
LLVM IR (1)
我们知道通过编译器生成的中间代码(IR)可以帮助我们更好的做代码优化和代码分析,比如可以针对不同的硬件平台生成不同的汇编代码,或者分析代码的覆盖率等等。今天我们来学习一下LLVM中IR
IR概述
IR处于高级语言和汇编语言之间,可以理解为是高级一点的汇编语言,这也意味着IR具备两种语言的特征。与高级语言相比,IR没有循环语句,条件判断,更没有面向对象之类的设计。与汇编语言相比,IR又没有琐碎的,与硬件相关的细节,比如寄存器名称等等。在IR中我们可以
- 使用寄存器,但是寄存器数量没有限制
- 控制结构跟汇编比较像,比如有跳转语句,用标签来标识程序块
- 具有类似汇编的操作码,这些操作码可以对应到具体平台的汇编操作码,有时IR的一个操作码可以对应多个汇编操作码
LLVM中的IR使用所谓的三地址码,即每条指令最多有三个地址,两个源地址,一个目标地址,每条代码最多有一个op。如下面代码,左边是源代码,右边是对应的三地址码伪码
int a, b, c, d;
a = b + c * d;
t1 := c * d
a := b + t1
上述代码中,由于a = b+c*d超过了三地址码的约定,因此被break down成两条三地址码指令,并引入了中间变量t1。再来看几个例子
int a, b c;
if (a < b )
c = b;
else
c = a;
c = c * 2;
t1 := a < b;
IfZ t1 Goto L1;
c := a;
Goto L2;
L1:
c := b;
L2:
c := c * 2;
int a, b;
while (a < b){
a = a + 1;
}
a = a + b;
L1:
t1 := a < b;
IfZ t1 Goto L2;
a := a + 1;
Goto L1;
L2:
a := a + b;
上述两段代码中,左边是if语句,IR翻译为IfZ,含义为if zero,表示检查后面的操作数是否为0。右边的是循环语句,IR中采用label + Goto的方式实现,其中Goto可理解为x86-64汇编中的jmp。
上面的IR看起来更像是学习算法时候的伪代码,当然实际的LLVM的IR比上述代码要复杂,每条指令包涵的信息也更多。我们用LLVM快速生成一段IR看看
int func1(int a, int b){
int c = 10;
return a+b+c;
}
//> clang -emit-llvm -S func1.c -o func1.ll
上述代码的IR表示为
define i32 @func1(i32) #0 {
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 %0, i32* %3, align 4
%4 = load i32, i32* %3, align 4
%5 = icmp sgt i32 %4, 0
br i1 %5, label %6, label %9
6: ; preds = %1
%7 = load i32, i32* %3, align 4
%8 = mul nsw i32 %7, 2
store i32 %8, i32* %2, align 4
br label %12
9: ; preds = %1
%10 = load i32, i32* %3, align 4
%11 = add nsw i32 %10, 3
store i32 %11, i32* %2, align 4
br label %12
12: ; preds = %9, %6
%13 = load i32, i32* %2, align 4
ret i32 %13
}
我们发现LLV的IR中带有类型系统,虽然还不知道i32代表什么,但是可以猜想其含义为32位的integer。另外,LLVM的IR同样有类似汇编的操作码,而且还支持{...},因此能明确的看出函数的定义,大大增加了代码的可读性。
LLVM IR语法
以上面代码为例,我们来看一下IR的基本语法
-
标识符,全局的标识符以
@开头,表示全局变量和函数,本地标识符以%开头,比如函数中的%1。标识符可以没有名字,没有名字的标识符用数字表示。 - 操作码,操作码就是指令中的动词,比如
alloca,store,load,add和retalloca栈上分配空间store写入内存load从内存中读
- 类型系统,LLVM的IR中有类型系统,这点和汇编语言比较不一样。LLVM的类型系统包括基础数据类型,函数类型和void类型。具体如下
- 整形(用
iN表示)i1表示一个1个比特的整形i32表示32位的整形
- 浮点型
half- 16位的浮点型float- 32位的浮点型double- 64位浮点型fp128- 128位浮点型
- 指针 (用
*表示)[4 x i32]*表示指向一个具有4个32位整形的数组的指针i32(i32*)*表示一个函数指针,输入是一个指向32位整数的指针,输出为一个32位的整数
- 向量 (用
<>表示)<4 x float>代表4个浮点数的向量
- 数组 (用
[]表示)[4 x i32]代表4个整型数的数组
- 结构体(用
{}表示){ float, i32(i32)* },两个元素的结构体,一个是浮点数,一个是函数指针
- 紧凑结构体 (用
<{ }>表示)<{i8, i32}>,忽略内存对齐,元素排列紧凑,表示40bit,5个字节
- 整形(用
- 全局变量和常量,全局变量用
global表示,内存地址在编译时就确定了。常量用constant表示,值在运行时不会被修改@x = global i32 400, align 4@x = constant i32 100, align 4
-
元数据,以
!开头的指令。这些元数据定义了一些额外的信息,提供给优化器和代码生成器使用 - 基本块,函数中如果有if语句,函数体指令会被分成多个基本块,每个块用一个数字label标识,函数入口默认的label为entry。上面例子中,函数被分成了
6,9,12三个block。我们分析一下9里面的代码%10 = load i32, i32* %3, align 4表示将3从内存中读入寄存器,名字为10,内存对齐是4字节%11 = add nsw i32 %10, 3表示将10号变量加3保存到11号变量中 (nsw 是加法计算时没有符号环绕)store i32 %11, i32* %2, align 4将11号变量保存到内存中2号变量的位置。回到函数开头,可知%2代表返回值,%3表示参数bbr label %12跳转到label 12的代码块。这里要注意的是,每个基本快的末尾必须是终结指令,该指令可以是br的跳转指令,也可以是返回指令ret
优化参数
我们可以通过控制编译器的优化参数来控制LLVM生成的IR,我们以下面代码为例,默认情况的优化参数为-O0表示不作任何优化,那么生成出来的代码会非常长
int func1(int a, int b){
int c = 10;
return a+b+c;
}
define i32 @func1(i32, i32) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
store i32 10, i32* %5, align 4
%6 = load i32, i32* %3, align 4
%7 = load i32, i32* %4, align 4
%8 = add nsw i32 %6, %7
%9 = load i32, i32* %5, align 4
%10 = add nsw i32 %8, %9
ret i32 %10
}
如果我们使用-Os,则编译器会将上述代码优化到三行
define i32 @func1(i32, i32) local_unnamed_addr #0 {
%3 = add i32 %0, 10
%4 = add i32 %3, %1
ret i32 %4
}
其差别在于将原先对内存的指令(load,store)优化成了只对寄存器操作
从IR到可执行文件
对于iOS程序员都不陌生的bitcode实际上就是LLVM IR的二进制表示,我们可以用下面命令将IR代码转成bitcode
> llvm-as func1.ll -o func1.bc
#or
> clang -emit-llvm -c func1.c -o func1.bc
接下来我们可以将bitcode编译为汇编代码
> llc func1.bc -o func1.s
有了汇编代码我们就可以生成目标代码和可执行文件了。实际上从LLVM的IR到最终的可执行文件可以有下面两条路径
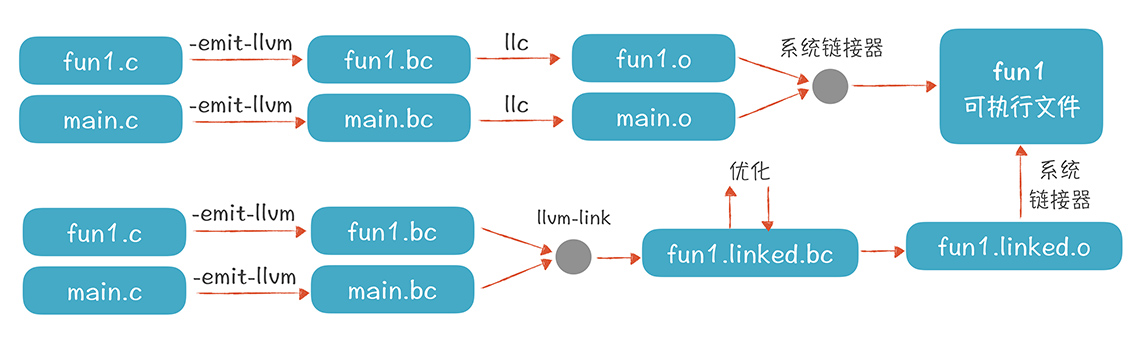
这里需要重点关注一下第二种方式,它不同的地方在于将所有文件的IR进行了一次llvm-link后生成了一份总的IR,并且可以根据这份IR做整体的代码优化,即所谓的Linker Time Optimization。目前看来这一种很灵活的优化方式,很多大型App都有采用,感兴趣的可以试一下LLVM官方提供的例子。