
Regularization
Bias and Variance
-
如果我们在 train data set 上面的 error 很低,但是在 Dev set 上的 error 很高,这时我们称为high variance。此时我们的模型问题是 over fitting。解决办法是需要更多的数据或者使用 Regularization
-
如果我们在 train data set 上面的 error 和 Dev set 上的 error 都很高,这时我们称为high bias。此时我们的模型的问题是 under fitting。解决办法是引入更多的 hidden layer 来增加 training 的时间,或者使用一些的优化方法,后面会提到
Regularization
如果我们怀疑我们模型出现overfitting的情况, 我们可以尝试引入Regularization来解决。
我们还是用 Logistic Regression 来举例。在 LR 中,Cost Function 定义为
\[J(w,b) = \frac{1}{m}\sum_{i=1}^{m}L(\hat{y}^{(i)}, y^{(i)})\]为了解决 Overfitting,我们可以在上面式子的末尾增加一个 Regularization 项
\[J(w,b) = \frac{1}{m}\sum_{i=1}^{m}L(\hat{y}^{(i)}, y^{(i)}) + \frac{\lambda}{2m}||{w}||{^2}\]上述公式末尾的二范数也称作 L2 Regularization,其中$\omega$的二范数定义为
\[||{w}||{^2} = \sum_{j=1}^{n_x}\omega^{2}_{j} = \omega^T\omega\]除了使用 L2 范数外,也有些 model 使用 L1 范数,即$\frac{\lambda}{2m}||\omega||_1$。但是L1 范数的$\omega$矩阵会较为稀疏(0 很多),不常用。
对于一般的 Neural Network,Cost Function 定义为
\[J(\omega^{[1]}, b^{[1]},...,\omega^{[l]}, b^{[l]}) = \frac{1}{m}\sum_{i=1}^{m}L(\hat{y^{(i)}}, y^{(i)}) + \frac{\lambda}{2m} \sum_{l=1}^{L} \|w^{[l]}\|^2\]其中对于某$l$层的 L2 范数计算方法为
\[\|w^{[l]}\|^2 = \sum_{i=1}^{n^{[l]}} \sum_{j=1}^{n^{[l-1]}} \left( w_{i,j}^{[l]} \right)^2\]其中$i$表示 row,$n^{l}$表示当前层有多少 neuron(输出),$j$表示 column,$n^{(l-1)}$为前一层的输入有多少个 neuron。简单理解,上面的 L2 范数就是对权重矩阵中的每个元素平方后求和。
Python 代码为
for l in range(1, L):
L2_regularization_cost += (np.sum(np.square(Wl))
L2_regularization_cost = L2_regularization_cost * lambd/(2*m)
新增的 Regularization 项同样会对反响求导产生影响,我们同样需要增加该 Regularization 项对$\omega$的导数
\[d\omega = (from \ backprop) + \frac{\lambda}{m}\omega\]Gradient Descent 的公式不变
\[\omega^{[l]} := \omega^{[l]} - \alpha d\omega^{[l]}\]将上面$d\omega$带入,可以得到
\[\omega^{[l]} := \omega^{[l]} - \alpha[(from \ backprop) + \frac{\lambda}{m}\omega] = (1-\frac{\alpha\lambda}{m})\omega^{[l]} - \alpha(from \ backprop)\]可以看到,在引入正则项后,$\omega^{[l]}$实际上是减小了,因此,L2 正则也称作weight decay
Why Regularization Reduces Overfitting?
引入正则项为什么能减少 overfitting 呢?我们可以从两方面来考虑。首先通过上面的式子可以看出,如果$\lambda$很大,则$\omega$会变小,极端情况下,会有一部分 weights 变成 0,那么我们 hidden units 会减少,模型将变得简单。另一个思考的方式是看 activation results,我们知道
\[z^{[l]} = \omega^{[l]}\alpha^{[l-1]} + b^{[l]}\]当$\omega$变小后,$z$会变小,那么输出的结果将趋于线性
Dropout Regularization
除了通过引入正则项来减少 overfitting 外,Dropout 也是一种常用的手段。Dropout 的思路很简单,每个 hidden units 将会以一定概率被去掉,去掉后的模型将变得更简单,从而减少 overfitting。如下图所示
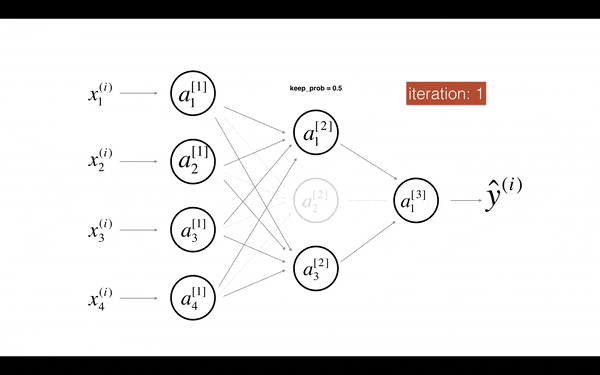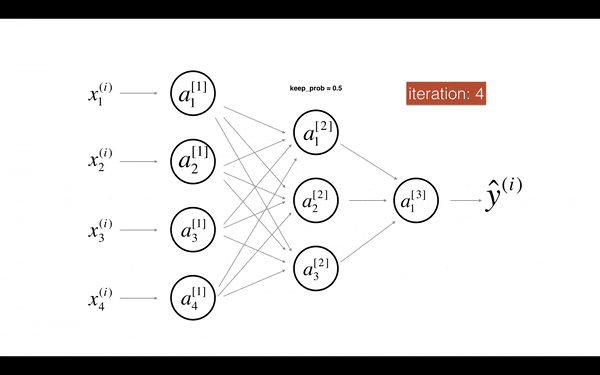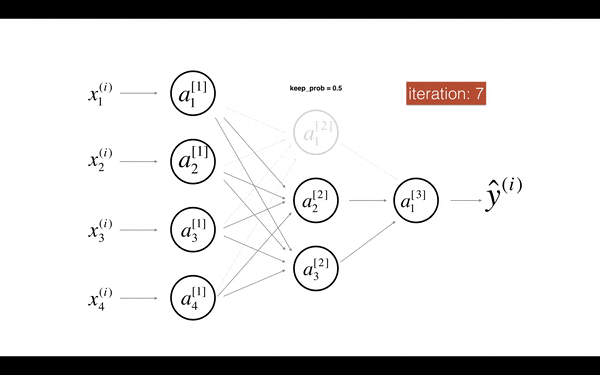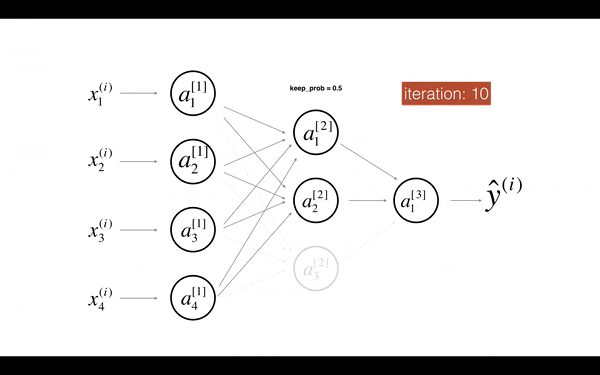
Dropout 使 Activation units 不依赖前面 layer 某些具体的 unit,从而使模型更加泛化。在实际应用中,Dropout 比较流行的实现是 inverted dropout,其思路为
- 产生一个 bool 矩阵, 以$l=3$为例
d3 = (np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob).astype(int)- 其中
keep_prob表示保留某个 hidden unit 的概率。则d3是一个 0 和 1 的 bool 矩阵
- 更新
a3,根据 keep_prob 去掉某些 unitsa3 = np.multiply(a3, d3)
- Invert
a3中的值。这么做相当于抵消掉去掉 hidden units 带来的影响a3 /= keep_prob
Numpy 的伪代码如下
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
D1 = np.random.rand(A1.shape[0], A1.shape[1]) # dropout matrix
D1 = (D1 < keep_prob).astype(int) # dropout mask
A1 = A1*D1 # shut down some units in A1
A1 = A1/keep_prob # scale the value of neurons that haven't been shut down
神经网络中每层的 hidden units 意义和数量都可能不同,keep_prob 的值可以根据每层神经网络的情况进行调整。如果我们怀疑某一层上出现over fitting,我们可以降低该层的keep_prob的值。
Dropout 表面上看起来很简单,但实际上它也属于 Regularization 的一种,具体证明就不展开了。需要注意的是,Dropout 会影响 back prop,由于 hidden units 会被随机 cut off,Gradient Descent 的收敛曲线也将会变得不规则。因此常用的手段一般是先另 keep_prop=1,确保曲线收敛,然后再逐层调整 keep_prop 的值,重新训练。
Normalizing Training Sets
对 training 数据 $X = [x_1, x_2]$,我们分别计算它们的均值和方差
- 均值
- 方差 (normalize variance)
归一化前后的$x_1, x_2$分布如下图所示
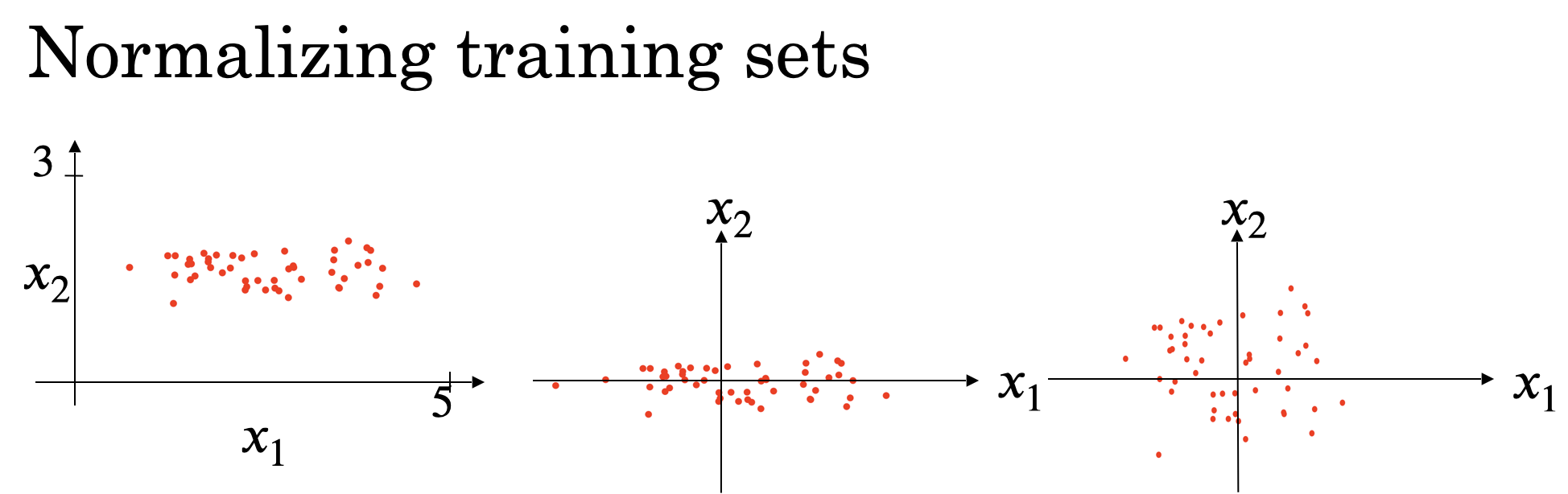
归一化 training 数据的目的是使 training 速度加快,因为 Gradient Descent 收敛加快,如下图所示
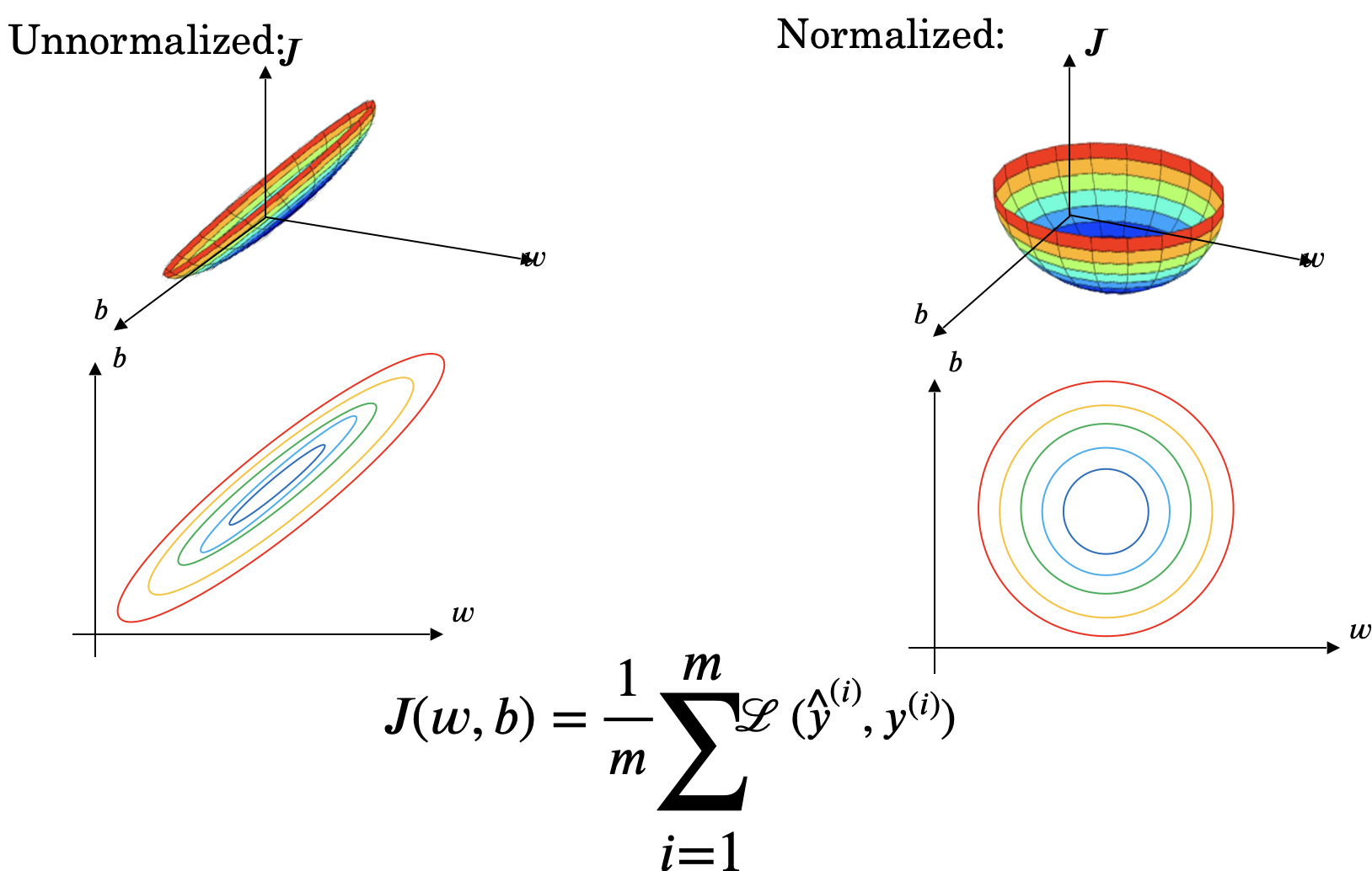
如果不同的 feature 数据之间 scale 比较大,比如0<x1<1000, 0<x2<1,此时将它们归一化将有更好的效果。另外需要注意的是,如果我们有test set,我们也需要用相同的$\mu$和$\sigma$来处理test set中的数据
Vanishing / Exploding gradients
梯度的消失和爆炸是指对于深层的神经网络,在 training 时导数值很大或者很小,从而导致 training 变得非常困难。假设我们有下面的 network,它由$l$个 full-connected layer 组成

我们用$\omega^{[i]}$表示每层的 weight 值,简单起见,我们另 activation 函数为线性函数$g(z) = z$,另 bias 为 0,则$\hat{y}$为
\[\hat{y} = \omega^{[l]}\omega^{[l-1]}\omega^{[l-2]}...\omega^{[2]}\omega^{[1]}X\]我们假设每个$\omega^{[l]}$的值都为
\[\begin{bmatrix} 1.5 & 0 \\ 0 & 1.5 \\ \end{bmatrix} or \begin{bmatrix} 0.5 & 0 \\ 0 & 0.5 \\ \end{bmatrix}\]当我们network层数非常多的时候,如果我们用左边的矩阵作为$\omega$,那么$\hat{y}$将会指数级增长($1.5^{l-1}$)。而对于右边矩阵,$\hat{y}$将指数级减小($0.5^{l-1}$)。这两者都会直接影响梯度下降的过程,求导过程中的导数值会同样的指数级增长和减小(当导数值很小的时候,梯度下降会很慢,降低收敛速度)
缓解梯度爆炸或者消失的一种解决方法是对 weight 进行随机初始化。我们先看只有一个 neuron 的情况,如下图所示
我们暂时忽略 bias,则$z=\omega_{1}x_{1}+\omega_{2}x_{2}+…+\omega_{n}x_{n}$
为了避免$z$过大或过小,我们一般用下面的方法对 weight 进行归一化,控制它们之间的variant值为$2/n^{l-1}$, $n$为输入features的数量, $l$为network的层级
W[l] = np.random.rand(layers_dims[l]) * np.sqrt(2/(n**(l-1)))
上述式子会将 weight 的均值归一化到 0 左右,not too bigger than 1 and not too much less than 1。当 activation 函数为Relu的时候,这个方法比较有效。如果用tanh,则可以将np.sqrt(2/(n**(l-1))) 替换为np.sqrt(1/(n**(l-1)))。
对weight值的随机初始化,虽然不能完全解决梯度爆炸或者缩小的问题,但是能够一定程度的缓解
Gradient checking
在 bacKprop 的过程中,如果我们不确定梯度计算的值是否准确,我们可以通过求导公式来验证
\[\frac{\partial J}{\partial \theta} = \lim_{\varepsilon \to 0} \frac{J(\theta + \varepsilon) - J(\theta - \varepsilon)}{2 \varepsilon}\]具体做法是,将 backprop 过程中得到梯度值$\frac{\partial J}{\partial \theta}$和上述公式求出的梯度值进行比较。比较方法是根据下面公式计算误差值
\[err = \frac{|| d\theta_{approx} - d\theta ||_2}{||d\theta_{approx}||_2 + ||d\theta||_2}\]一般误差的阈值为$\epsilon=10^{-7}$,则如果$err$能在$10^{-7}$左右说明,梯度计算正确,如果在$10^{-3}$则说明有较大的的问题。
Python 的伪代码如下
def gradient_check(x, theta, epsilon = 1e-7):
thetaplus = theta + epsilon
thetaminus = theta - epsilon
J_plus = forward_propagation(x,thetaplus)
J_minus = forward_propagation(x,thetaminus)
gradapprox = (J_plus - J_minus) / (2*epsilon)
# Check if gradapprox is close enough to the output of backward_propagation()
grad = backward_propagation(x, theta)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator
if difference < 1e-7:
print ("The gradient is correct!")
else:
print ("The gradient is wrong!")
return difference
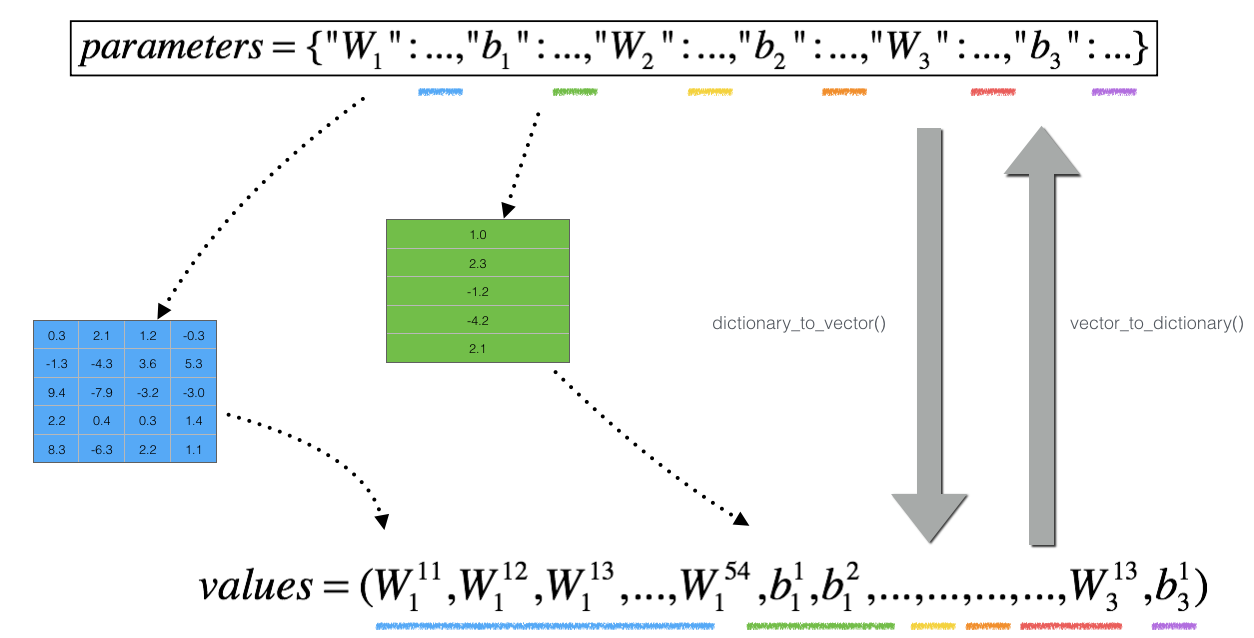
具体实现如下,假设我们有下面的 network:

我们将 $W^{[1]},b^{[1]},W^{[2]},b^{[2]},W^{[3]},b^{[3]}$ 存到一个 dictionary 里并转为一个 vector,称为 $\theta$, 如下图所示
则我们的 cost 函数变为
\[J(W^{[1]},b^{[1]},...,W^{[L]},b^{[L]}) = J(\theta_1,\theta_2,...,\theta_L ) = J(\theta)\]相应的,我们也需要将$d\theta$存到一个 vector 里,即$[dW^{[1]},db^{[1]},dW^{[2]},db^{[2]},dW^{[3]},db^{[3]}]$
接下来我们执行下面步骤
- 计算
J_plus[i]- 计算$\theta^{+}$ =
np.copy(parameters_values) - $\theta^{+} = \theta^{+} + \epsilon$
- $J^{+}_i$ =
forward_propagation_n(x, y, vector_to_dictionary(theta_plus))
- 计算$\theta^{+}$ =
- 重复上面步骤计算$\theta^{-}$和
J_minus[i] - 计算导数值 $gradapprox[i] = \frac{J^{+}_i - J^{-}_i}{2 \varepsilon}[i] = \frac{J^{+}_i - J^{-}_i}{2 \varepsilon}$
上述步骤完成后我们将得到一个gradapprox的 vector,其中gradapprox[i]代表对parameter_values[i]的导数。接下来我们需要将gradapprox[i]中的每一个导数值和$d\theta$中真正的导数值进行比较,具体做法是用前面提到的误差计算公式来计算其误差并和阈值$\epsilon=10^{-7}$进行比较。
Important notes:
-
Gradient Checking is slow! Approximating the gradient with $\frac{\partial J}{\partial \theta} \approx \frac{J(\theta + \varepsilon) - J(\theta - \varepsilon)}{2 \varepsilon}$ is computationally costly. For this reason, we don't run gradient checking at every iteration during training. Just a few times to check if the gradient is correct.
-
Gradient Checking, at least as we’ve presented it, doesn’t work with dropout. You would usually run the gradient check algorithm without dropout to make sure your backprop is correct, then add dropout.