
Object Detection - YOLO
目标检测指的是给定一个输入的图像,我们希望模型可以分析这个图像里究竟有哪些物体,并能够定位这些物体在整个图像中的位置,对于图像中的每一个像素,能够分析其属于哪一个物体。它包含两部分,一部分是对图像内容的识别,也就是分类问题,另一个是标记目标在图像中的位置,也就是定位的问题。因此,神经网络的输出也包含了更多的信息,除了包含物体的类别外,还需要包含矩形框的位置信息。
Sliding Windonw Detection
一种容易想到的目标检测方式是使用滑动窗口,我们用一个矩形窗口依次滑过图片中的每个区域,每个窗口通过一个已经训练好分类模型(比如Resnet,GoogLnet等)进行图片识别,如下图所示

这种方式的问题在于计算量太大,对于每个窗口都需要单独计算。举例来说,上图中的窗口大小为一个14*14*3,现在这个窗口向左,右和右下各滑动一次,假设步长为2,则需要进行四次模型运算,得到4个结果
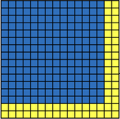
在参考文献[1]中提到了减少计算量一个方案是将原来神经网路中的FC层变成卷积层,如下图所示

还是上图中的滑动窗口,滑动步长为2,则4次滑动运算只需要一次即可完成

此时得到结果是一个2*2*4的矩阵,包含了当前位置,右边,下边和右下共4组计算结果。实际上这种方式是将上面4次单独计算合并成了一次。推而广之,假如我们有一个更大的的滑动窗口(28*28*3),一次运算,我们可以得到64组运算结果

再进一步扩大,我们可以让一个图片等同于一个滑动窗口,因此只进行一次模型运算即可
YOLO
上述算法虽然解决了计算效率问题,但是没有解决对目标矩形的定位问题,例如,上面算法中,我们完全有可能碰到这种情况,即没有任何一个窗口能完全覆盖检测目标,如下图所示

解决这个问题,参考文献[2],即YOLO算法提供一个不错的思路。YOLO将一张图片分割成$n$*$n$的格子,如下图中$n=3$,即9个格子
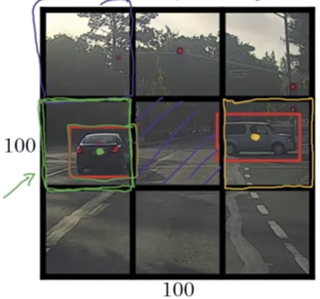
在数据标注的时候,我们将待检测目标的中心赋予某一个box,比如上图中的黄点和绿点。然后对该box用下面的一个向量表示
\[y = [ p_c, b_x, b_y, b_h, b_w, c_1, c_2,c_3 ]\]其中,$p_c$表示该box中是否有待检测的目标,如果有$p_c$为1,否则为0,$(b_x, b_y, b_h, b_w)$表示目标矩形,其中每个box的左上角为(0,0),右下角为(1,1)。$(b_x,b_y)$表示目标的中心点,$(b_h, b_w)$表示矩形框的高和宽相对于该box的百分比,如下图所示
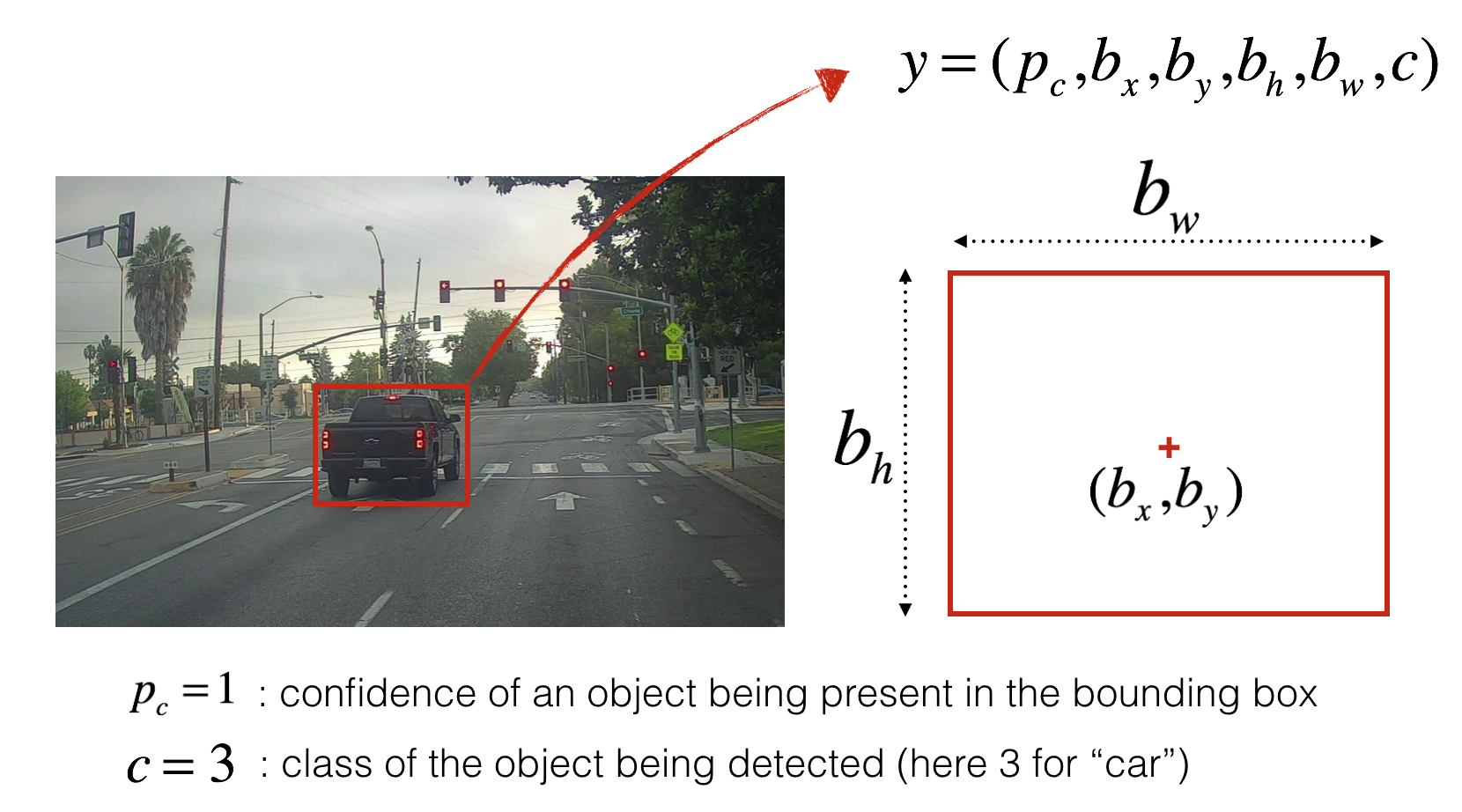
最后$c_1, c_2,c_3$表示目标类别,比如上图中$c_1$表示行人,$c_2$表示车辆,$c_3$表示摩托车,则上图中黄色box的$y$值为
\[y = [1.0, 0.3, 0.4, 0.9, 0.5, 0, 1, 0]\]因此,YOLO模型的输出便是9个上述目标向量,即3*3*8的矩阵。由于存在$(b_x, b_y, b_h, b_w)$的值,使得YOLO可以精确的计算出bounding box的位置,注意到 $(b_x,b_y)$必须在格子内,因此它们值在0到1之间,但是$(b_h,b_w)$可以大于1,因为可能存在目标物体比当前box大的情况。实际应用中,往往将一张图片分成19*19的格子,输出变为19*19*8,这降低了多个目标被分配到同一个格子的概率。
IoU
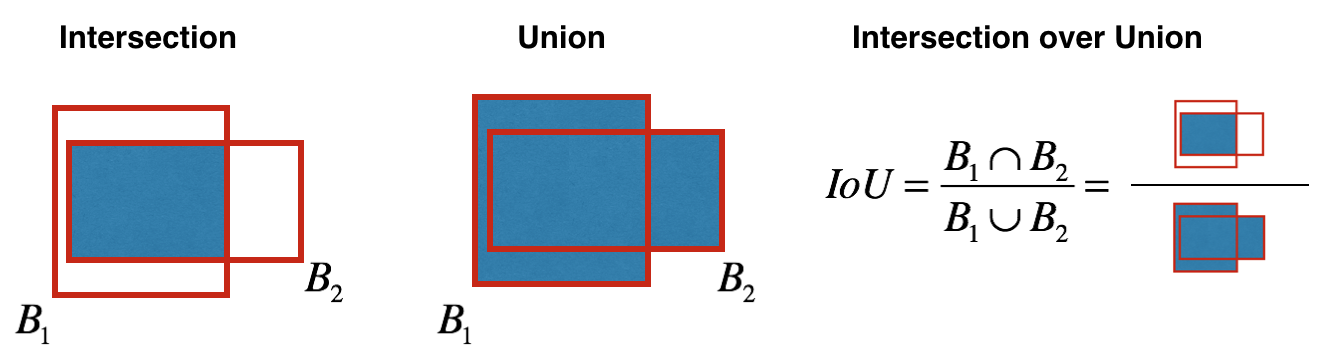
我们该如何衡量目标检测的准确率呢,比如下图中目标矩形为红色,而实际检测结果却为紫色矩形。

此时我们要引入一个指标叫做Intersection Over Union (IoU)。它的计算方式为用两个矩形的Intersection部分除以它们的union部分,得到的比值作为准确率。如果IoU的值大于0.5,则认为识别的区域是正确的。当然0.5这个值可以根据实际情况进行调节。
Non-Max Suppression
实际应用中的另一个问题是对于图片中某个目标,我们的模型可能有多个box输出的$p_c$值都大于0.1,即都认为自己得到的是正确的bounding box,如下图所示

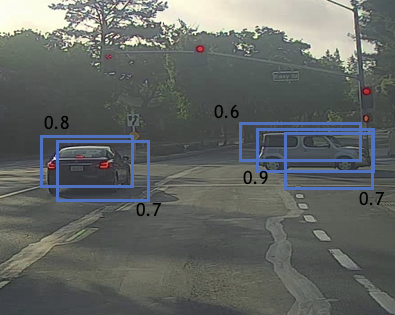
上图中左边是我们的输入图像,根据YOLO算法,将其分为19*19个格子,右边是模型的输出,可见有多个$p_c$值符合条件的矩形,这时我们要用一种叫做Non-Max Suppression的算法来选出唯一的bounding box,步骤如下
- 首先去掉$p_c$值小于0.6的bounding boxes
- 在剩下的box中,选取$p_x$最大的
- 在剩下的box中去掉那些IoU值大于0.5的
- 重复第二步
在第一步中,我们常用score代替$p_c$作为筛选条件,Score的计算方式如下图

上图中,我们假设有一组box1的预测结果,其中$p_1$为$0.6$,说明box1有60%的几率有目标。我们用这个值乘以$c_1…c_80$,例如$Score_{c_3} = 0.6 \times 0.73 = 0.44$。然后再这个80个类别中找出score最大的类别标记在box1上
Anchor Boxes
前面我们每个box只负责一个目标的检测,但有时候会出现多个目标的中心点集中在同一个box里的情况,如下图所示

此时我们的标注$y$需要包含两个box的信息
\[y = [p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3, p_c, b_x, b_y, b_h,b_w, c_1, c_2, c_3]\]我们可以用前8个元素表示第一个anchor box(图中垂直的),后8个元素表示第二个anchor box(图中水平的),因此模型的输出变成了3*3*16。以图中标注的两个矩形为例,则该box的$y$如下
\[y = [1, b_x, b_y, b_h, b_w, 1, 0, 0, 1,b_x, b_y, b_h,b_w, 0, 1, 0]\]那么如果这个box中有三个目标呢?目前这种情况很少见,YOLO还不能很好的处理这种情况。实际上同一个box中出现两个目标的情况也比较少见。
YOLO Recap
在引入了Anchor Box之后,一个完整的YOLO模型如下图所示
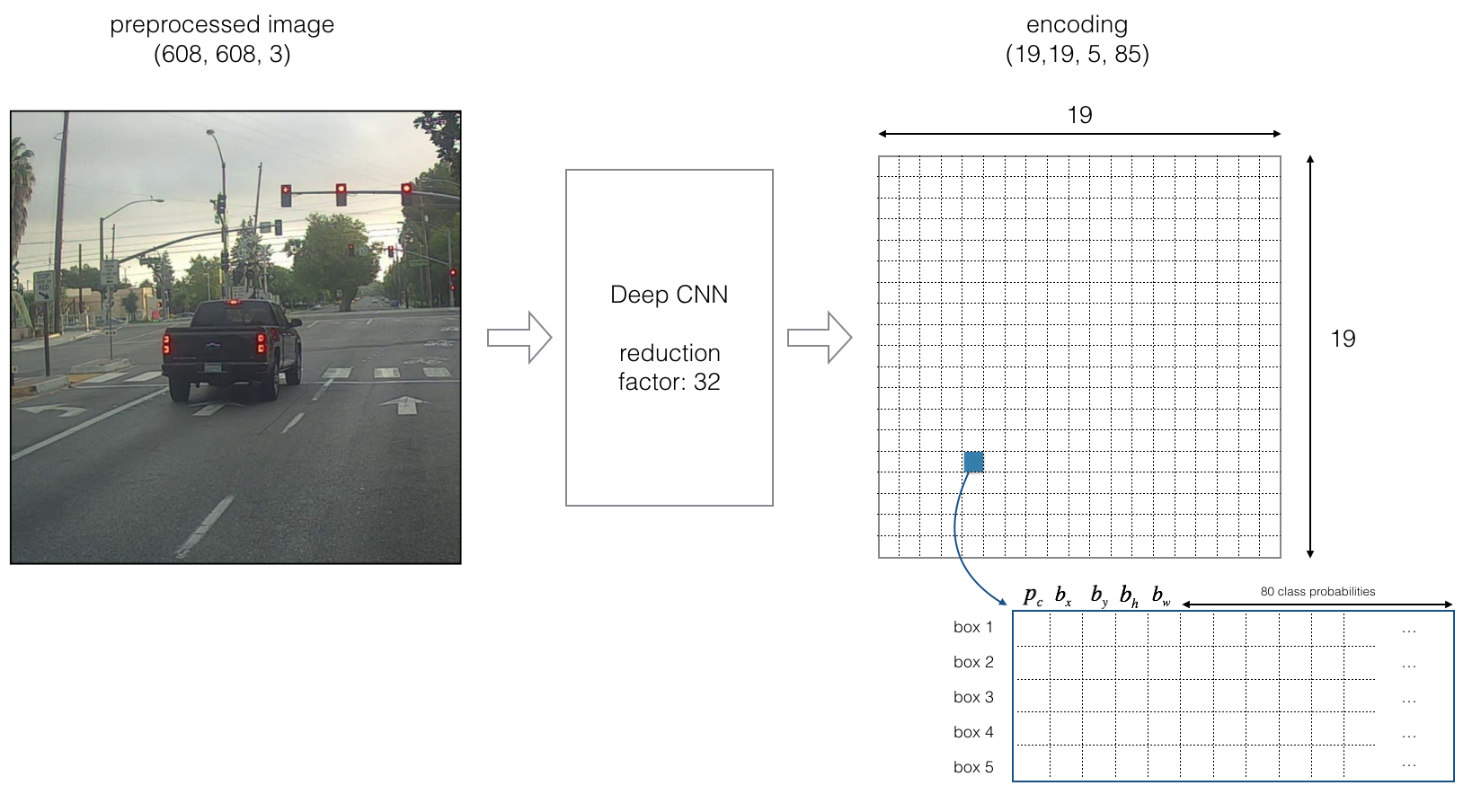
上面模型中的输入为(608 * 608 * 3)的图片,输出为(19 * 19 * 5 * 85 )的矩阵。可以该模型使用了5个Anchor Box,每个box的$y$除了包含$p_c$和$(b_x,b_y,b_h,b_w)$外,还有80个类别。
Resources
- Fully Convolutional Networks for Semantic Segmentation
- OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
- YOLO
- You Only Look Once: Unified, Real-Time Object Detection
- Deep Learning Specialization Course on Coursera
- Deep Learning with PyTorch
- Understanding Region of Interest — (RoI Align and RoI Warp)
- Understanding Region of Interest — (RoI Pooling)