
浅谈分布式系统特征
上一篇我们对系统架构的各个环节进行了简单的介绍,这篇文章我们先来介绍一下分布式系统的三个重要特征,分别是高性能,高可用和可扩展,这三条目标不仅适用于服务端架构,对于客户端,前端同样适用。
高性能
高性能分为单机高性能以及集群高性能,单机高性能主要集中在对进程,线程的管理以及I/O操作模型上,比如Nginx可以用多进程也可以用多线程,JBoss 采用的是多线程;Redis 采用的是单进程,Memcache 采用的是多线程,这些系统都实现了高性能,但内部实现差异却很大,对于单机高性能的问题,我们将在后面文章中会展开讨论。 集群高性能指的是当单机性能无法支撑业务访问量时,必须采用机器集群的方式来提高性能,比如支付宝和微信这种规模的业务系统,后台机器数量都是百万级别的。
延时和吞吐量
不论是单机还是集群,衡量性能的两个重要指标分别为延时和吞吐量。所谓延时是指每次请求的链路耗时,单位是时间单位;吞吐量是指单位时间内能处理多少次请求。打个简单的比方,有一家汽车修理厂,修理一辆汽车耗时8小时,一天能够修理120量车,那么这家汽车修理厂的:
- 延时为8小时
- 吞吐量为:120辆车/天 或者 5辆车/小时
吞吐量通常用TPS和QPS表示,TPS是每秒内的事务(Transaction)数,一次事物包括和响应客户端请求,执行业务逻辑,将结果返回客户端三部分;QPS是指每秒内查询次数,比如一次TPS包含了若干次数据库查询操作,因此QPS的值 >= TPS的值。对于延时和吞吐量之间的关系可以表示为:在可接受的延时范围内,做到吞吐量最大。
集群高性能
通过集群来提升性能并非是加机器这么简单,集群间机器的通信也会带来一定性能的消耗,因此,让多台机器协同工作达到高性能是一个复杂的任务。我们先从一个最简单的场景分析:
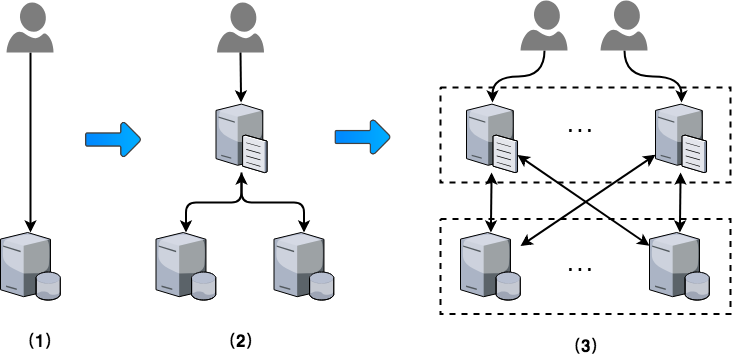
上图是一个横向扩展的例子,首先我们有一个单机应用,假设它的TPS是1000,随着业务的发展,用户量的增加,单机性能已经难以维持,因此我们又加了一台业务服务器(图(2)),此时TPS变成了2000,除去Load Balancer的损耗,实际TPS大约为1600。
接着又过了一段时间,用户数量持续增加,此时业务要求系统的TPS达到1万,我们继续扩容,将业务服务器扩展到10台,此时我们发现,性能非但没有提升,反而下降了,经排查发现单个的Load Balancer已经不足以支撑起TPS 1万的请求了,因此我们需要多个Load Balancer,此时系统变成了图(3)的样子。这时的架构显然已经变得复杂了,体现在:
- 为了将用户分到不同的Load Balancer上,我们需要对DNS进行配置,或者将DNS和CDN进行关联等
- 业务服务器和Load Balancer之间的链接由线性结构变成了网状结构
- 业务服务器从2台扩展到10台,Load Balancer从1台扩展到了3台,各业务系统之间的状态管理,数据同步开始变的复杂,故障数也开始增加,整体监控的难度也加大了
尽管管理集群的代价变高了,但是在性能上我们确实得到了提升,从1台机器变成10台机器,除去Load Balancer的损耗,整体性能大概提升了8倍。回过头来分析一下,集群方式性能提高的本质原因是通过“冗余”实现了并行计算,从而增大了吞吐量。但是又过了一段时间,随着业务的不断发展,每台Server的功能越来越复杂,性能又开始下降,10台机器性能可能只提升了5倍,经排查发现单机耗时明显增加,为了继续提升性能,我们采用了第二种方式,拆分系统。
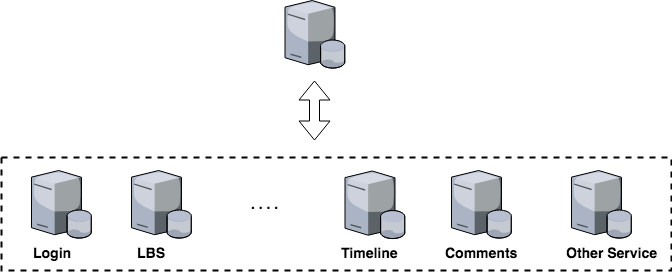
上图中可以看出,我们将一台Server中的各个子业务独立出来,拆分成各个子系统,从业务角度看,这种拆分不会减少功能,也不会减少代码量,其性能提升的本质在于分而治之:
- 越简单的系统越容易做到高性能,由于系统内部业务耦合少,针对性的优化相对容易,不会牵一发而动全身
- 单点突破,容易找到性能瓶颈做针对性优化。比如,用户增长太快,登录系统出现瓶颈,我们只需要优化登录系统即可,并且该优化不会影响其它系统的内部逻辑。
需要注意的是,拆分的子系统也并不是越多越好,由于系统间调用是走网络请求,过多的子系统会带来系统间网络请求次数呈指数级增长,反而会导致性能下降,如下图所示
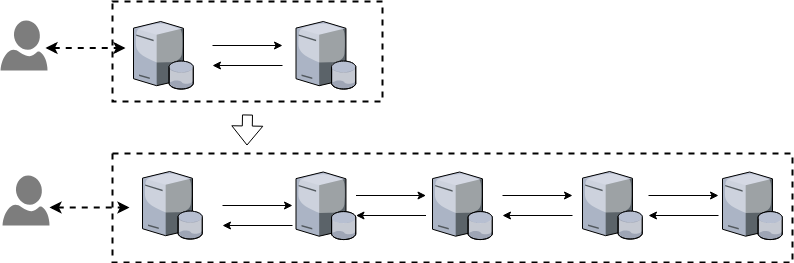
上图中,在只有2个子系统时,用户一次请求对应系统内部的1次调用;当系统拆分为4个时,系统间请求次数从1次增长到4次。假设网络传输的耗时为1ms,则4个系统会比2个系统多出2ms的耗时,如果有100个子系统,耗时则会多出98ms。因此,如何把握系统拆分粒度对架构设计来说就很关键了。
高可用
所谓高可用是指系统无中断的执行任务的能力,而无中断对于单机来说是不可能做到的,比如机房断电,水灾,地震等不可抗力就会导致单机系统不可用。因此,想要做到服务高可用,还是需要用到集群,一个机房断电,可将流量导到另一个机房,一条通道故障,就切到另一条。总之,高可用的解决方案就是增加“冗余”做备份,单纯从形式上来看,和之前讲的高性能是一样的,都是通过增加更多机器来达到目的,但其实本质上是有根本区别的:高性能增加机器目的在于“扩展”处理性能;高可用增加机器目的在于“冗余”处理单元。
使用冗余重点要解决的问题是如何对状态进行决策。即当某台Server挂掉时,其它Server如何感知这个状态并作出响应