几种常见的CNN模型
LeNet-5
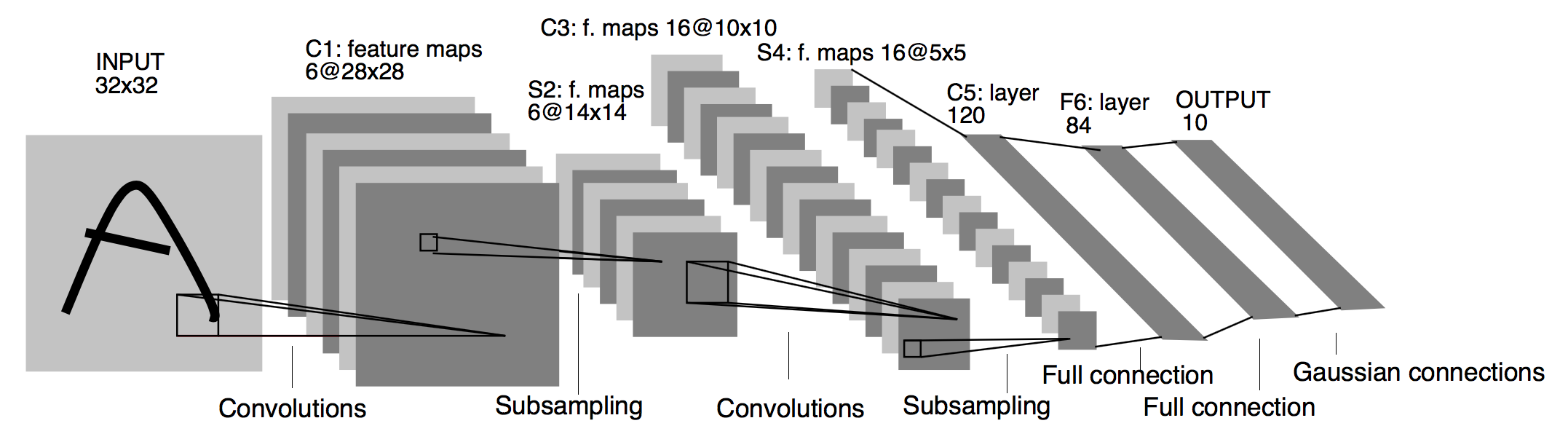
LetNet-5是Y.LeCun在1998年在的paper中提出的,被用来识别手写数字。这篇paper堪称经典,其结构前面已经文章中已经介绍过了,这里就不再重复。LeNet-5并不算复杂,只有60k个参数,相对今天的神经网络动辄几千万,甚至上亿个参数来说,还是比较初级的。但这个神经网络为后来的CNN奠定了雏形,并提供了不少最佳实践,比如随着网络的深入,输出图片的size越来越小,channel越来越深;conv layer后面跟随pooling layer,然后跟随FC等。其基本的参数如下
| layer | type | filter shape |
|---|---|---|
| 1 | input | 32 x 32 x 1 |
| 2 | conv2d | (5 x 5 x 1) x 6 |
| 3 | max pool | 2 x 2 |
| 4 | conv2d | (5 x 5 x 6) x 16 |
| 5 | max pool | 2 x 2 |
| 6 | conv2d | 400 x 120 |
| 7 | FC | 120 x 84 |
| 8 | FC | 84 x 10 |
AlexNet
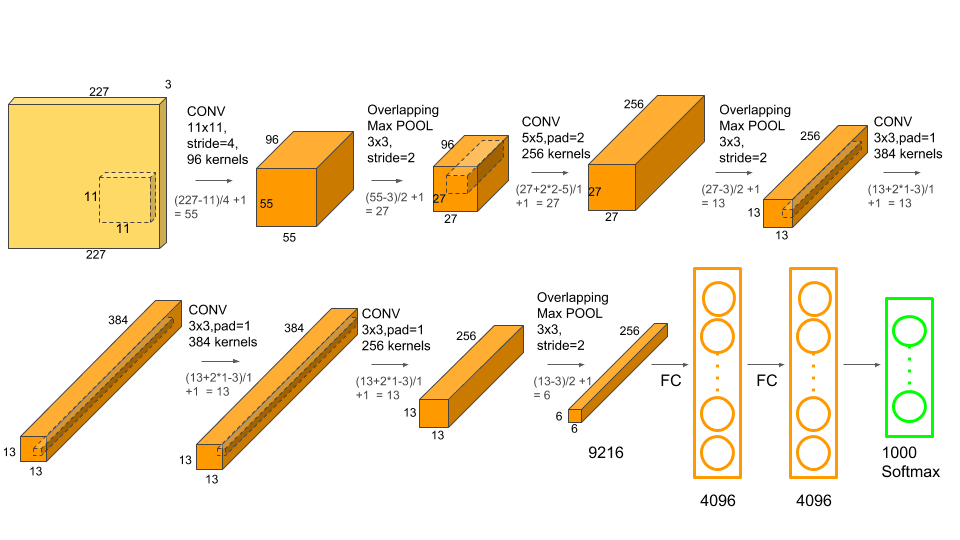
AlexNet是Alex Krizhevsky和他的导师Geoffrey Hinton在2012年的paper中提出的,并获得了当年的ImageNet冠军,识别成功率比第二名高出近10个百分点。相比于LeNet,AlexNet层次更深,有8层卷积层 + 3层FC层,参数更是达到了6千多万个。但它的独到之处还在于下面几点
- 使用ReLu作为激活函数。虽然这个选择在现在看来很平常,但当时是一个很大胆的创新,它解决了梯度消失的问题,使收敛加快,从而提高了训练速度
- 使用多GPU进行训练,解决了GPU间通信的问题
- 介绍一种归一化方式 - Local Response Normalization,后面被很多学者证明并不是很有效
Ale*Net的参数如下
| layer | type | filter shape |
|---|---|---|
| 1 | input | 227 x 227 x 3 |
| 2 | conv1 / Relu | 96 x 3 x 11 x 11 |
| 3 | LRN | 5 |
| 4 | max pool | 3 x 3 |
| 5 | conv2 / Relu | (5 x 5 x 96) x 256 |
| 6 | LRN | 5 |
| 7 | max pool | 3 x 3 |
| 8 | conv3 / Relu | (3 x 3 x 256) x 384 |
| 9 | conv4 / Relu | (3 x 3 x 384) x 384 |
| 10 | conv5 / Relu | (3 x 3 x 384) x 256 |
| 11 | max pool | 3 x 3 |
| 12 | FC | 256 x 4096 x 6 x 6 |
| 13 | Dropout | |
| 14 | FC | 4096 x 4096 |
| 15 | Dropout | |
| 16 | FC | 4096 x 1000 |
在AlexNet提出后,人们逐渐意识到使用CNN进行图像识别确实是一条可行的方法
VGG / VGG 16
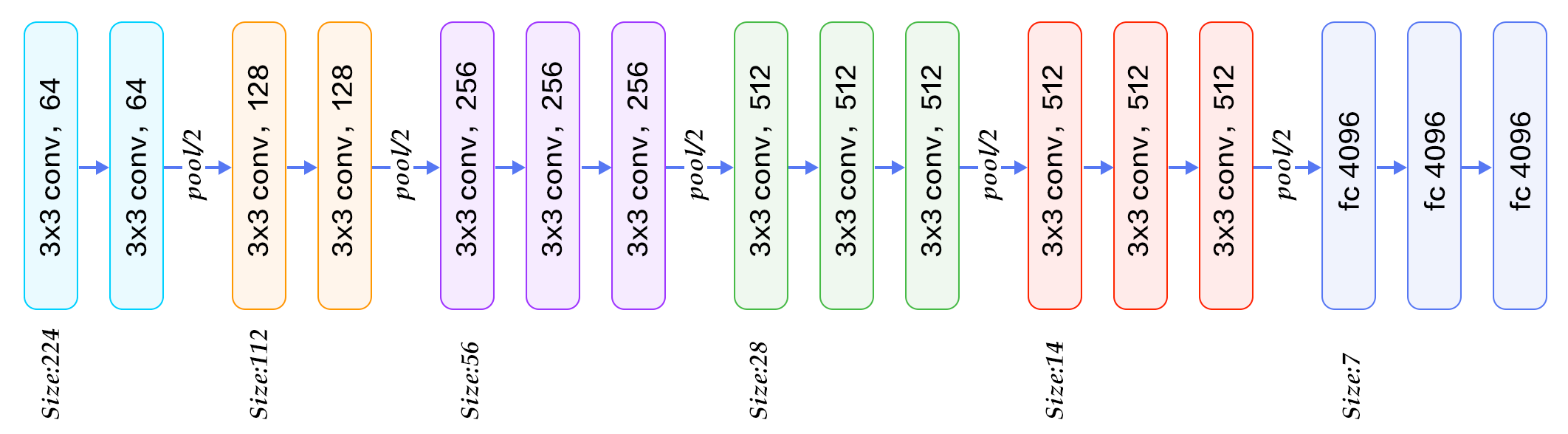
AlexNet发表后,业界对这个模型做了很多改进的工作,使得其在ImageNet上的表现不断提升。VGG是其中一个比较重要的改进,它在2014年的比赛中获得了第一名。VGG的最主要贡献在于通过加深网络层次,来得到更好的模型泛化能力,是一个真正意义上Deep Network。
在AlexNet之后,学术界一致认为,从理论上看,神经网络应该是层数越多,泛化能力越强。但实际中,随着网络的不断加深,往往会出现梯度消失和过拟合的情况出现,这使得加深网络十分困难。VGG通过一系列手段解决了这个问题,具体来说
- 对所有的卷积层统一使用
3*3,步长为1,相同padding的kernel - 对所有的pooling层,统一使用使用
2*2,步长为2的Max Pooling - 放弃了AlexNet中引入的LRN技术,原因是这个技巧并没有带来效果的提升
上图中是一个16层的VGG网络,看起来非常规则,因此也得到了一批研究人员的热爱,但是该结构一共有大约138million个参数,训练起来很有挑战
ResNet
前面曾提到过,随着网络的不断加深,会出现梯度“消失”或者梯度“爆炸”的情况。VGG虽然解决了一些问题,但研究人员也发现了一个现象,当将VGG不断加深,直到50多层后,模型的性能不但没有提升,反而开始下降,也就是准确度变差了,网络好像遇到了瓶颈。为了解决这个瓶颈,ResNet提出了残差网络(Residual Network)的概念,从而可以将模型规模从几层,十几层或几十层一直推到上百层的结构,且错误率只有VGG或GoogleNet的一半。这篇论文也获得了2016年CVPR的最佳论文,在发表后获得了超过1万2千次的引用。
注意,ResNet解决的不是梯度的爆炸或者消失,这两者可以已经通过Normalization解决了。ResNet真正要解决的问题是深层网路退化问题 (degradation)
我们先看看ResNet的模型结构是怎样的,假设我们有一个两层的FC网络如下图所示
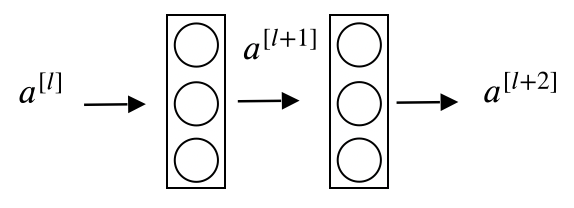
按照传统的NN求法,则有下面一些式子
\[z^{[l+1]} = W^{[l+1]}a^{[l]} + b^{[l+1]} \\ a^{[l+1]} = g(z^{[l+1]}) \\ z^{[l+2]} = W^{[l+2]}a^{[l+1]} + b^{[l+2]} \\ a^{[l+2]} = g(z^{[l+2]}) \\\]也就是说,如果想要得到$a^{[l+2]}$,必须要经历上面4部求解过程。而Residual Network则直接将$a^{[l]}$作为Residual Block加入到了下一层网络的末尾,如下图所示
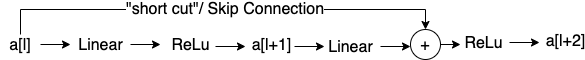
则$a^{[l+2]}$变成了
\[a^{[l+2]} = g(z^{[l+2]}+a^{[l]})\]推而广之,如果我们有一个下图中的”Plain Network”,我们可以将下面的layer两两形成一个Residual Block,进而组成了一个Residual Network

咋看一下有些奇怪,为什么这种结构就能解决深层网络的退化问题呢? Andrew Ng在课程中对这个问题讲得不是很清楚。简单来说,深层网络在训练的过程中是有”损耗的“。论文中提到了所谓的恒等映射,即如果某一层神经网络的输出等于输入,我们称这一层为恒等变换。那么理论上来说,给一个浅层网络叠加上若干层恒等变换的layer,输出结果应该不会有变化,而实际结果却不是。这其实很好理解,对于神经网络的每个神经元,其activation函数是非线性的,会对输入做非线性变换,这个变换是不可逆的。从这个角度看,ResNet的初衷是让神经网络至少具备恒等映射的能力,以保证在堆叠网络的过程中不产生退化。
由于篇幅有限,这里不做过多的展开,感兴趣的可以去直接读论文。结论是,通过ResNet,我们可以将神经网络的层数扩展到100层以上,根据论文中的数据,作者们尝试了做多1202层的网络,最终发现在110层时能达到最优的结果。
Inception Network
Inception Network也就是GoogLeNet,首次出现在2014年的ILSVRC比赛中,并获得冠军。这个版本是Inception Network的第一个版本,深度为22层和同时期的VCC相比性能差不多,但是参数却只有5M个参数,远远小于VGG。
Inception Network的基本思想是使用不同尺寸的卷积核提取图片信息,然后对这些信息进行融合,从而达到更好的提取图片特征的效果。具体来说,Inception网络中的重要概念是所谓的构建Inception Module,每个Module包含四部分,1*1卷积,3*3的卷积,5*5的卷积,3*3的pooling,以及最后对四部分的运算结果进行通道上组合,如下图所示。
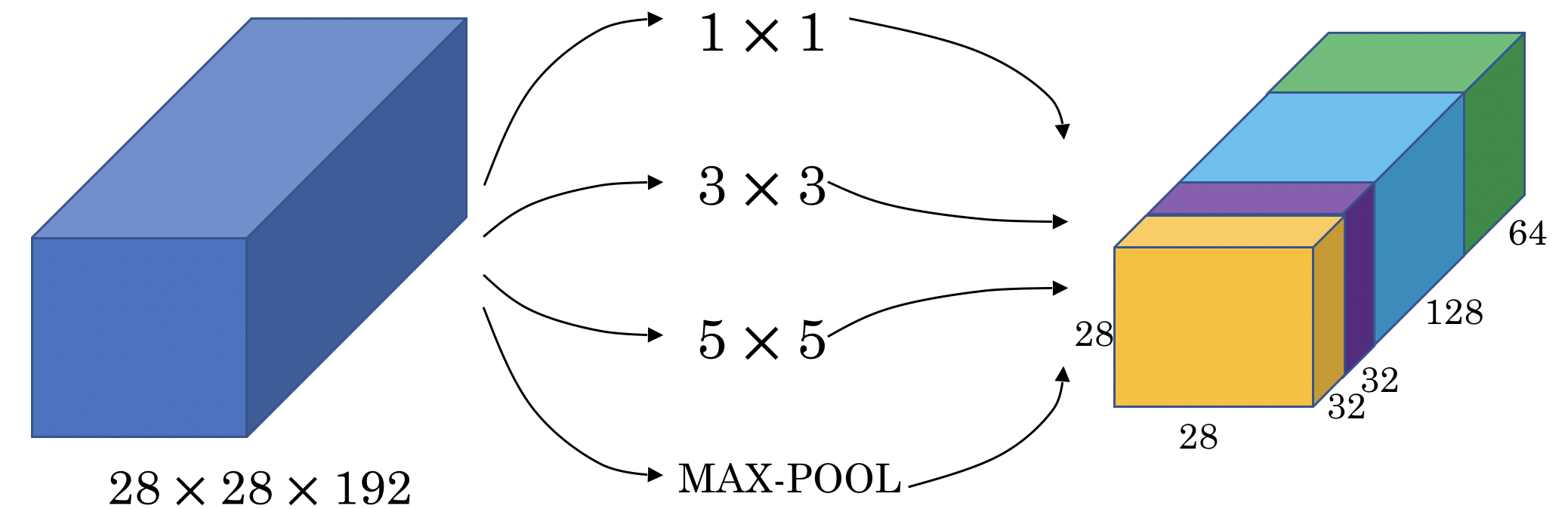
上面的Module如果不做优化,存在计算量过大的问题,以5*5的卷积为例,一次卷积要做大约120m次乘法,其原因在于融合之后的数据维度太高。
为了解决这个问题,需要引入1*1卷积的概念。所谓1 * 1卷积,顾名思义就是卷积核的尺寸为1 * 1 * depth,它的作用在于对数据的降维。在前面文章中可知,Pooling layer可以用来减少输数据水平和竖直尺寸,1 * 1的卷积可以帮我们减少输入数据的维度。
上面例子中,我们可以让一个28 * 28 * 192的数据先与一个1 * 1 * 192的卷积核进行卷积(16卷积核),将得到一个28 * 28 * 16的二维数据,再对这份数据进行 5 * 5 * 16 的卷积核卷积(32个卷积核),得到28 * 28 * 32的数据。经过上述处理后,计算量为12.4m,降到了原来的十分之一。
所谓的Inception网络就是若干个这些Module的级联,如下图所示
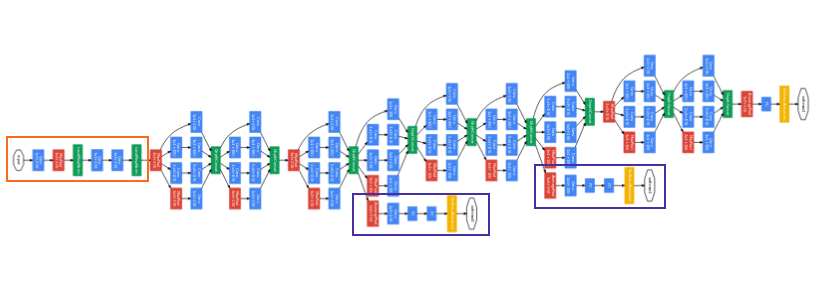
注意到图中矩形圈出的部分是一个分支,它可以用来观察对应layer的预测结果,以便观察最终结果是否overfitting
MobileNet
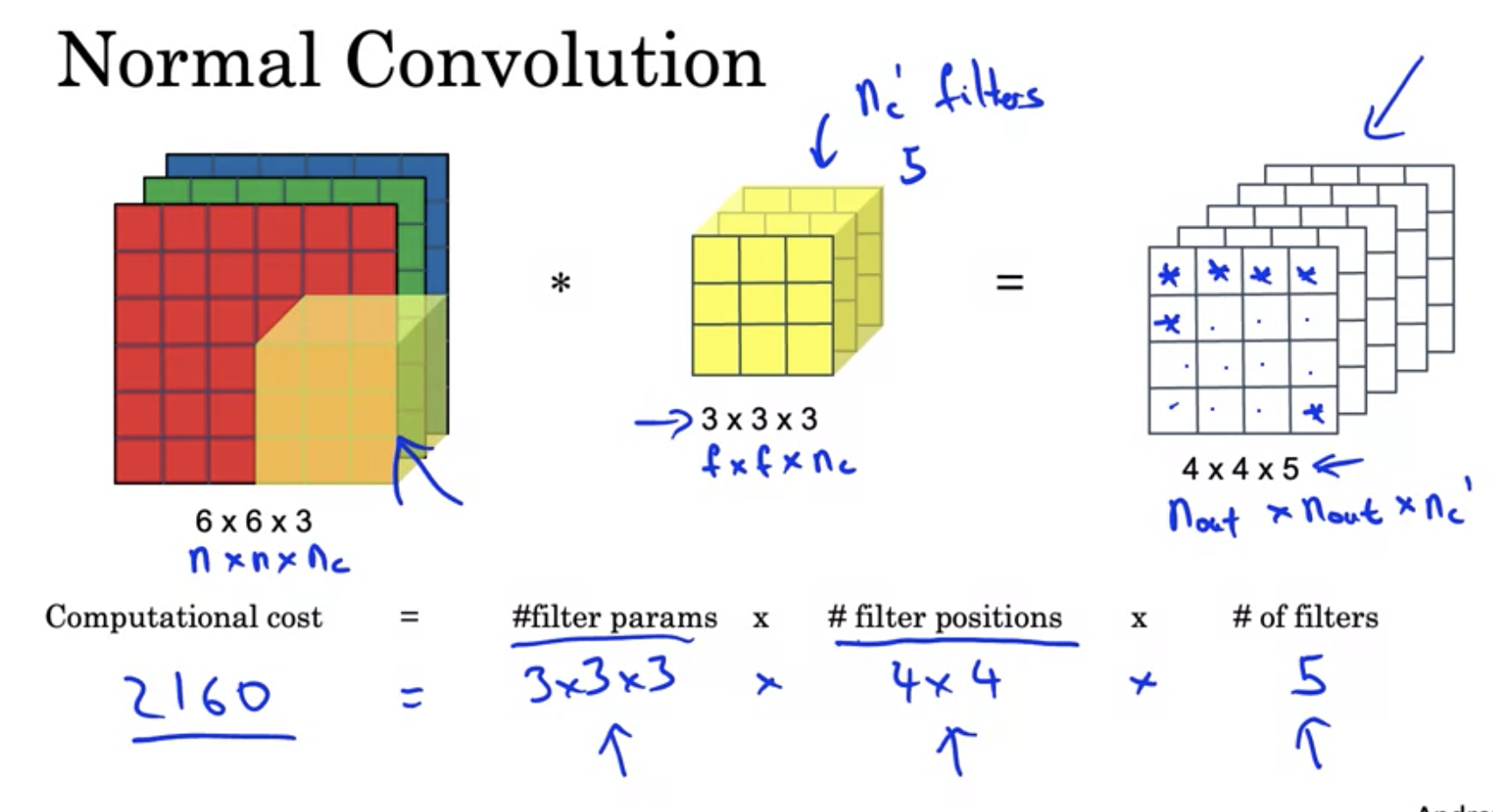
MobileNet的核心在于使用Depthwise-separable convolution来减少运算量。对于一次普通的conv操作,其运算量如下图所示
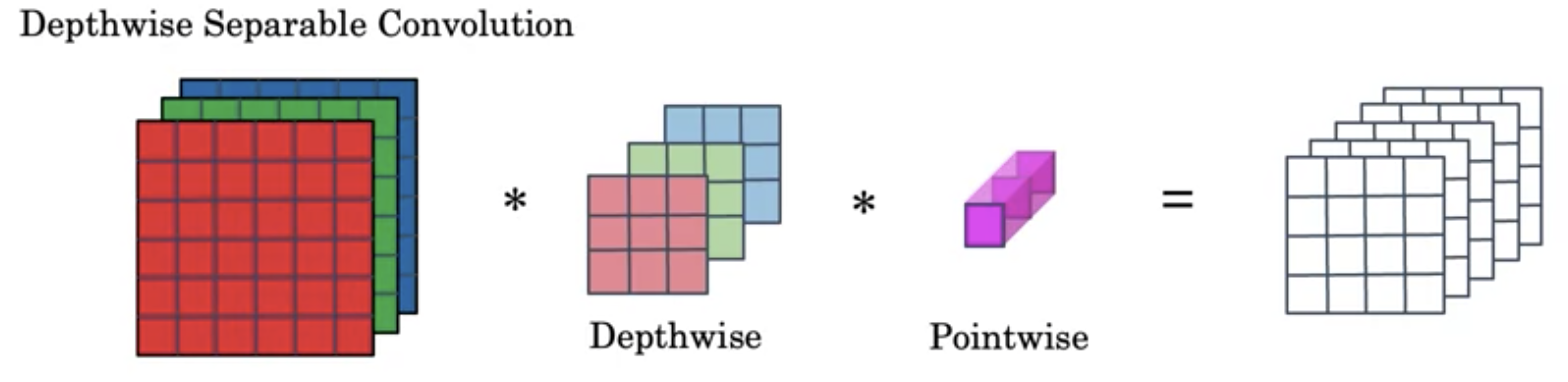
Depthwise-separable conv将卷积分成了两步
- 使用Depthwise conv将每个channel和kernel分别做卷积
- 使用一个1x1的Pointwise conv将上一步得到的中间结果进行卷积
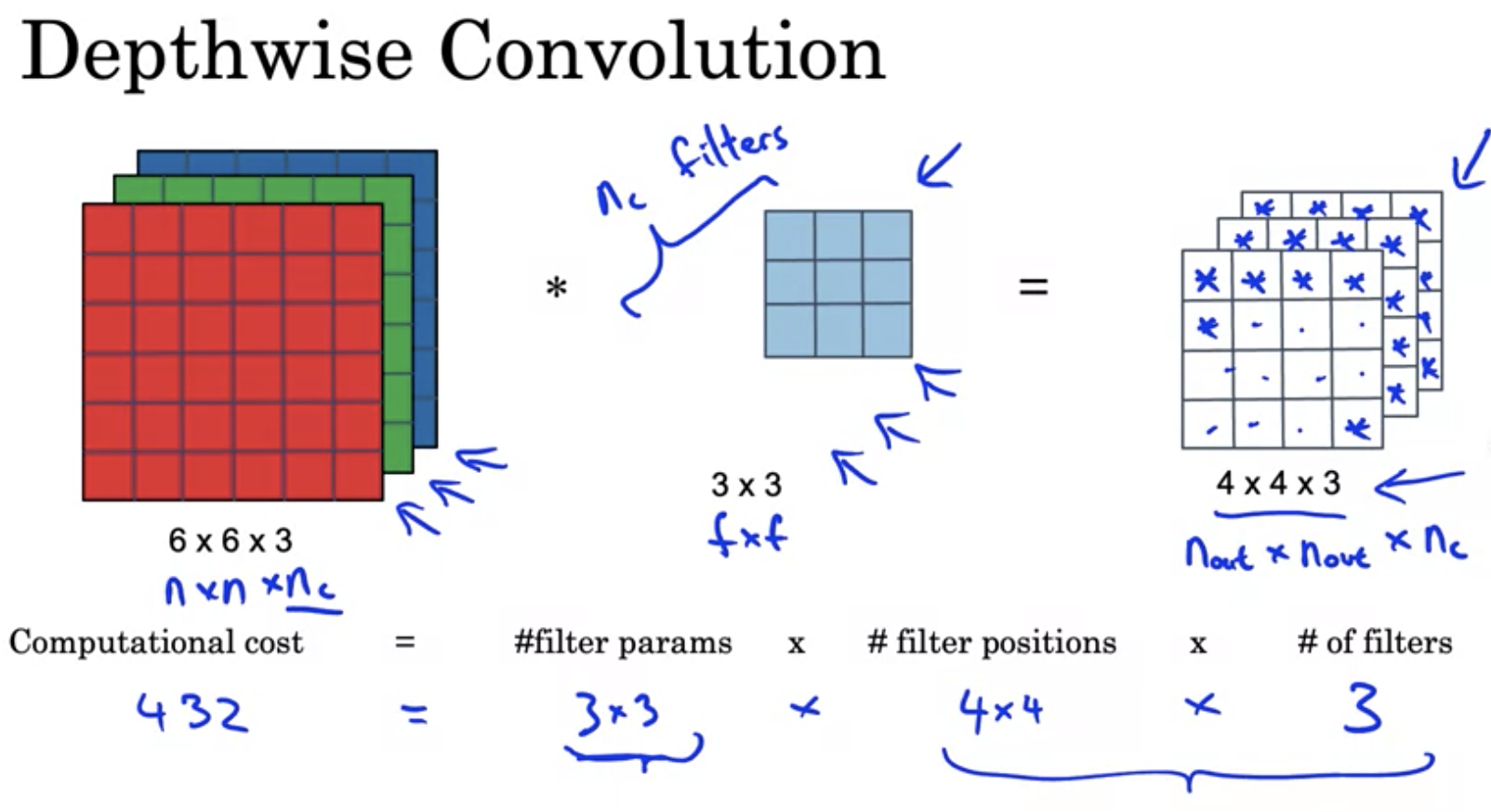
其中, Depthwise conv的计算量为
Pointwise conv的计算量为
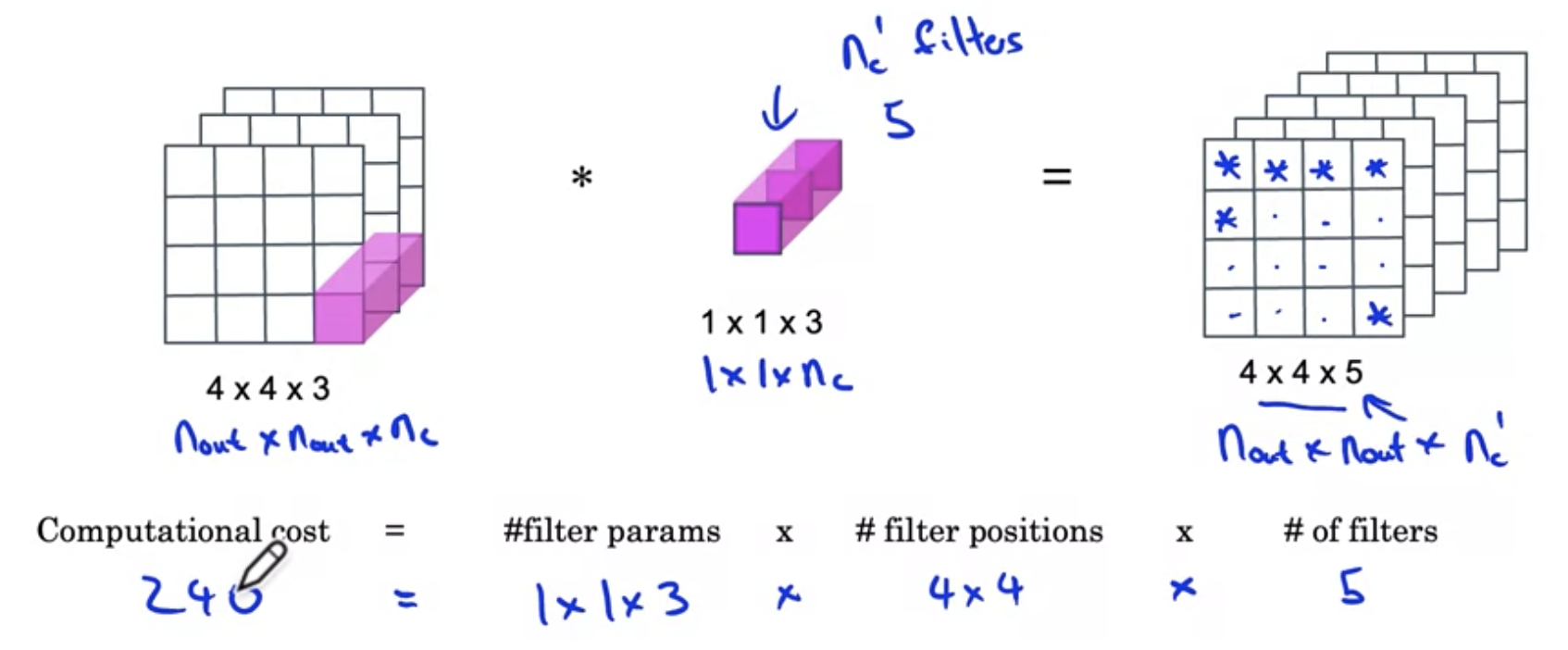
对比计算量可知,在上面的例子中$n_c^{‘} = 3$使用mobilenet减少了大约70%的计算量。Paper中给出的计算公式为
\[p = \frac{n_c^{'}}{1} + \frac{f^{2}}{1}\]实际中,$n_c^{‘}$一般很大,比如512,而$f$一般为3,大多数conv的kernel是3x3的。因此mobilenet的计算量大约为普通conv的十分之一
整个MobileNet的结构也非常的straitforward,它由13个(depthwise-conv + pointwise + conv)的block组成,然后是pooling, FC和softmax用来做classification。
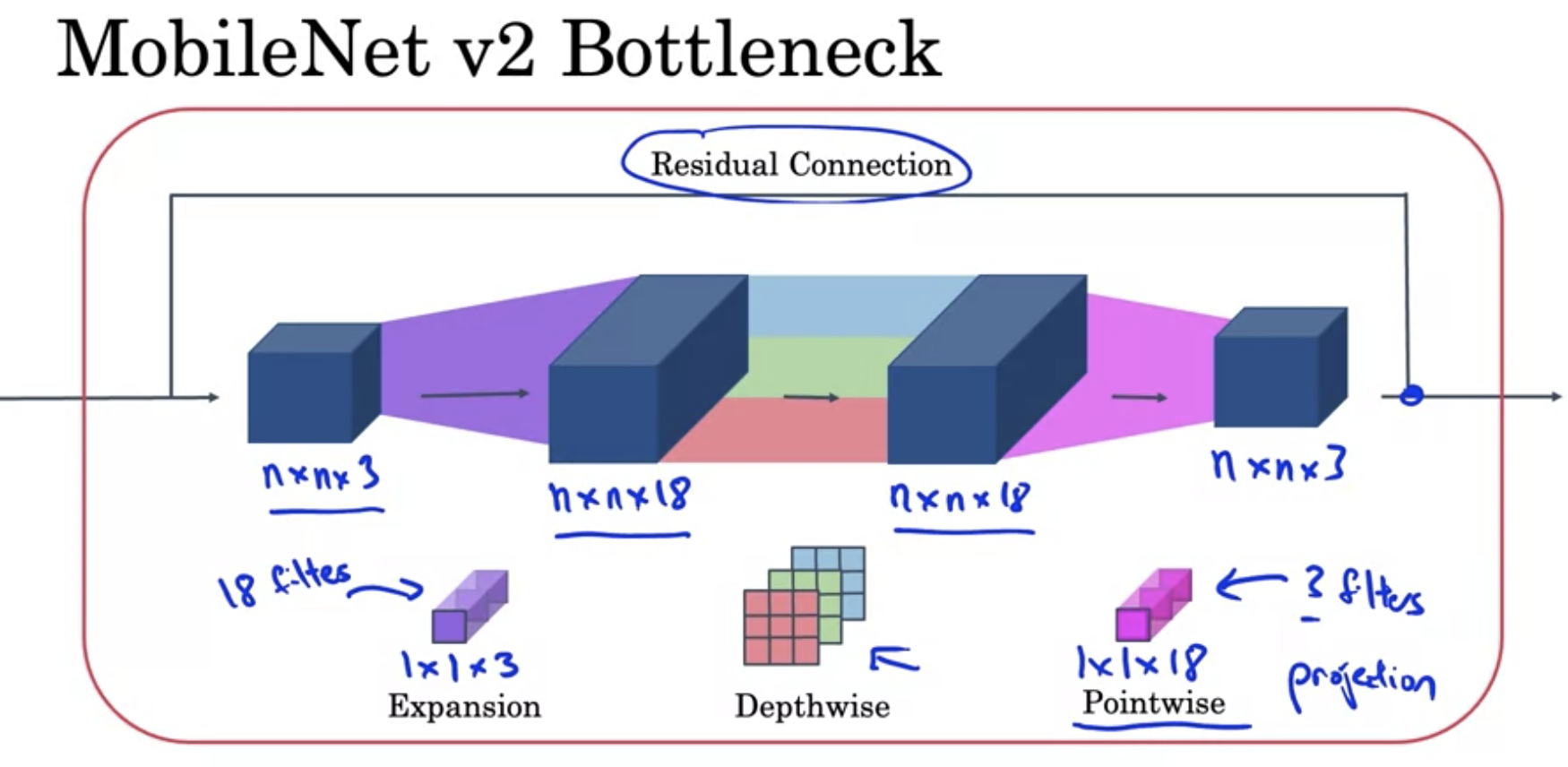
MobileNetv2
MobileNetv2在v1的基础上做了两点改进
- 引入了Resnet的Residual Connection
- 增加了Expansion的layer
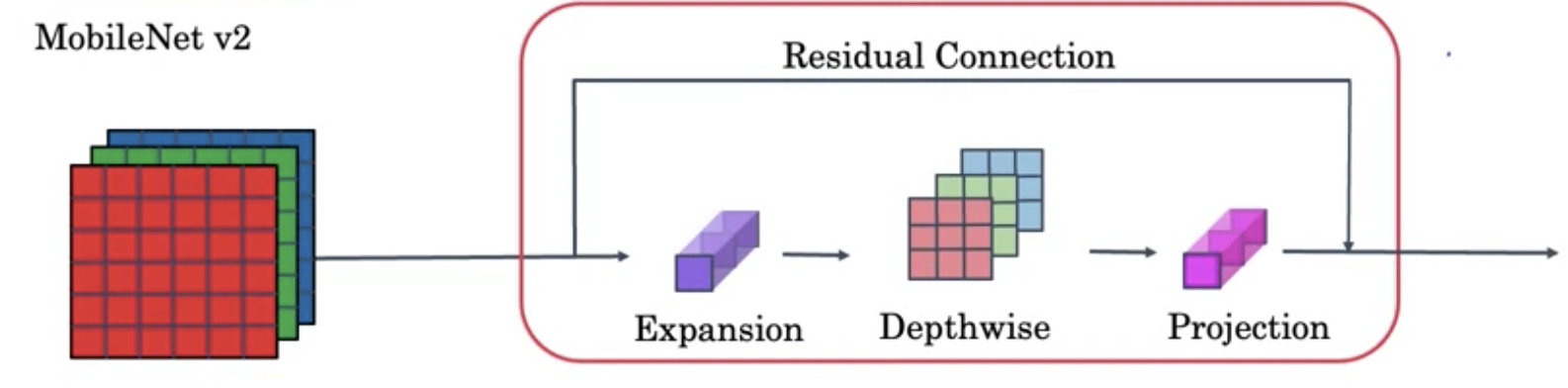
上面红色的block也叫做Bottleneck block,整个mobilenetv2的结构由17个bottleneck的block组成,followed by pooling, FC and Softmax for classification.
其中的第一个1x1 pointwise conv(a.k.a Expansion layer)将channel增加到18,最后一个1x1 pointwise conv将channel shrink到3