
聊一聊Linkers和Loaders
今天开始我们来讨论下C/C++程序的链接,加载和执行,我们将把重点放在目标文件的链接和加载上。
一般来说,源文件编译完成后会生成.o文件,多个.o文件和一些lib,一起link得到可执行文件,下面是GCC的一些常用编译选项,我们稍后会用到:
-c: 用来生成.o文件-o: 用来创建目标文件-g: 编译器在输出文件中包含debug信息,产生dSYM符号表-Wall:编译器编译时打出warning信息,强烈推荐使用这个选项。-I+dir: 除了在main.c当前目录和系统默认目录中寻找.h外,还在dir目录寻找,注意,dir是一个绝对路径。-01,-02,-03: 编译器优化程度
如果使用macOS,gcc实际上是Clang的alias,binary的结构为Mach-O,而不是UNIX的ELF格式,不过这并不影响理解本文的内容
Object Files
我们先从最基本的目标文件开始分析,现在假设我们有三个文件:function.h,function.m和main.c,代码如下
//function.h
#define FIRST_OPTION
#ifdef FIRST_OPTION
#define MULTIPLIER (3.0)
#else
#define MULTIPLIER (2.0)
#endif
float add_and_multiply(float x, float y);
//function.c
#include "function.h"
int nCompletionStatus = 0;
float add(float x, float y) {
float z = x+y;
return z;
}
float add_and_multiply(float x, float y){
float z = add(x,y);
z *= MULTIPLIER;
return z;
}
//main.c
#include "function.h"
extern int nCompletionStatus;
int main() {
float x = 1.0;
float y = 1.5;
float z;
z = add_and_multiply(x,y);
nCompletionStatus = 1;
return 0;
}
为了生成目标文件.o,我们可以使用gcc对上述源码进行编译
gcc -c function.c
gcc -c main.c
执行上面两行命令后,我们可以得到function.o和main.o。接下来我们来简单的分析一下目标文件的格式以及里面所包含的内容,在UNIX环境中,我们可以使用下面的工具帮助我们分析
- nm: 显示目标文件中的symbol列表
- objdump: 提供了一系列选项可以最目标文件做比较详细的分析,比如
-S选项可以dump出汇编代码 - readelf: 读取并显示ELF格式文件的信息
以function.o为例,使用readelf -a function.o
readelf -a function.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 808 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 9
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
000000000000006a 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 00000280
0000000000000018 0000000000000018 I 10 1 8
[ 3] .data PROGBITS 0000000000000000 000000aa
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .bss NOBITS 0000000000000000 000000ac
0000000000000004 0000000000000000 WA 0 0 4
[ 5] .comment PROGBITS 0000000000000000 000000ac
0000000000000036 0000000000000001 MS 0 0 1
[ 6] .note.GNU-stack PROGBITS 0000000000000000 000000e2
0000000000000000 0000000000000000 0 0 1
[ 7] .eh_frame PROGBITS 0000000000000000 000000e8
0000000000000058 0000000000000000 A 0 0 8
[ 8] .rela.eh_frame RELA 0000000000000000 00000298
0000000000000030 0000000000000018 I 10 7 8
[ 9] .shstrtab STRTAB 0000000000000000 000002c8
0000000000000059 0000000000000000 0 0 1
[10] .symtab SYMTAB 0000000000000000 00000140
0000000000000108 0000000000000018 11 8 8
[11] .strtab STRTAB 0000000000000000 00000248
0000000000000033 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), l (large)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
There are no section groups in this file.
There are no program headers in this file.
Relocation section '.rela.text' at offset 0x280 contains 1 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000004a 000900000002 R_X86_64_PC32 0000000000000000 add - 4
Relocation section '.rela.eh_frame' at offset 0x298 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
000000000040 000200000002 R_X86_64_PC32 0000000000000000 .text + 24
The decoding of unwind sections for machine type Advanced Micro Devices X86-64 is not currently supported.
Symbol table '.symtab' contains 11 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS function.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 6
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 5
8: 0000000000000000 4 OBJECT GLOBAL DEFAULT 4 nCompletionStatus
9: 0000000000000000 36 FUNC GLOBAL DEFAULT 1 add
10: 0000000000000024 70 FUNC GLOBAL DEFAULT 1 add_and_multiply
上述命令给出了function.o中一些比较关键的信息,比如第一段的文件描述,第二段的section header信息,以及后面的重定位表和符号表等等。如果我们只要分析linker和loader,那么我们暂时不需要理解全部的内容,但是需要特别关注一些重要的section。实际上对于每个section,它们都是一个有起始实地址和固定长度构成的一段连续空间。其中,有四个section需要特别关注
.text段,也叫代码段,用来存放汇编指令.data段,也叫数据段,用来保存程序里设置好的初始化数据信息.rela.text段,叫做重定位表(Relocation Table)。在表里,保存了所有未知跳转的指令.symtab段,也叫做符号表,用来存放当前文件里定义的函数和对应的地址
Linkers
在有了编译生成的.o文件后,Linker要做的事情就是将这些文件link在一起,具体来说过程如下,linker会扫描所有的目标文件,将所有符号表中的信息收集起来,构成一个全局的符号表,然后再根据重定位表,把所有不确定的跳转指令根据符号表里地址,进行一次修正。最后,把所有的目标文件的section分别进行合并,形成最终的可执行代码。对于前面的例子,我们有两个目标文件,linker的过程如下图所示
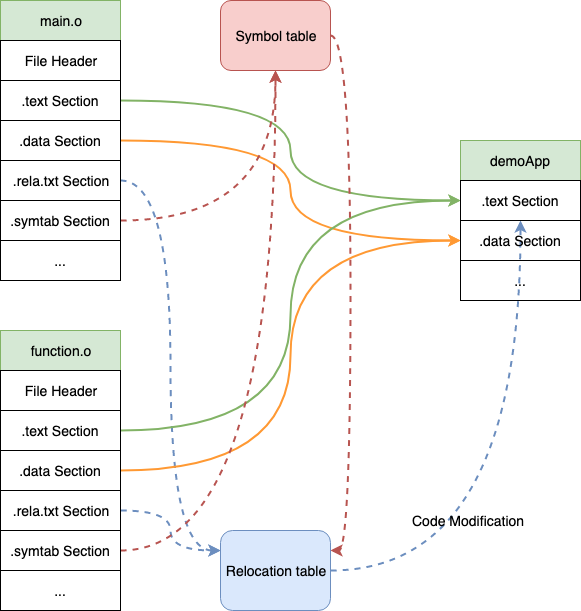
如果将上述步骤分解开来,则linker的执行步骤可大致分为两部分:符号解析(Symbol Resolution)和地址绑定(Relocation)
符号解析(Symbol Resolution)
我们可以使用前面提到的nm命令来快速看一下function.o和main.o中都有哪些symbol
#function.o
0000000000000000 T add
0000000000000024 T add_and_multiply
0000000000000000 B nCompletionStatus
#main.o
U add_and_multiply
0000000000000000 T main
U nCompletionStatus
通过观察上面的符号表,可以发现
-
每个符号都有自己的类型。比如在
main.o中,由于add_and_multiply是定义在另一个目标文件中,因此对于main.o来说,编译器并不知道这个符号在哪里,因此用U表示。nCompletionStatus同理。而对于function.o来说,这两个函数就定义在自身的目标文件中,编译器是知道它们的位置的,因此用T和B表示。更多关于符号的含义可参考文末的附录。 -
每个符号都有自己的地址。它们的地址都是相对于该目标文件的偏移,并不是虚拟内存中的地址。我们可以通过观察汇编代码来进一步验证,使用
objdump -d function.o得到function.o的汇编代码如下
Disassembly of section .text:
0000000000000000 <add>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: f3 0f 11 45 ec movss %xmm0,-0x14(%rbp)
9: f3 0f 11 4d e8 movss %xmm1,-0x18(%rbp)
e: f3 0f 10 45 ec movss -0x14(%rbp),%xmm0
13: f3 0f 58 45 e8 addss -0x18(%rbp),%xmm0
18: f3 0f 11 45 fc movss %xmm0,-0x4(%rbp)
1d: f3 0f 10 45 fc movss -0x4(%rbp),%xmm0
22: 5d pop %rbp
23: c3 retq
0000000000000024 <add_and_multiply>:
24: 55 push %rbp
25: 48 89 e5 mov %rsp,%rbp
28: 48 83 ec 20 sub $0x20,%rsp
2c: f3 0f 11 45 ec movss %xmm0,-0x14(%rbp)
31: f3 0f 11 4d e8 movss %xmm1,-0x18(%rbp)
36: f3 0f 10 45 e8 movss -0x18(%rbp),%xmm0
3b: 8b 45 ec mov -0x14(%rbp),%eax
3e: 0f 28 c8 movaps %xmm0,%xmm1
41: 89 45 e4 mov %eax,-0x1c(%rbp)
44: f3 0f 10 45 e4 movss -0x1c(%rbp),%xmm0
49: e8 00 00 00 00 callq 4e <add_and_multiply+0x2a>
4e: 66 0f 7e c0 movd %xmm0,%eax
52: 89 45 fc mov %eax,-0x4(%rbp)
55: f3 0f 10 45 fc movss -0x4(%rbp),%xmm0
5a: f3 0f 58 c0 addss %xmm0,%xmm0
5e: f3 0f 11 45 fc movss %xmm0,-0x4(%rbp)
63: f3 0f 10 45 fc movss -0x4(%rbp),%xmm0
68: c9 leaveq
69: c3 retq
因此可以猜想,linker接下来要做的事情就是将所有Undefined符号进行地址绑定(动态库中的符号暂不考虑)以及算出每个符号在虚拟内存中的真实地址
Relocation
Section的Relocation很简单,就是将所有目标文件的各个段按照某种规则进行合并,比如上面图中的,text段合并,符号表合并等等。在合并的过程中,需要计算每个段在实际虚拟内存中的地址,比如前面提到的main.o中的main符号的地址为0x0000000000000000,function.o中add地址也为0x0000000000000000。显然,在实际的内存中,不管是add还是main的地址是不可能为0x0000000000000000的。这时候就需要Relocation发挥作用,将所有section的地址重新分配到合理的位置。但需要注意的是,在分配的过程中要保证每个Section的连续性不被破坏,因此linker是需要知道每个section的大小和范围。
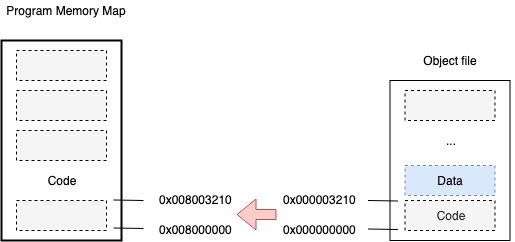
下面我们来通过观察汇编代码来具体看一下是上述过程,我们还是使用objdump命令来反汇编目标文件
objdump -d -S main.o
main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 main:
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 48 83 ec 20 sub rsp,0x20
8: f3 0f 10 05 00 00 00 movss xmm0,DWORD PTR [rip+0x0] # 10 <main+0x10>
f: 00
10: f3 0f 11 45 f4 movss DWORD PTR [rbp-0xc],xmm0
15: f3 0f 10 05 00 00 00 movss xmm0,DWORD PTR [rip+0x0] # 1d <main+0x1d>
1c: 00
1d: f3 0f 11 45 f8 movss DWORD PTR [rbp-0x8],xmm0
22: f3 0f 10 45 f8 movss xmm0,DWORD PTR [rbp-0x8]
27: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]
2a: 0f 28 c8 movaps xmm1,xmm0
2d: 89 45 ec mov DWORD PTR [rbp-0x14],eax
30: f3 0f 10 45 ec movss xmm0,DWORD PTR [rbp-0x14]
35: e8 00 00 00 00 call 3a <main+0x3a>
3a: 66 0f 7e c0 movd eax,xmm0
3e: 89 45 fc mov DWORD PTR [rbp-0x4],eax
41: c7 05 00 00 00 00 01 mov DWORD PTR [rip+0x0],0x1 # 4b <main+0x4b>
48: 00 00 00
4b: b8 00 00 00 00 mov eax,0x0
50: c9 leave
51: c3 ret
上述是main函数的汇编指令,我们发现在第#35行,有一个call的指令,参考main函数的源码可知,这个指令是用来调用add_and_multiply函数的,但是由于这个.o中_add_and_multiply符号未知,call变成调用自己,显然是不正确的。因此,我们可以猜想在最终的binary中,这行指令应该会发生变化,linker会对符号进行解析和地址绑定。
$gcc function.c mian.c -o demoApp
$objdump -D demoApp
0000000000400540 main:
400540: 55 push rbp
400541: 48 89 e5 mov rbp,rsp
400544: 48 83 ec 20 sub rsp,0x20
400548: f3 0f 10 05 d4 00 00 movss xmm0,DWORD PTR [rip+0xd4] # 400624 <_IO_stdin_used+0x4>
40054f: 00
400550: f3 0f 11 45 f4 movss DWORD PTR [rbp-0xc],xmm0
400555: f3 0f 10 05 cb 00 00 movss xmm0,DWORD PTR [rip+0xcb] # 400628 <_IO_stdin_used+0x8>
40055c: 00
40055d: f3 0f 11 45 f8 movss DWORD PTR [rbp-0x8],xmm0
400562: f3 0f 10 45 f8 movss xmm0,DWORD PTR [rbp-0x8]
400567: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]
40056a: 0f 28 c8 movaps xmm1,xmm0
40056d: 89 45 ec mov DWORD PTR [rbp-0x14],eax
400570: f3 0f 10 45 ec movss xmm0,DWORD PTR [rbp-0x14]
400575: e8 80 ff ff ff call 4004fa add_and_multiply
40057a: 66 0f 7e c0 movd eax,xmm0
40057e: 89 45 fc mov DWORD PTR [rbp-0x4],eax
400581: c7 05 a9 0a 20 00 01 mov DWORD PTR [rip+0x200aa9],0x1 # 601034 <nCompletionStatus>
400588: 00 00 00
40058b: b8 00 00 00 00 mov eax,0x0
400590: c9 leave
400591: c3 ret
400592: 66 2e 0f 1f 84 00 00 nop WORD PTR cs:[rax+rax*1+0x0]
400599: 00 00 00
40059c: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
对比两段汇编代码,不难发现,前者的BaseAddress是0000000000000000,每条汇编指令前面的数字是该指令的offset。而后者的BaseAddreess变成了0000000000400540,说明Linker对每个目标文件的汇编指令做了地址修正,另外,call指令后的符号变成了我们期望的函数符号add_and_multiply,地址为4004fa。说明Linker完成的符号和地址的绑定。
00000000004004fa <add_and_multiply>:
4004fa: 55 push rbp
4004fb: 48 89 e5 mov rbp,rsp
...
40051a: f3 0f 10 45 e4 movss xmm0,DWORD PTR [rbp-0x1c]
40051f: e8 b2 ff ff ff call 4004d6 <add>
400524: 66 0f 7e c0 movd eax,xmm0
...
40053e: c9 leave
40053f: c3 ret
另一关于Code Modification比较好的例子是Linkers and loaders这本书中的例子,假设某个目标文件在编译完后有下面x86的一段汇编代码
A1 34 12 00 00 mov a, %eax
A3 00 00 00 00 mov %eax, b
这两行代码的意思是将a中的值通过寄存器赋值给b。其中每行指令由一个opcode + 4字节的地址组成,由于a位于该目标文件内,地址为0x1234,由于x86使用的是right-to-left order,因此a的地址表示为34 12 00 00。b是一个import进来的变量,在编译时,编译器并不知道b在哪里,因此地址为00 00 00 00 。
当link完成后,假设a所在的text段的偏移量为0x1000,因此a的地址变成了0x11234而b所在的地址为0x9A12,则上述两条指令会被linker改写为
A1 34 12 10 00 mov a, %eax
A3 12 9A 00 00 mov %eax, b
当Relocation完成后,每个section和symbol的虚拟内存地址也就确定了,至此linker的任务也就完成了。
Loaders
现在我们已经有了一个link好的binary文件了,当我们执行它的时候,Loader会将binary中的section按照一定规则加载到内存中。实际上Loader的工作就这么简单,但是所谓的“一定规则”确又很复杂,具体来说Loader面临的挑战主要是如何为每个可执行文件找到一片连续的内存空间。解决这个问题有两个办法,一个是使用内存分段,一个是使用内存分页
Segmentation
内存分段的思路很简单,就是找出一段连续的物理内存,然后和虚拟内存进行映射得到虚拟内存地址,再将这个地址分给被load的binary。这种思路虽然简单,但有一个很大的问题就是内存碎片。如下图所示,当C程序退出后,释放的128MB内存成了不连续的空间,当有loader要加载D程序时,会发现没有足够的连续内存空间可以使用。

解决这个问题,可以使用内存的置换技术,即将程序B先写入到硬盘,释放内存空间来装在D,当D装载完成后,再将B读入到内存中。但是由于内存置换的成本极高,硬盘访问的速度要比内存慢太多,因此这种方案有很大的性能问题。
Paging
为了解决内存碎片和交换问题,现代操作系统采用了内存分页的技术。它将物理内存和虚拟内存均切分成4KB大小的一页。由于数据量小,这种切分带来的好处在于内存置换的成本变低了。
getconf PAGE_SIZE #4096
进一步讲,当程序加载时,loader不需要将程序一次性加载到物理内存中,而是可以按需加载,当需要用到虚拟内存里的指令和数据时,操作系统触发CPU的缺页错误,然后触发加载虚拟内存中的页到物理内存。
这并不是说一段连续完整程序可以被零散的映射物理内存中,程序的寻址空间在内存中依旧是一段连续的区域,只不过当出现内存碎片或者物理内存不足时,系统进行内存置换的成本变小了(因为置换现在是以4KB为单位,速度变快了)。如下图中,当程序A试图加载第三片虚拟内存到物理内存中时,会触发系统的内存置换
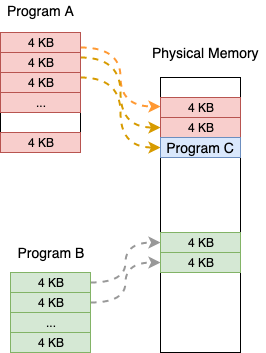
总的来说loader可以将程序和物理内存隔离开,让程序不需要考虑实际的物理内存地址,大小和分配方案,大大降低了程序编写复杂度。
Executable
当loader将程序完全加载到内存中后,程序就可以运行了。如果从C/C++程序的角度看,那么程序的入口应该就是main函数,而如果从loaders的角度看,则在main函数执行之前程序就已经start了。我们还是通过反汇编上面的demoApp来观察
注意,这里的
demoApp依旧是ELF格式
Disassembly of section .text:
00000000004003e0 <_start>:
4003e0: 31 ed xor %ebp,%ebp
4003e2: 49 89 d1 mov %rdx,%r9
4003e5: 5e pop %rsi
4003e6: 48 89 e2 mov %rsp,%rdx
4003e9: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
4003ed: 50 push %rax
4003ee: 54 push %rsp
4003ef: 49 c7 c0 10 06 40 00 mov $0x400610,%r8
4003f6: 48 c7 c1 a0 05 40 00 mov $0x4005a0,%rcx
4003fd: 48 c7 c7 40 05 40 00 mov $0x400540,%rdi
400404: e8 b7 ff ff ff callq 4003c0 <__libc_start_main@plt>
400409: f4 hlt
40040a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
我们看到代码段(text section)的第一个函数是_start,这个函数最后又调用了__libc_start_main函数。我们先看看这个函数的原型
int __libc_start_main(
int *(main) (int, char * *, char * *), /* address of main function */
int argc,
char * * ubp_av,
void (*init) (void), /* address of init function */
void (*fini) (void),
void (*rtld_fini) (void),
void (* stack_end));
这个函数的定义在libc中,由于篇幅有限,源码就不展开分析了,但是我们可以大致猜到它的作用,即初始化程序进程中的环境变量,为main函数的执行做准备,比如某个类的构造函数使用了__attribute__((constructor))这种keyword,那么在main函数执行前,自定义的初始化逻辑将被执行。
小结
到目前为止,我们已经对linkers和loaders有了一些直观的感觉,当然这些感觉还很表面,很多细节问题还不是很清楚,比如Symbol Resolution的具体过程是怎样的,Relocation时偏移地址是如何计算的,动态库是如何加载的,等等。我们将在后面逐步讨论这些问题
Resources
注意,
nm命令不会列出DLL的entry point,除非有和它关联的符号表。
- A :absolute symbol, global
- a :absolute symbol, local
- B :uninitialized data (bss), global
- b :uninitialized data (bss), local
- D :initialized data, global
- d :initialized data, local
- F :file name
- l :line number entry (see -a option)
- N :no defined type, global; this is an unspecified type, compared to the undefined type U
- n :no defined type, local; this is an unspecified type, compared to the undefined type U
- S :section symbol, global
- s :section symbol, local
- T :text symbol, global
- t :text symbol, local (static)
- U :undefined symbol
- ? :unknown symbol