
浅谈系统设计
Motivation
最近在Youtube上看了美国贴吧Reddit创始人Huffman在Udacity上分享的一些关于后端的课程,其中有一部分讲到了Reddit是如何从一个单机Server Scale到千万用户量级的,听下来收获很大,意犹未尽。长久以来,我对这个问题一直很感兴趣,结合自己在阿里工作的一些经验,颇有一些体会。但反思下来,自己对架构的理解还是太有局限性了,一方面是由于一直从事客户端业务架构的设计,自己的视角多聚焦于客户端,而客户端架构和服务端相比,其复杂度是不在一个数量级的(客户端并不承担很复杂的业务逻辑),即使是淘宝或者支付宝这样的App,其架构也不算复杂。另一方面,由于客户端与服务端在架构设计方面的侧重点不一样,这会导致对架构的理解会不一样。举个例子来说,在高可用方面,服务端可以进行冗余设计,灾备设计,即使某台Server挂掉了,集群有能力自动将请求转移到冗余的Server上,业务不至于受太大的影响。而对于客户端来说,高可用意味着 0 bug,因为一旦出现线上的Crash,在不采用”特殊”手段下,是无法在线恢复的,这意味着这个bug在下一次提交App Store前是无法被修复的,因此在高可用上,客户端的挑战更大。
关于架构设计本身的方法论并不多,这方面的教科书也基本上没有,其原因在于架构设计本身是一门基于实践总结得出的经验而非实实在在的理论模型,并不存在一套完美的架构,好的架构都是和业务强绑定的。同一套技术架构不可能应对所有业务场景(比如Amazon和Facebook),而相似的业务场景也不一定要采用相同的技术架构(比如淘宝和京东)。既然架构设计没有Silver Bullet,那么这么多人在谈架构,他们谈的是什么呢?因此,在学习系统设计之前,我们有必要先搞清楚一些基本问题
-
架构设计的目的到底是什么?
我个人认为,架构设计的目的或者架构师的价值在于不断解决业务在发展过程中出现的问题,至少技术不能成为业务前进的瓶颈。简单的说,架构就是用来解决问题的。这句话看似简单,做起来却非常不容易。现在很多人抛开业务谈架构,都只是空谈,好的架构师一定是从业务中被“虐”出来的。因此判断一个架构师是真的否有“料”是要看他经历过什么样的业务,业务规模有多大,解决过什么样的问题,设计的系统量级有多大。这方面典型的例子是阿里的多隆,记得自己刚去阿里的时候,记不清哪次分享,有人问多隆,怎么成为他那样的技术牛人,多隆先谦虚了一下,然后只回答了一句,”不断解决问题”。估计他技术成长的经历就是一部淘宝技术发展的血泪史。
-
如果没有统一的方法论,我们学习架构设计要学习什么?
我个人认为,架构设计包含两方面,一方面是“术”的学习,一方面是“道”的领悟。这两者的关系可以用量变引起质变来描述,所谓“术”就是不断学习架构中的每个关键节点的核心原理,学习开源框架,知道它们可以解决什么问题,然后不断的在业务中实践与总结,多提炼共性,做的多了自然会有“感觉”,而“感觉”实际上就是经验。而如果想要达到质变,也就“道”的境界,则多少需要一些悟性和运气,悟性指的是创造力,当已有方案均不能满足业务需求时,是否能够创造出业界没有的东西,这方面代表人物太多了,比如Ryan Dahl,Jeff Dean等,这些人是可以真正推动技术进步的架构师。而运气则要看你是否有机会像多隆一样能和一家公司持续成长,能够有机会不断解决业务中的问题。在实际生活中,大多数优秀的架构师都处在“术”与“道”之间,而这也是我们普通人能够达到的高度。
Overview
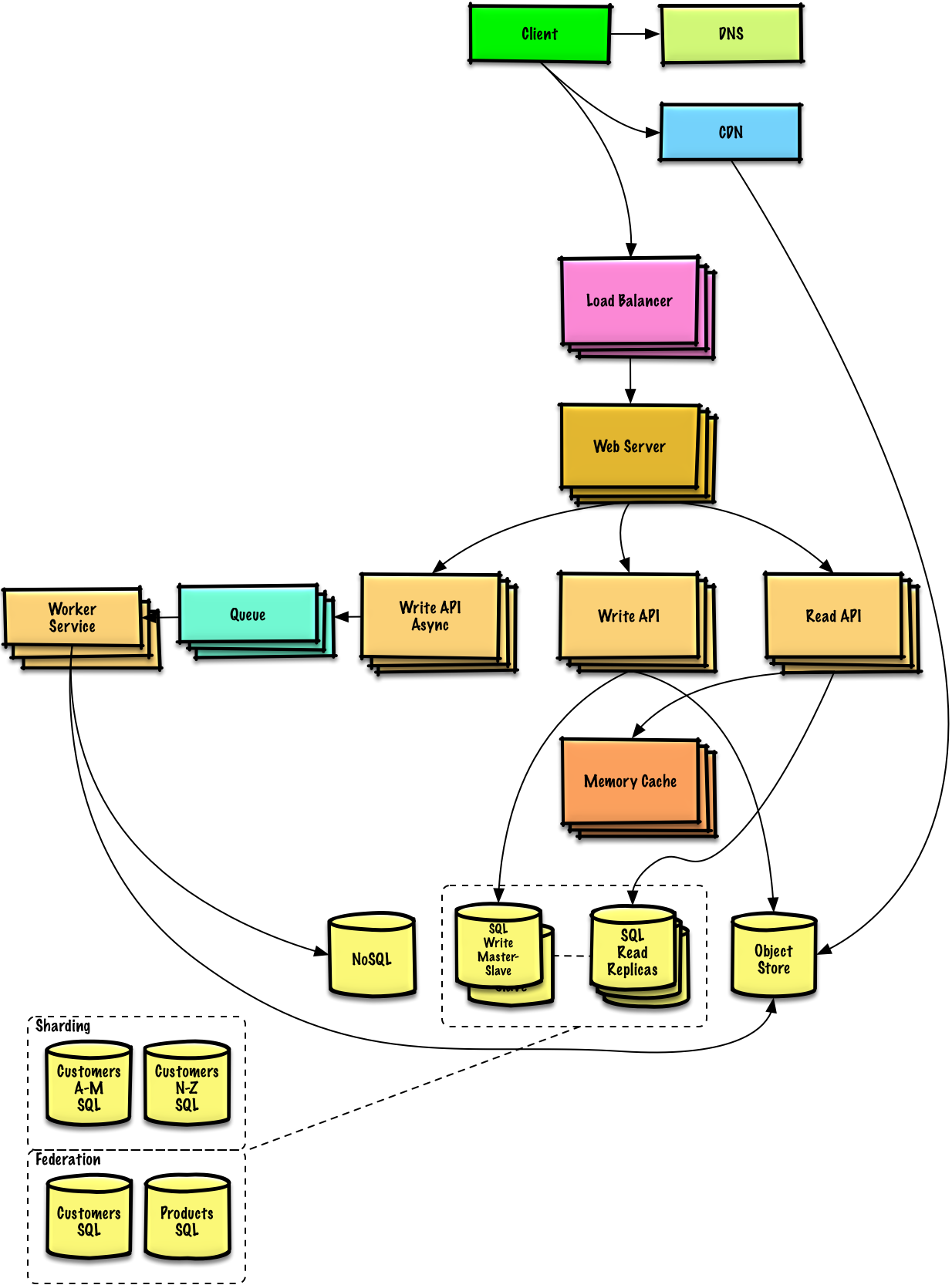
source: Introduction to architecting systems for scale.
DNS
DNS是域名系统,用来将域名解析为IP,通常DNS服务是由电信运营商提供。其原理简单来说就查表,每台DNS服务器检查自己的缓存中是否有有该域名所对应的IP,如果有则返回,如果没有则会去查ROOT DNS Server,如果ROOT DNS Server还是没有,则返回DNS unresolved error。当浏览器或者OS拿到DNS结果后,会根据TTL的时间对IP地址进行缓存。
例如,Chrome可通过chrome://net-internals/#dns地址查看缓存的DNS信息,对于OSX可通过下面命令查看某域名对应的IP地址,如果要查看完整的DNS缓存,可参考文章最后一节的参考文献。
➜ ~ host -t a youtube.com
youtube.com has address 172.217.15.110
DNS服务的维护非常复杂,通常由政府或者运营商完成。DNS也容易被DDos攻击,一旦被攻击(如果不知道网站的IP地址),则无法通过域名进行访问。更多关于DNS的架构内容可参考文章最后一节的参考文献。
CDN
CDN是基于地理位置的分布式proxy server。主要作用是代理用户请求以及支持用户对静态文件的访问。打个比方,假设你开一家鞋店,你的App Server是总店,各个地区的CDN节点就是分店,由于是分店,鞋的种类、型号肯定没有总店那么全,但也基本包含了最热销的款式,所以只要不是特别独特的需求,分店是完全可以满足的,这样既缓解了总店和交通的压力,也提高了用户的购物体验。
具体来说,用户的请求首先到达DNS,DNS会将请求转发到离自己最近的CDN节点,如果该请求不带有任何Session信息,仅仅是浏览,那么该请求是不会到达后端的,如果带有用户信息,则由该CDN节点转发请求到后端的App Server。另外,当处理大促秒杀等场景时,CDN同样可以拦截掉大部分请求,从而达到控制流量的目的。
CDN的关键技术是对资源的管理和分发,按照分发的模式,可分为Push CDN和Pull CDN
- Push CDNs
Push是由管理人员主动upload资源到各个CDN节点,并修改资源地址指向CDN节点,还要配置资源过期时间等。PUSH的内容一般是比较热点的内容,这种方式需要考虑的主要问题是分发策略,即在什么时候分发什么内容;对于流量小的网站,对资源的更新不会很频繁,因此适合采用这种方式,如果流量大的网站,使用这种方式则会带来较高操作成本。
- Pull CDNs
Pull的方式是被动的按需加载,当获取静态资源的请求到达CDN后,CDN发现没有该资源,则会”回源”,向后端Server询问,在得到资源后,CDN则将该资源缓存起来。如果使用这种方式,CDN往往需要一个预热的阶段,通过一系列少量请求将资源推到CDN节点上,然后再开放给大量的用户,如果不经过预热,则会导致大规模的”回源”请求,很容打挂后端的Server。因此Pull的方式更适用于流量较高的网站,当CDN预热一段时间后,CDN将保留当前最新的最热门的资源。
Load Balancer
负载均衡是一个非常重要的系统,也可以说是无处不在的一个系统,比如在DNS中可以使用负载均衡动态分配请求到不同的CDN上,对于内部App Server的集群也需要使用负载均衡来管理请求的转发。除了转发请求以外,Load Balancer还可以用来检测单点故障,当某个Server挂掉后,及时将请求转移其它Server上。
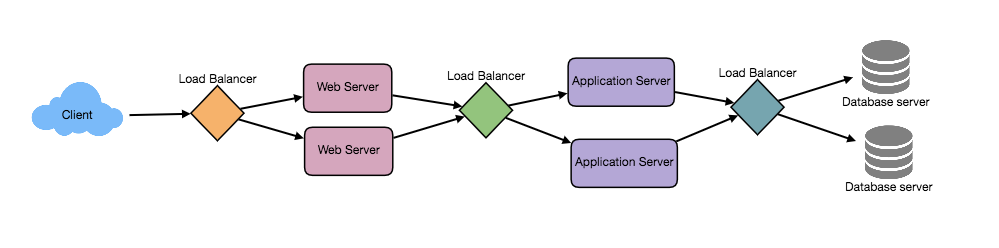
Load Balancer的实现可以用硬件,比如Citrix NetScaler旗下的产品,使用硬件的好处是稳定且速度快,缺点是非常贵。当然Load Balancer也可以用软件实现,比如Ngixn或者HAProxy,这种方式仍是目前的主流方式。
Load Balancer的路由策略有很多种,常用的有如下几种,
- Random
- Least Loaded
- Session/cookies
- Round robin or weighted round robin
- Layer 4
- 所谓Layer4策略是指根据传输层的某些特征进行路由,不需要感知数据包中的传输内容。
- Layer 7
- 同理,Layer7策略是根据应用层信息来路由请求,比如播放视频的请求会被投递到视频服务器上,而用户支付的请求则会被投递到处理支付业务的服务器上
其中Round-Robin,Least Loaded以及基于Session/cookie的路由策略,我们在后面的文章中会做更详细的分析。需要注意的是,负载均衡如果配置不当可能成为系统的瓶颈,另外如果只有一个Load Balancer Server,那么它极容易成为最大的单点,因此实际应用中还需要考虑配置多个Load Balancer来防止单点故障
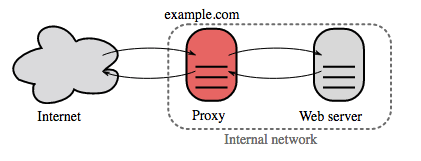
Reverse Proxy
和负载均衡类似的概念是反向代理,所谓反向代理代理的是内部的server,当外部请求过来后,Reverse Proxy可根据路径将请求动态分配给内部的server。
{kind=link}
反向代理除了路由请求外,还可作为中间层对所有进来的request和出去的response进行一些加工,比如:
- 可为站内所有HTTP服务做SSL加密
- 统一处理站内所有HTTP Response的压缩,缓存等
- 统一配置静态资源(HTML/CSS/JS/Image/Videos…)路径
- 增加安全性,Hide掉内部Server的一些信息等
反向代理和负载均衡的区别如下:
- 当网站流量大,需要有多台App Server构成集群时,使用负载均衡
- 反向代理对于管理单机运行多个服务非常有用
- Nginx或者HAProxy即可作为反向代理,又可作为负载均衡来使用
App Servers
由前面小节的讨论可知,当用户处于非登录状态时,可直接访问CDN上的静态资源(网页),但是如果用户是登录状态,则请求会通过Load Balancer路由到内部的App Server集群上。对于集群中的所有的App Server,它们上面跑的代码相同(每台Server均是彼此的clone),理想情况下各自负责处理“无状态”的业务逻辑,不会在本地存储任何用户相关信息以及各种其他的状态。对于全局的状态信息,比如Seesion,则会统一的存到分布式缓存中,对于缓存,我们后面还会专门介绍
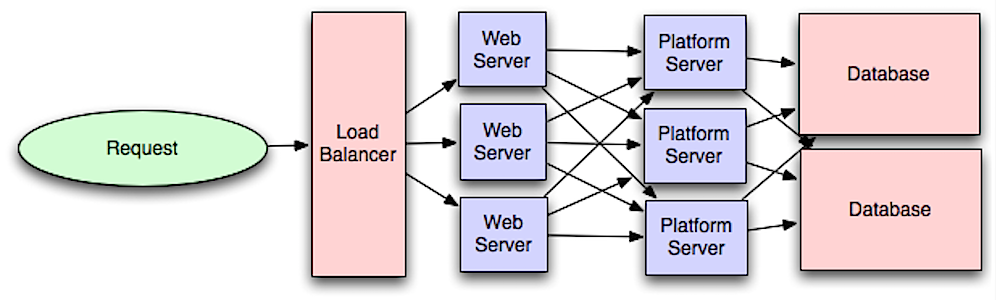
Source: Intro to architecting systems for scale
Server集群的另一个问题是,这些server节点该如何管理,如何上线或者下架一台server,众多的server之间该如何通信,server之间的状态如何同步,以及当某台server出问题之后,怎么能快速恢复等等。显然靠人工来解决这些问题是不现实的,因此,最好有一套统一的服务框架或者配置中心可以将这些Server的生命周期以及通信一并管理起来。针对这个问题,业界常用的解决方案有 Consul, Etcd, 和Zookeeper。目前比较流行的是ZooKeeper,很多大型网站内部也都在使用ZooKeeper,当然具体情况还要具体分析,需要根据业务场景选取最适合的方案。更多关于服务管理的问题,我们后面的文章会单独讲解。
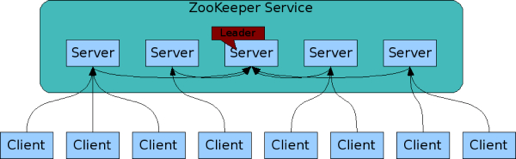
另外,对于分布式Server的代码同步以及部署也是一个问题,好在目前有很多开源项目可以解决这个问题,比如Ruby体系的Capistrano等
以上这种基于Load Balancer + 分布式Server的扩展方式可以称为horizontally scale。这种方式的优点是可以处理大量的并发请求,但是缺点是如果后端只有一两个Database,那么数据库的读写将会很快成为瓶颈。
Database
上一节提到App Server可以做到“无状态”,无状态的好处在于彼此没有耦合,可以做到完全的并行化;而数据库成为瓶颈的原因在于数据库是有“状态”的,其状态表现为彼此之间要维持数据一致性,当有一条数据写入时,备份DB都要lock,等待数据同步完成。对于数据库的扩展可以选择两种方式,一种方式是使用Master-Slave的架构来复制出多份数据库,如上图中所示,让所有读请求路由到Slave上,写请求路由到Master上。这种方式会随着业务不断的变复杂,数据表字段不断增加,查询速度也会变得越来越复杂,尤其是JOIN操作将会非常耗时,这时可能需要一个DBA要对数据库进行sharding(分库分表),做SQL语句调优等一系列优化,但这些优化并不解决根本问题。
第二种方式是在开始的时候就使用NoSQL数据库,比如MongoDB,CouchDB。使用这类数据库,JOIN操作可以在应用层代码中实现,从而减少DB操作的时间。使用NoSQL如果我们的系统需要:
- super-low latency
- data is unstructured, or there is no relational data
- need to serialize and deserialize data (JSON, XML, YAML, etc)
- store a massive amount of data (e.g. telemetry logs)
但是无论哪种方式,随着数据量增多,业务不断复杂化,对DB的查询依旧会变得越来越慢,这时候就要考虑使用缓存
Caching
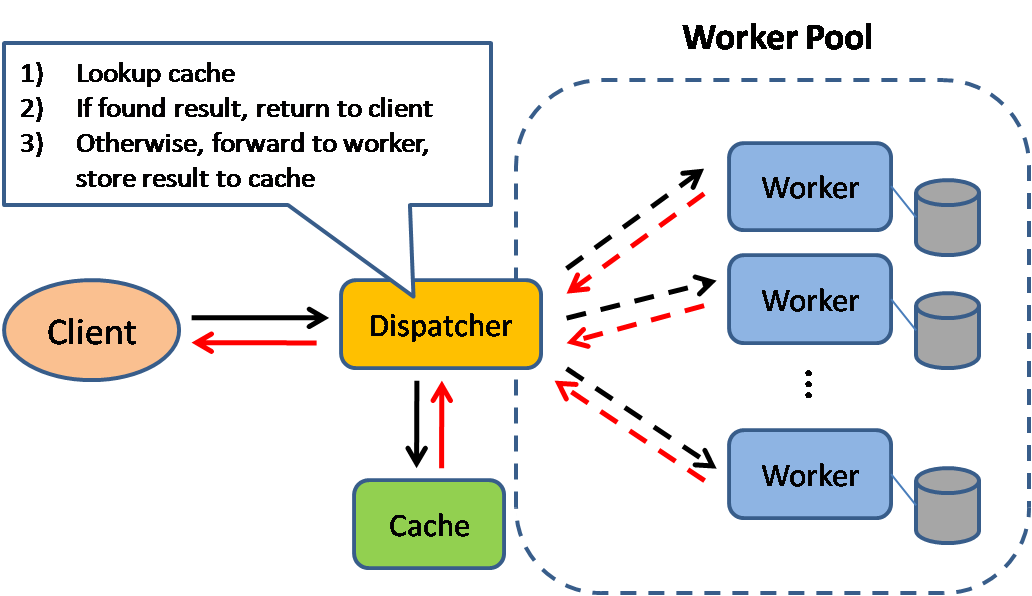
Source: Scalable system design patterns
这里说的缓存指的是内存级别的缓存,比如Memcached或者Redis。永远不要做文件级别的缓存,这对server的clone或者scale都非常不利。
对于内存级别的缓存,其存储以及访问形式为key-value。当app server想要从DB取数据时,首先去缓存里查一下,没有再做DB查询,例如,Redis可以支持10万/秒级别的并发查询,写缓存也要比DB快很多。对缓存的读写也有两种方式:
- 缓存DB Query的结果
这种方式仍然是目前使用比较多的一种方式。每当DB查询完成时将结果缓存在Cache中,key是query的hash值。再下一次执行相同query时,先检查缓存,如果命中则缓存结果。这种方式实际上有很多问题,一个比较大的问题是缓存数据的时效性,当DB中的数据发生变化时,相同query的结果会发生变化,但是缓存是无法感知的,这时要删掉该query对应的所有缓存数据,
- 缓存Objects
这种方式是个人比较推荐的一种方式,它将从DB取出的数据进行ORM,将得到的Object存入到缓存中。假设有一个类Product,它有几个property分别是prices,reviews,category等等,现在需要根据某个ID来查询某个Product,显然首先要从DB里查出这个ID对应的一系列上述propertiy的值,然后利用查出来的这些数据构建一个类型为Product的Object,最后将这个Object放入缓存中。这样当每次数据库中数据发生变化时,App Server可以监听到这个Event,然后异步的对缓存中的Obejct进行更新,而不是像第一种方式一样去删除某条缓存。这种缓存方式显然更高效。
缓存的内容可以包括用户的session信息(不要存到数据库中),静态页面,用户-朋友关系等。另外,使用Redis起单独的server做缓存要好过在同一个App Server中使用memcached,后者在维护数据一致性方面难度很大。在某些条件下,甚至可以使用Redis取代DB做持久化存储。
对于更多分布式缓存的问题,后面还会专门写一篇文章来分析
Message Queue
如果网站的流量大了,所有的操作尽量异步。异步操作又分为很多种,这里讨论两种,一种是异步任务,一种是定时任务。
所谓定时任务是指将一些时效性不是特别强,但是却消耗资源,消耗时间的计算(比如投票,日志收集等)提前做好,或者每一到两个小时执行一次,然后将得到结果缓存,缓存的方法有很多,比如将计算结果更新到数据库中,或者upload静态页面到CDN上,等等
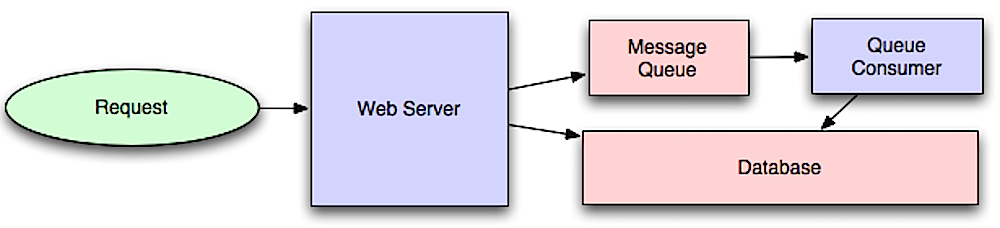
Source: Intro to architecting systems for scale
另一种就是所谓的异步任务,这种异步操作对时效性有要求,同时又消耗大量的计算资源,用户需要留在前台等待计算结果。这时候需要建立一个任务队列或者消息队列(如上图中所示)来调度异步任务。
所谓的消息队列和任务队列,并没有本质的区别,从功能上看,消息队列仅负责投递消息,任务队列负责异步执行耗时任务,但总的来说,二者都是用来处理异步任务的,其流程如下:
- 应用程序向消息/任务队列中投递任务,注册回调
- Message Broker负责监听消息队列的状态,分配任务给Worker Thread/Process执行,当任务完成后,负责通知应用程序
常用的消息队列有:
- Redis 可用作简单的消息队列,但有可能丢消息
- RabbitMQ是比较流行的,但是需要实现
AMQP协议,并且需要管理自己的节点 - Apache的ActiveMQ
- Amazon的SQS 延迟较高,并且会有消息重复投递的问题
常用的任务队列有:
- Celery
- Resque
- Kue
如果队列任务投递的速度远超过消耗的速度,则队列的size将会显著增长,此时内存消耗过快会导致内存耗尽,而内存的消耗又可能导致cache工作异常,进而导致大量的磁盘读写或者DB请求,从而拖慢整条链路的速度。这种情况下,需要考虑使用Back Pressure来限制队列size的大小。当消息队列满负荷时,clients的请求会返回HTTP 503提示稍后尝试,等待时间的选择可采用指数退避算法,即等待时间是随指数增长,从而避免频繁的重试。
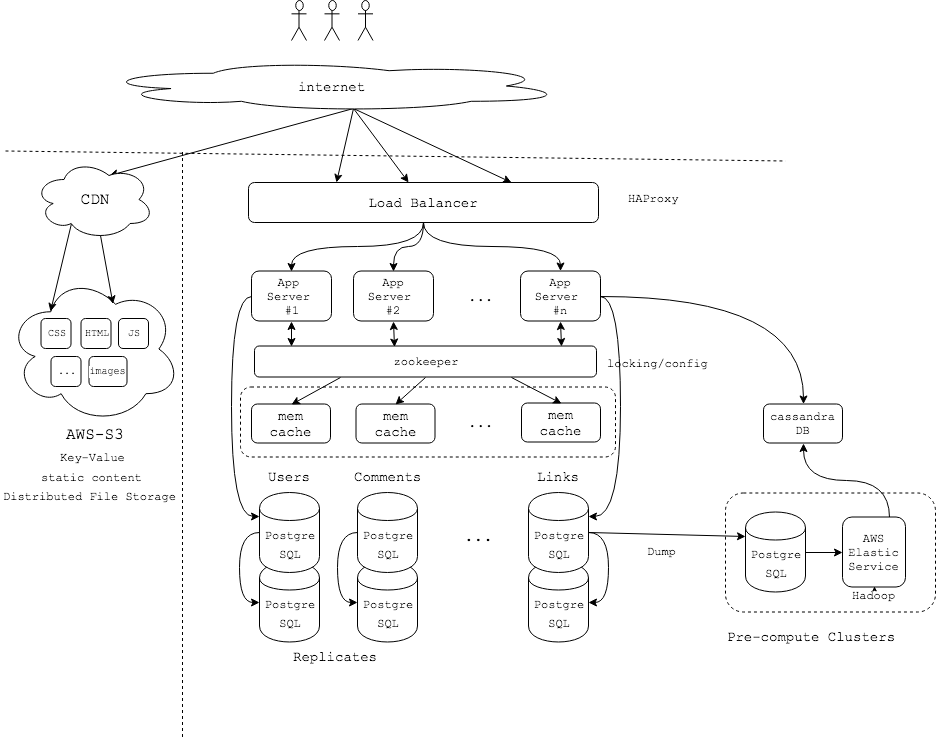
A Case Study
最后我们可以分析一下Reddit网站的架构设计,这部分内容来自两部分,一是我对Huffman在Udacity课程上视频的整理。二是Neil Williams在QCon上的分享。由于没有正式的文章,因此部分细节可能不完全正确,权且作为学习这部分内容的一个小结
Resource
- Anatomy of a System Design Interview
- Top 10 System Design Interview Questions for Software Engineers
- CS75 (Summer 2012) Lecture 9 Scalability Harvard Web Development David Malan
- Introduction to architecting systems for scale
- How to view DNS cache in OSX
- DNS Architechture
- HAProxy architecture guide
- WHAT IS LAYER 4 LOAD BALANCING?
- WHAT IS LAYER 7 LOAD BALANCING?
- Reverse proxy vs load balancer
- introduction-to-apache-zookeeper
- Applying Back Pressure When Overloaded
- Scalability for Dummies
- System Design Primer