
Machine Learning Overview
文中所用到的图片部分截取自Andrew Ng在Cousera上的课程
Machine Learning definition
机器学习的定义:
- Arthur Samuel(1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
- Tom Mitchell(1998). Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Machine Learning Algorithms:
- 监督学习:Supervised learning
- 非监督学习:Unsupervised learning
- 其它: - Reinforcement learning - recommender systems
Supervised Learning
监督学习: “Define supervised learning as problems where the desired output is provided for examples in the training set.” 监督学习我们对给定数据的预测结果有一定的预期,输入和输出之间有某种关系,监督学习包括”Regression”和”Classification”。其中”Regression”是指预测函数的预测结果是连续的,”Classification”指的是预测函数的结果是离散的
Unsupervised Learning
非监学习: “Define unsupervised learning as problems where we are not told what the desired output is.” 非监督学习我们对预测的结果没有预期,我们可以从数据中得出某种模型,但是却无法知道数据中的变量会带来什么影响,我们可以通过将变量之间的关系进行聚类来推测出预测模型。非监督学习没有基于预测结果的反馈,两个例子:
- 聚类:取 1,000,000 种不同的基因,找到一种自动将其分类的方法,可以细胞间不同变量的相似程度进行分类,比如生命周期,位置,功能等
- 非聚类:经典的”Cocktail Party Algorithm”,从吵杂的环境中确定某个个体的声音
Model Representation
为了后面课程使用方便,我们先来定义一些术语:
- 我们使用$x^{(i)}$ 来表示输入的特征样本,使用 $y^{(i)}$ 表示我们想要得到的预测结果
- 我们使用 $(x^{(i)},y^{(i)})$ 来表示一组训练样本,通常我们的数据集中有多个训练样本,数据集用$(x^{(i)},y^{(i)});i=1,…,m$ 表示,注意上角标
(i)表示数据样本的 index - 我们使用
X表示输入样本空间,也可以理解为输入矩阵,Y表示输出样本空间或者输出矩阵,有 X = Y = ℝ.
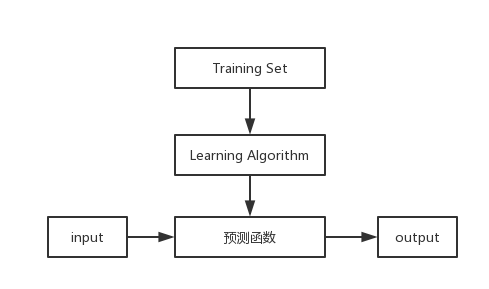
在监督学习中,对输入的样本X我们使用预测函数(hypothesis)h(x) 来求解预测结果y,即h : X → Y,如下图所示
回归的最早形式是最小二乘法,由 1805 年的勒让德(Legendre)[1],和 1809 年的高斯(Gauss)出版[2]。勒让德和高斯都将该方法应用于从天文观测中确定关于太阳的物体的轨道(主要是彗星,但后来是新发现的小行星)的问题。 高斯在 1821 年发表了最小二乘理论的进一步发展[3],包括高斯-马尔可夫定理的一个版本。