
OCR
Chapter 10 : OCR
Photo OCR pipeline
- 文字区域检测
- 字符切分
- 字符分类与识别
- 纠错
滑动窗口(Sliding Window)分类器
假设我们要检测照片中的行人,并用矩形标出。我们可以先准备好一系列(一千或者一万张的 82x36 的矩形)图片正负样本,并标注好。如下图所示,然后构建神经网络利用这些样本来训练模型,最终得到一个效果较好分类器。

准备数据
前面已经反复提到,要想得到一个高效的机器学习系统比较可靠的方法是选择一个低偏差(low bias)的学习算法,然后用大量的训练集去训练它。获得数据的方式有很多种,一种常用的手段是“人工合成数据”,即对已有样本进行某种加工来得到新的数据样本,比如识别字母可以对字母进行 distortions 来产生新的样本,识别语音可以对已有样本加入背景噪声来产生新的样本

重要的两点
- 确保要先有一个低偏差的分类模型(观察学习曲线)。例如对于神经网络,尝试持续增加 hidden units 的个数观察神经网络是否达到 low bias 的
- 如果要创造当前 10 倍的样本数据需要花多长时间
- 人工数据合成
- 手工标记
上限分析
上限分析指的是衡量系统 pipline 中各个环节效果的一种方式,以人脸检测为例,Pipline 如下:
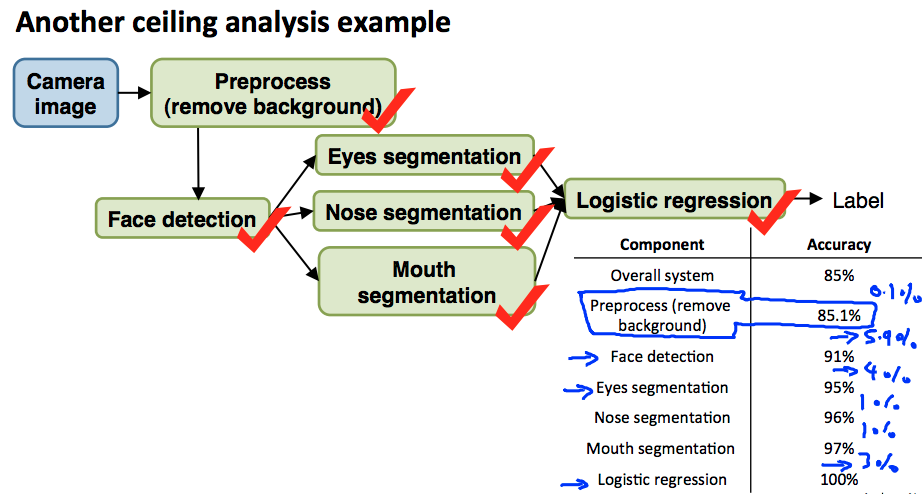
当我们发现效果不理想的时候,我们该如何投入资源解决问题?这时就要用到上限分析。上图可知系统整体识别准确率为 85%,我们先令去背景模块识别率达到 100%(通过输入一系列标记号的正样本),结果看到只提升了 0.1%,因此这部分能达到的效果有限,不值得重点投入解决。类似的可以看到人脸检测模块和眼部分离模块有 5.9%和 4.1%的提升空间,因此这两部分可投入资源来攻克。
当我们在设计完成一个机器学习模型想要提升其成功率时,可以按照这种方式来量化投入产出比,而不是凭直觉来判断。