r1, [sp, #4]
.loc 1 15 0 prologue_end
Ltmp0:
ldr r0, [sp, #8]
ldr r1, [sp, #4]
add r0, r1
str r0, [sp]
.loc 1 16 0
ldr r0, [sp]
add sp, #12
bx lr
Ltmp1:
Lfunc_end0:
.cfi_endproc
sub sp, #12 : 为addFunction开辟12字节空间 str r0, [sp, #8] : 把r0的值放到sp+8的位置,r0里保存的是50 str r1, [sp, #4] : 把r1的值放到sp+4的位置,r1里保存的是51 ldr r0, [sp, #8] : 把sp+8中存放的值再放回r0中 ldr r1, [sp, #4] : 把sp+4中存放的值再放回r1中
同样这四步冗余的代码会被编译器优化掉。
add r0, r1 : 计算r0 + r1将结果放回r0 str r0, [sp] : 把r0保存在sp+0的位置 ldr r0, [sp] : 把r0在load回来 add sp, #12 : 还原stack pointer的位置,由于之前向下开辟了12字节的空间,现在需要还原回去。 bx lr : 执行下面一条指令,此时lr中存的值为_fooFunction的地址。
这样,整段汇编指令就全部分析完成了,但是相信不是所有人都看的明白,而且仅靠逻辑分析显然不够直观,下面我们用LLDB亲自调试一下。
Debug with LLDB
我们首先在fooFunction入口处打一个断断点:
然后用真机调试程序,停在断点处:
这时,我们先用bt查看当前线程的stack frame:
tid = 0x1bf859, 0x000eab5e ARMAssembly`fooFunction + 18 at main.m:20, queue = 'com.apple.main-thread, stop reason = breakpoint 2.1
frame #0: 0x000eab5e ARMAssembly`fooFunction + 18 at main.m:20
frame #1: 0x000eab8e ARMAssembly`main(argc=1, argv=0x27d1fcfc) + 14 at main.m:26
其中,frame #0: 0x000eab5e这个值就是 _fooFunction的入口地址。
然后我们再register read一下:
General Purpose Registers: r0 = 0x00000032 r1 = 0x00000033 r2 = 0x27d1fd04 r3 = 0x27d1fd30 r4 = 0x00000000 r5 = 0x000eab81 ARMAssembly`main + 1 at main.m:25 r6 = 0x00000000 r7 = 0x27d1fcc8 r8 = 0x27d1fcf4 r9 = 0x3b347e30 r10 = 0x00000000 r11 = 0x00000000 r12 = 0x80000028 sp = 0x27d1fcbc lr = 0x000eab8f ARMAssembly`main + 15 at main.m:26 pc = 0x000eab5e ARMAssembly`fooFunction + 18 at main.m:20 cpsr = 0x20000030
如图所示,r0,r1填好了入参50,51,sp指向栈底,lr指向下一条函数的入口地址
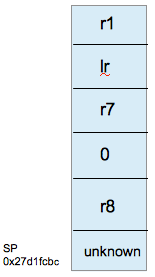
好了,下面我们来分析stack:memory read/6xw 0x27d1fcbc从当前sp的位置向上6*4 = 24字节:
0x27d1fcbc: 0x2be8c384 0x27d1fcf4 0x00000000 0x27d1fcd8
0x27d1fccc: 0x000eab8f 0x27d1fcfc
此时的stack frame如右图所示:我们看到,lr和r7已经入栈。
一切准备就绪!接下来,我们执行addFunction:

再bt
* thread #1: tid = 0x1bf859, 0x000eab3e ARMAssembly`addFunction(a=50, b=51) + 6 at main.m:15, queue = 'com.apple.main-thread, stop reason = breakpoint 1.1
frame #0: 0x000eab3e ARMAssembly`addFunction(a=50, b=51) + 6 at main.m:15
frame #1: 0x000eab62 ARMAssembly`fooFunction + 22 at main.m:20
frame #2: 0x000eab8e ARMAssembly`main(argc=1, argv=0x27d1fcfc) + 14 at main.m:26
我们看到多了一个frame是addFunction,此外,每个function的入口地址也发生了变化,这意味着lr中的地址也会相应发生变化!
同样,我们再看一遍寄存器:register read
General Purpose Registers:
r0 = 0x00000032
r1 = 0x00000033
r2 = 0x27d1fd04
r3 = 0x27d1fd30
r4 = 0x00000000
r5 = 0x000eab81 ARMAssembly`main + 1 at main.m:25
r6 = 0x00000000
r7 = 0x27d1fcc8
r8 = 0x27d1fcf4
r9 = 0x3b347e30
r10 = 0x00000000
r11 = 0x00000000
r12 = 0x80000028
sp = 0x27d1fcb0
lr = 0x000eab63 ARMAssembly`fooFunction + 23 at main.m:20
pc = 0x000eab3e ARMAssembly`addFunction + 6 at main.m:15
cpsr = 0x20000030
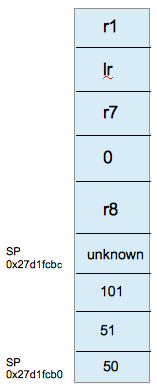
此时,r0,r1为入参,sp指向栈底,当前sp位置为0x27d1fcb0,和上图中的位置正好相差12字节!这12字节也就是addFunction的stack frame。此时lr指向了下一条函数入口:fooFunction。值为:0x000eab63,比我们bt出来的0x000eab62多一个字节。因为lr永远指向下一条函数入口地址的下一个字节。
好了我们看看此时的栈的情况 memory read/3xw 0x27d1fcb0:从栈底向上12字节,如图所示:每一个4字节单元保存了具体运算的数值,对照我们之前的分析,完全吻合。
后面的过程,我们便可以依此方法去观察寄存器和stack情况,来印证我们上文的分析。
(全文完)