
浅谈CAP理论
今天我们来继续学习系统设计,我们要看一个这样一个理论 - CAP。所谓CAP是指对于一个分布式系统,不可能同时满足以下三点:
- 数据一致性(Consistency),即每次请求返回最新的数据或者返回错误
- 可用性(Availability),即每次请求都能拿到正确的返回,但不能保证数据是最新的
- 分区容错性(Partition tolerance),即在分布式网络中,出于容错的考虑,每个节点的数据都会被拷贝多份,这样当某个节点出现故障后,该节点的数据仍可被访问到,对于分布式系统,分区容错是基本要求
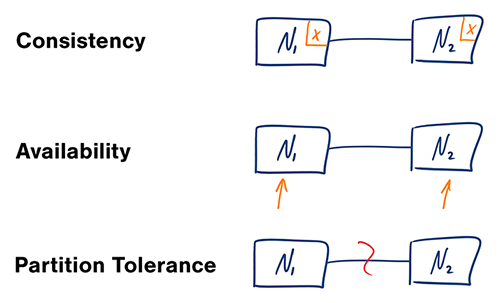
所谓分区是指一个分布式系统里面,节点组成的网络本来应该是连通的使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。如果要保证一致性,那么每次写操作就都要等待全部节点同步完成,而这等待会带来可用性的问题;如果要保证可用性,那么就允许返回旧数据。因此,在系统设计时,需要根据业务类型进行选择与权衡
CP
如果要满足C和P,那么每次写操作需要同步所有分区节点,这会导致在同步的过程中有请求超时的情况。CP适合读写操作需要保持原子性的业务,比如DBMS等。实际应用中的多数场景,只要能够保证数据最终一致即可。
对于一致性问题,从客户端角度看是每次写操作后立即读取是否能够拿到最新数据,而对于服务端来看,考虑的是如何将这次写操作产生的数据copy到各个节点,以保证数据一致性。
一致性又分为下面三种情况:
Weak Consistency
弱一致性是指写操作产生的数据对读操作完全不可见,memcached使用这种策略。弱一致性适用于VoIP,视频聊天,游戏对战等实时场景。这种场景对可用性要求较高,即建立连接保持在线是最终要的。例如,当游戏短线后重连,无法获取断线之前的数据。
Eventual Consistency
最终一致性是指写操作产生的数据在一段时间后(几十毫秒)同步到各个节点,数据同步的过程是异步的,当同步完成后对读操作可见。这种策略应用在DNS服务以及Email服务
Strong consistency
强一致性是指当写操作产生新的数据后,该数据以同步的方式更新到集群中的各个节点。这期间内读操作会报错,待数据同步完成后,读操作则可以拿到最新数据。这种策略适用于关系型数据库系统以及业务中涉及Transaction的场景。
AP
如果使用AP策略,当写操作完成后,各分区需要一段时间同步数据,但此时并不影响读操作,只不过返回的数据并非最新。这种策略适合需要随时保持高可用性的业务。对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式系统的方向。
可用性策略也分为两种:
Fail Over
Fail Over即故障转移,即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。常用的Fail Over策略有如下两种
- Active-Passive
这种策略是指Active Server负责处理请求(下图中的primary),Passive Server(下图中的failover)通过TCP与Active Server保持长连,负责监听其“心跳”。一旦Active Server心跳中断,则启动Passive Server。
这种方式也被称作”master-slave failover”
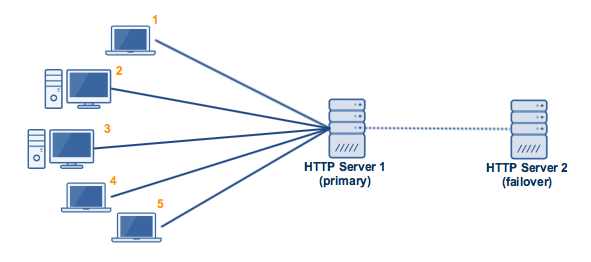
Source: Managed File Transfer and Network Solutions
- Active-Active
这种策略是指两台Server均是Active Server,同时负责处理请求。一旦某台Server挂掉,请求将转移到另一台Server上。这种策略通常会有前置的Load Balancer来感知某台Server的状态,进而动态的分配请求(对于Load Balancer我们将在后面文章中详细讨论)。
同样的,这种方式也叫做”master-master failover”
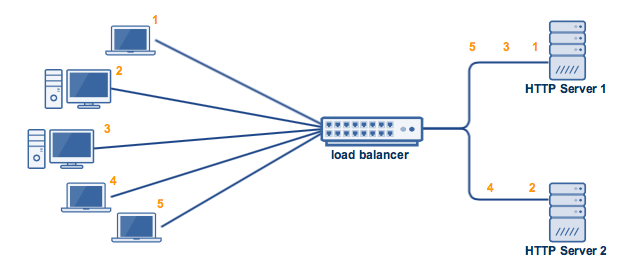
Source: Managed File Transfer and Network Solutions
Replication
保证高可用的另一种方式是备份,常见的有Master-Slave, Master-Master等,这部分内容在后面分布式数据库的介绍中会展开讨论,这里不做过多介绍。