浅谈分布式缓存
缓存概述
缓存典型的应用场景有:
- 需要实时计算的数据,数据库不适合存放的数据
例如一个SNS网页要显示当前有多少人在线,如果使用数据库存储,每次查询都需要对数据库进行
count(*),无论数据库性能如何优化,都不足以支撑频繁的查询。 - 读过写少的业务场景
绝大部分的在线业务都是读多写少,比如Facebook,Youtube,Amazon,Twitter等,读业务可能占了整体业务的90%以上,以Twitter为例,明星发一条推只执行一条
insert语句,但这条推文可能会引来千万人的浏览,对数据库来说就是千万条的select,即使有索引,对数据库的压力也非常大
缓存设计的目的就是为了应对上述场景,其基本原理就是将大量重复使用的数据放到内存中,一次生成,多次使用,避免每次查询都走数据库。引入缓存可以极大的提高查询性能,缩短请求时间,从而带来更好的用户体验。以memcached为例,单台memcached服务器简单的key-value查询可支撑TPS 50000以上。
- Application Server Cache
缓存的设计方案有很多种,最简单的是单机缓存,即当请求到来时,服务器查自己的缓存,并返回数据给Client。这种方式适用于业务场景简单,没有大规模请求的应用。但是请求量上来,单台服务器会横向扩展到多台,这种缓存方式就会出现问题,虽然被扩展出来的多台服务器仍可以自己维护自己的缓存,但是同一个用户的请求可能被负载均衡投递到不同的服务器上,会大大增加缓存Miss的概率。解决这个问题,可以使用两种方式,一种是分布式缓存,一种是全局缓存。
- Distributed Cache
分布式缓存是指多台机器组成一个缓存集群,每台机器只存放一部分缓存数据,这样当查询请求打到某一台机器上时,该台机器如果发现自己没有缓存数据,可以自动在集群中其它server上查找。这种分布式缓存的优点缓存容量可通过加机器的方式进行以水平扩展,缺点是如果某个缓存节点挂了,或者新增加一个节点,可能会导致整个集群的缓存失效。因此,如何设计缓存数据在多个节点上的分配策略就变的至关重要,我们会后面会介绍目前比较流行的一致性哈希算法。
- Global Cache
全局缓存同样是使用多台机器构成一个集群,不同的是,每台机器上所存放的缓存数据均相同,全局缓存通常由两种设计方式,如下图所示
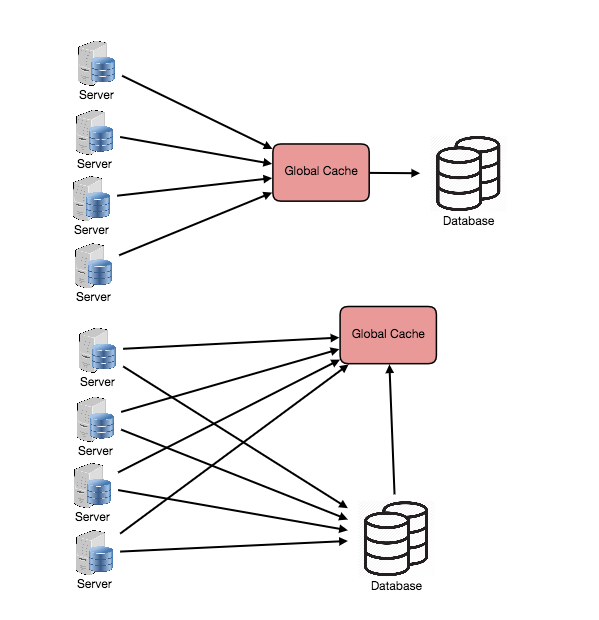
大部分应用会采用第一种方式,这种方式缓存会自动代理对DB的查询操作,省去了业务的额外调用。但并不是所有场景都适合使用第一种方式,如果缓存中的数据都是大文件,当读缓存miss的时候,缓存会自动从数据库中读取该文件,由于数据较大,读取的耗时会很长,这会导致缓存中pending的查询越来越多。这时如果使用第二种方式,由业务查询DB则会大大降低缓存压力。
全局缓存的优点是无状态,缓存节点的增删对集群没有太大的影响,缺点是单个节点能承受的数据容量有限,而且节点之间维护数据一致性也很麻烦。
- CDN节点
CDN可以用作静态资源的缓存,也可以用作对非登录用户看到数据的缓存,例如Reddit,假如用户没有登录Reddit,那么他们看到的页面和数据都是相同的,这些数据可以提前计算好并存放到CDN节点上,这样既可提高用户体验,也可以避免对后端系统访问的压力
一致性哈希算法
这一节我们来简单了解一下分布式缓存的一致性哈希算法。在介绍一致性哈希之前,我们先看一下使用传统的哈希算法会出现什么问题,正如前面所讲,对于分布式缓存,数据是分布在多台机器上的,如何决定哪台机器存放哪些数据呢?我们可以用一种简单的哈希策略,即对数据进行一次哈希运算得到一个哈希值,然后用该值对机器数量取模,得到存放的机器编号。
但是,如果数据量持续增加,需要加机器,假设原来有10台机器,现在增加到11台,则这种哈希算法将导致缓存数据全部失效。比如哈希值为13的数据,原来存放到3号机器上,现在加了一台机器后,需要对11取模,结果13这个数据就被分配到2号机器上了。因此,所有数据都需要重新计算哈希值后才能正确的版移到其它机器上,在业务高峰的时候,这种操作极有可能发生缓存的雪崩,进而压垮数据库。那么一致性哈希算法是怎么解决这个问题的呢?
假设我们有k台机器,n个key需要存储,每台机器负责缓存一个区间的数据,使用一致性哈希策略可以保证当有节点增删时,只有n/k个key需要被移动。这样,既不用全部重新哈希,搬移数据,也保持了各个机器上的数据均衡。
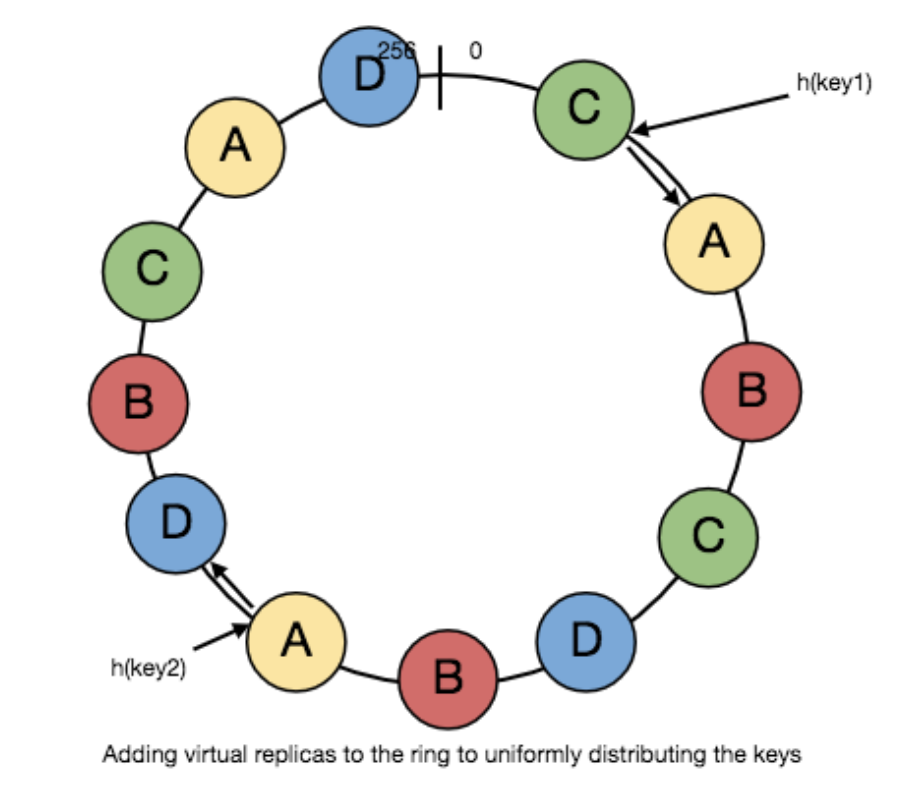
典型的一致性哈希算法如下:
- 假设所有key经过hash后的数据值为
[0,256),我们将这256个数均匀的分布在一个环上。 - 假设我们有三台Server,经过hash后位于环中的三个节点
-
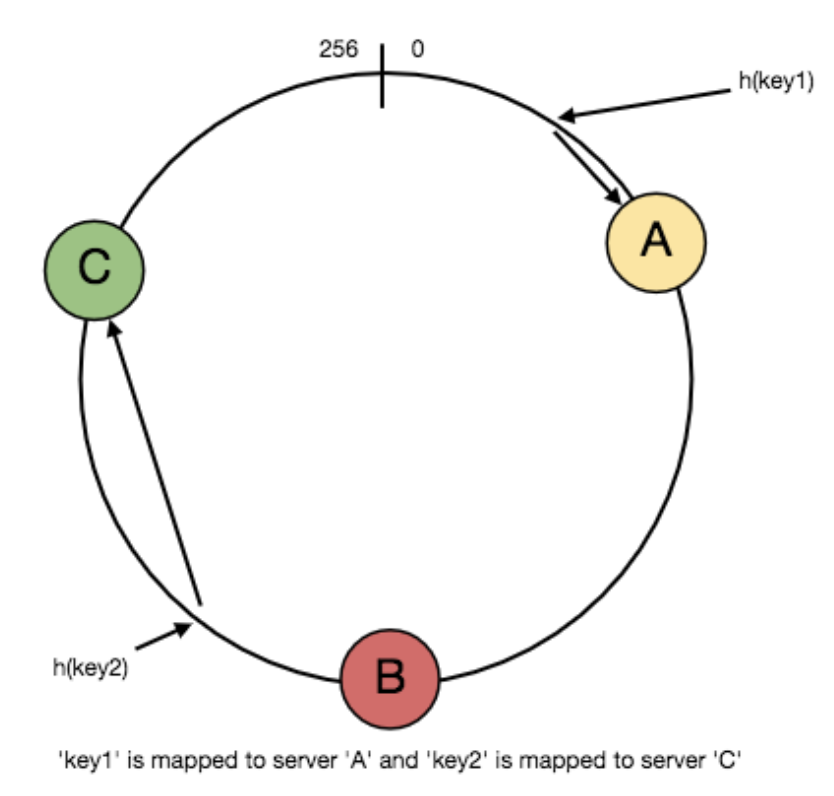
当某个key要被缓存时,先计算hash值,然后将该值在环内顺时针移动,直到碰到cache server,如下图所示,
key1被存到A中,key2被存到C中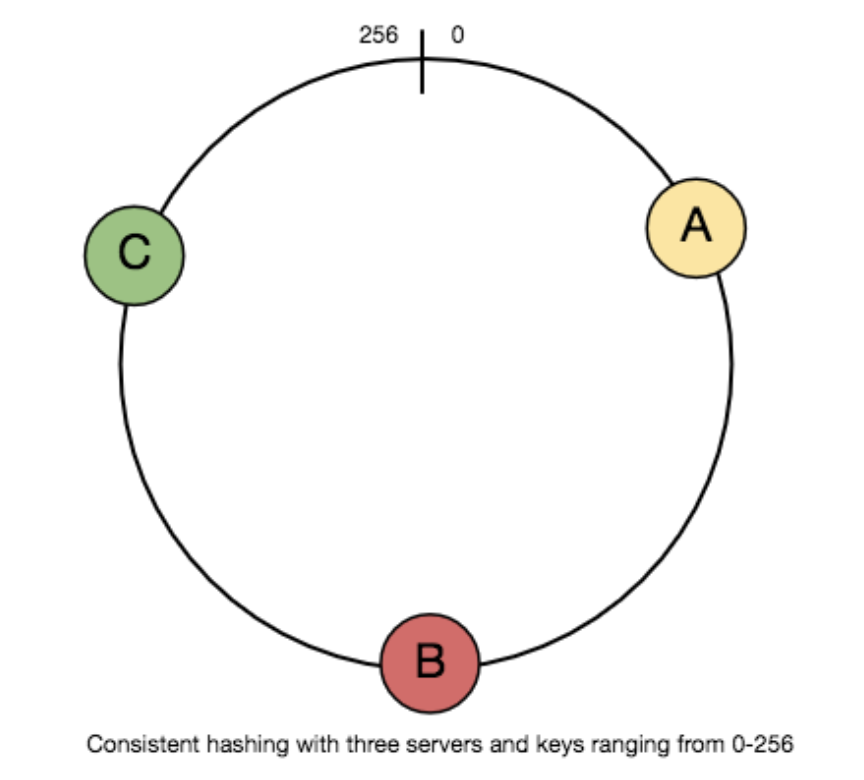
-
当有新节点(下图中
D节点)加入后,由于其位置位于key2和C之间,则原先key2的数据将被版移到D中,缓存中其它的数据不变 -
当有节点故障后(下图图中
A节点),A中存放的所有数据将被搬移到B中,其它数据不影响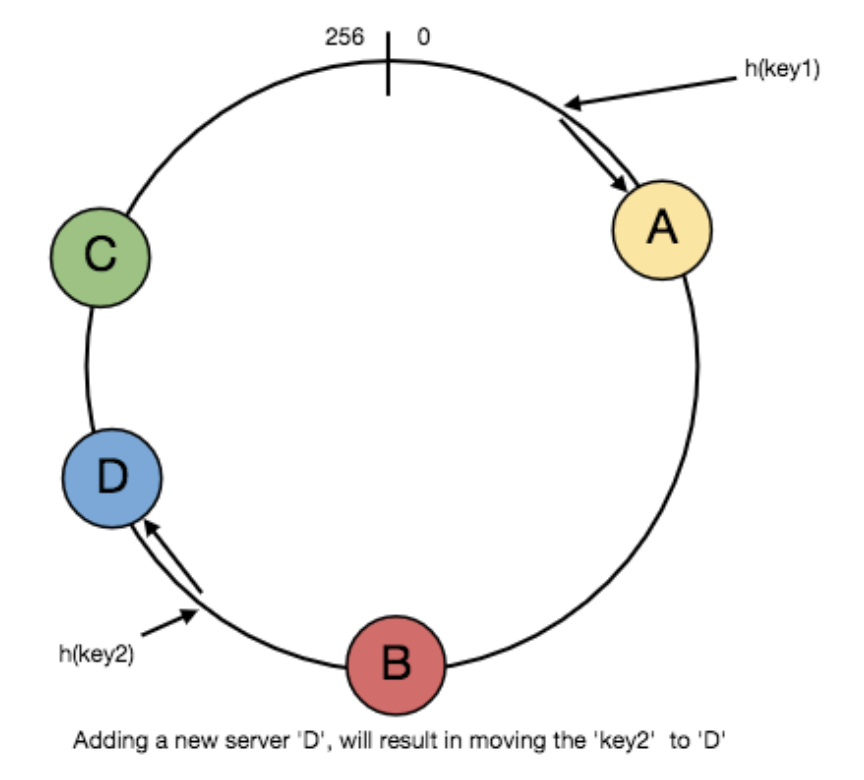
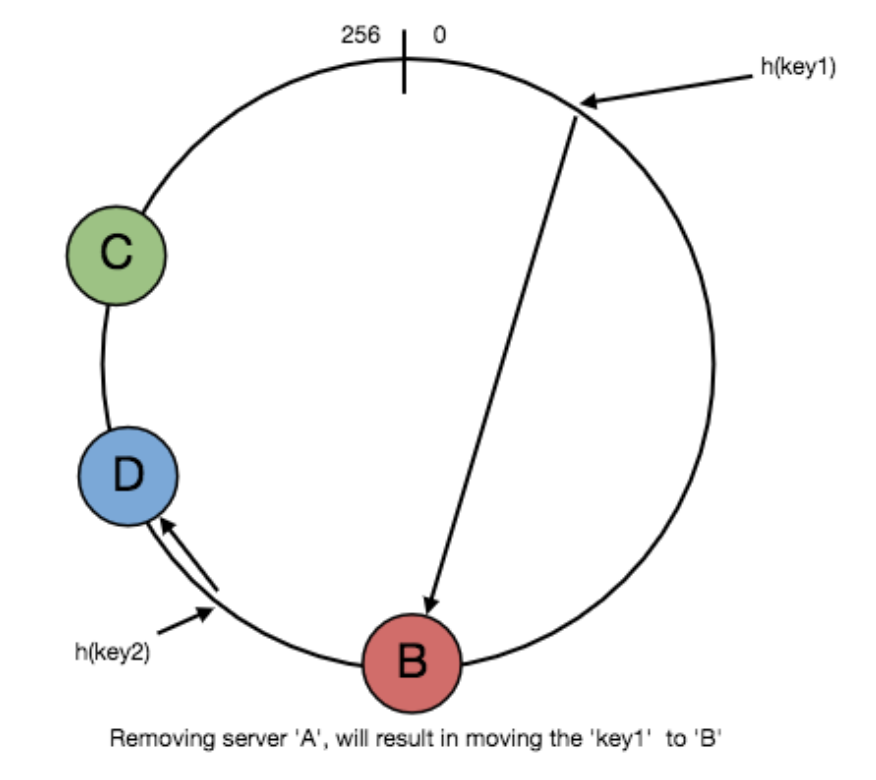
由于负载均衡投递请求的随机性,不均匀的分布可能会导致某些key距离某个节点很近,进而导致该节点中聚集大量的缓存数据。为了解决这个问题,一致性哈希引入虚拟节点的概念,这些虚拟节点是环中每台server的拷贝,我们将这些虚拟拷贝的节点均匀分布在环中,则可以保证数据的分布的均匀性,如下图所示