
Object Detection - Mask R-CNN
在Objective Detection上比较有名的model是R-CNN以它相关的变种。下面简略介绍一下其实现的思路
R-CNN
R-CNN是Region-based Convolutional Neural Networks的缩写。其主要的思路是
- 找一个Pre-trained的CNN network作为backbone
- 通过selective search为一张图片生成约2000个RoI,每个RoI大小不同
- 由于生成RoI尺寸大小不同,我们需要将它们warp成一个固定大小的矩形,作为后面CNN网络的输入。注意warp相当于对原矩形区域的图片进行缩放,而不是截取。
- 将每一个warp后的RoI输入Pre-trained CNN model得到feature map (fc7)
- 将feature map通过binary SVM classifier进行分类
- 将类型判断正确的RoI进行通过一个bbox regression model进行校正。
整个过程如下图所示
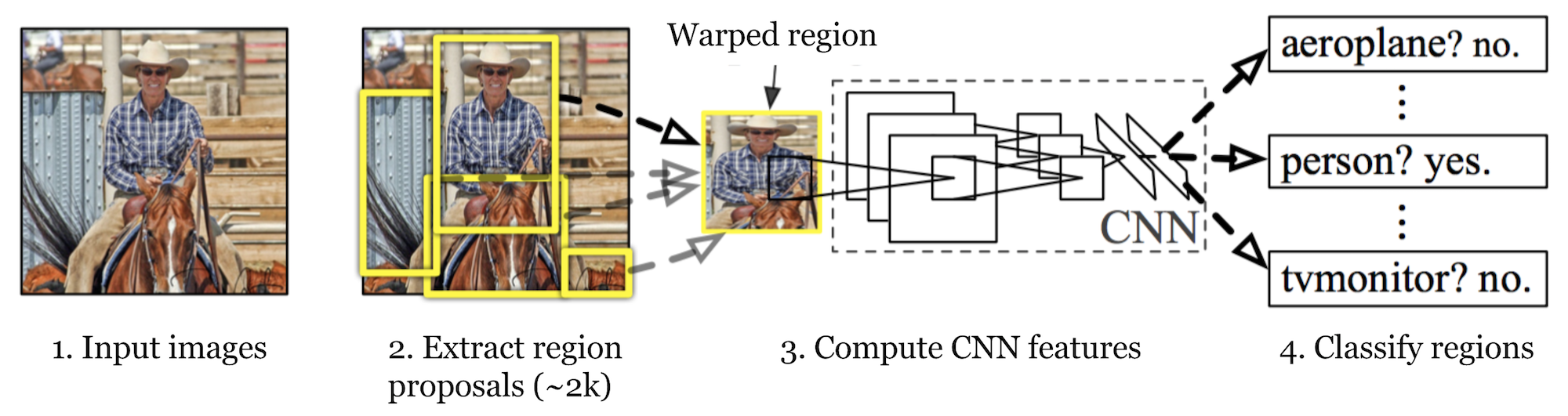
R-CNN虽然能完成目标检测的任务,但是速度却非常的慢
- 有2000个region proposal, 训练需要84小时
- 如果用vGG16,一次inference需要47s
- 整个过程需要三个Model,一个feature extraction的CNN model,一个SVM的classifier和一个bounding box的regression model
Fast R-CNN
为了解决R-CNN的性能问题,Fast R-CNN将上面三个model整合成了一个。其流程为
- 找一个Pre-trained的CNN network作为backbone
- 通过selective search为一张图片生成约2000个RoI,每个RoI大小不同
- 调整Pre-trained的CNN model
- 将model最后一个max pooling layer替换为RoI pooling layer。RoI Pooling会输出一个组fixed-length的feature vectors
- 将model最后一个FC+softmax(K classes)替换为 FC+softmax(K+1 classes)
- model最后有两个输出,分别为
- 每个RoI的class概率
- 一个bbox的regression model用来对RoI进行校正(按照class分类)
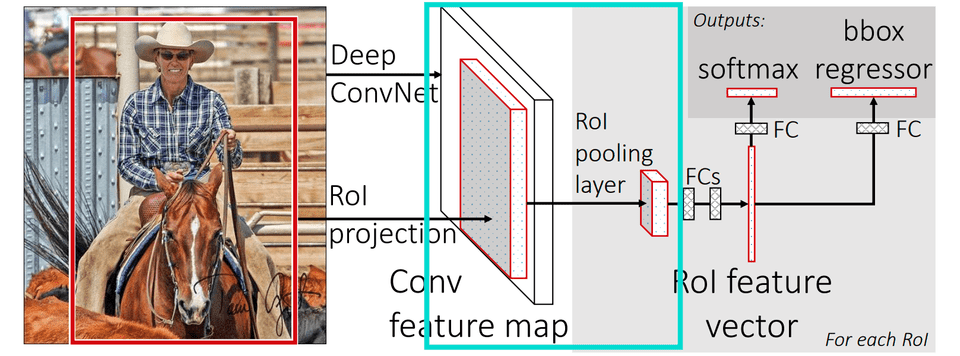
总的来说,Fast R-CNN最大的提升在于它对feature map的提取是一次完成的,而不像R-CNN需要将每一个RoI单独计算,这大大节省了计算资源,提高了计算速度。另一个需要掌握的重点是Fast R-CNN使用了RoI Pooling,其原理如下
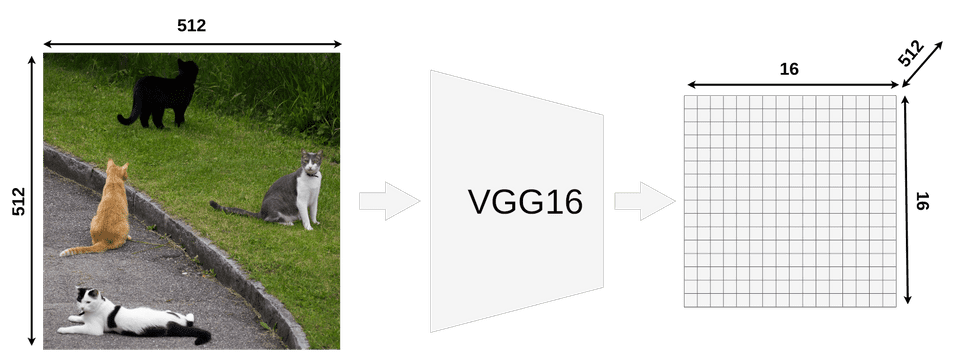
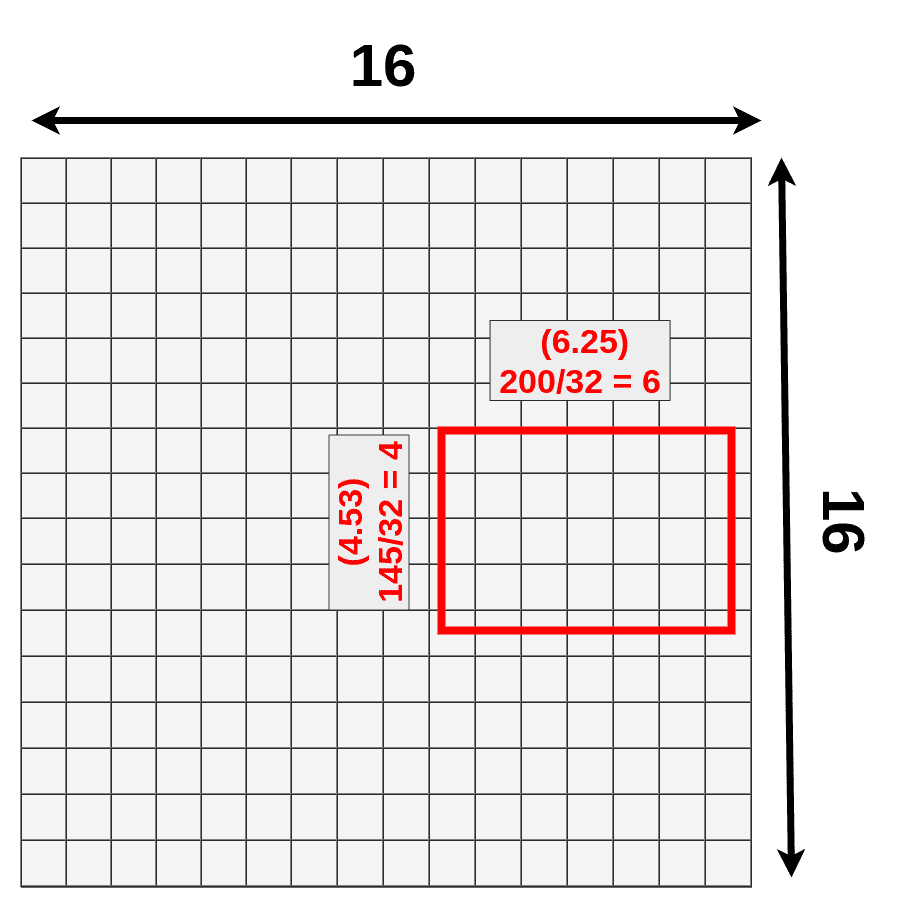
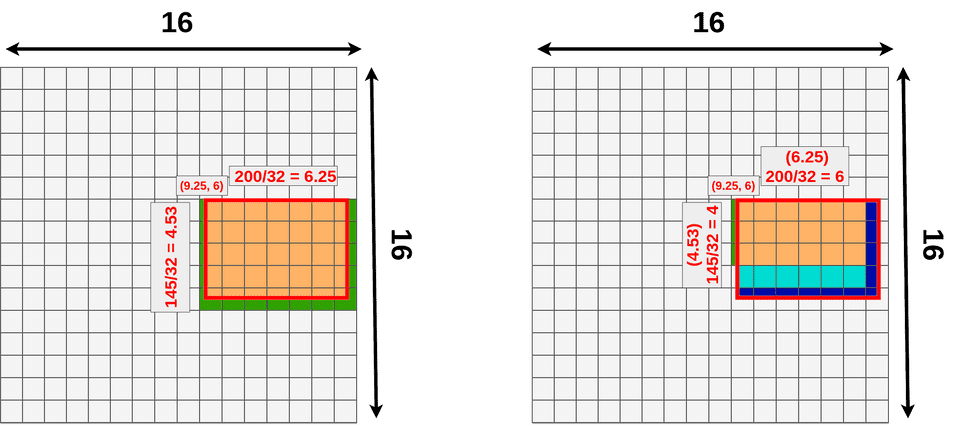
我们首先为每张图片生成大概2000个RoI。然后用一个feature extractor(论文中使用的VGG16)的到feature maps。例如,一张(1, 3, 512, 512)的图片经过CNN网络后得到一组(512, 3, 16, 16)的feature map。
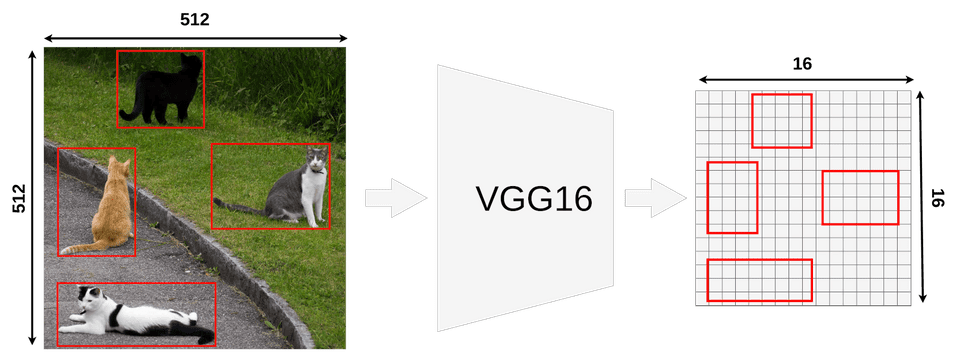
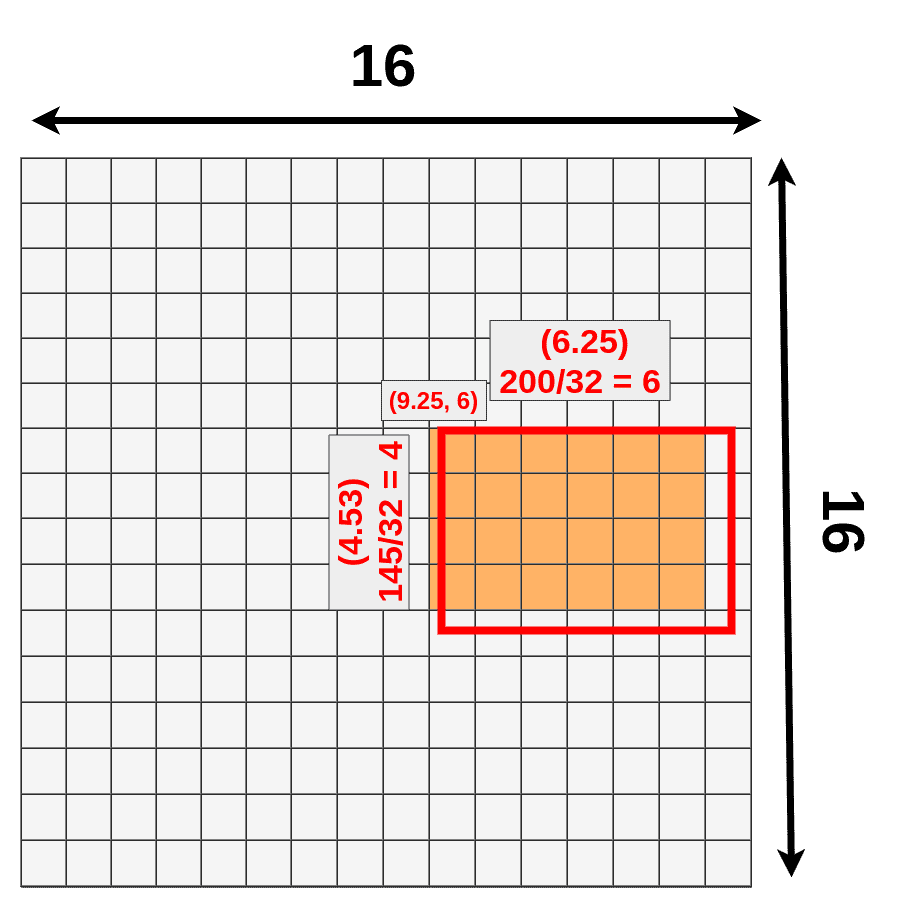
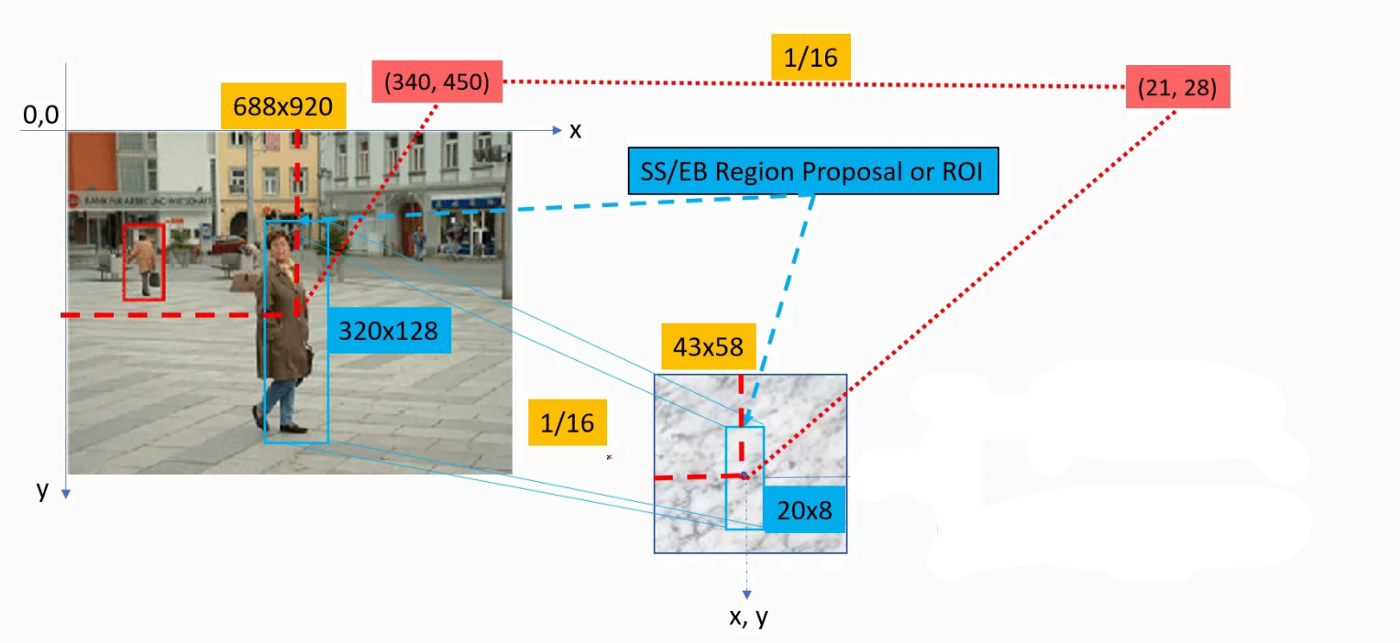
接下来我们要对从feature maps中提取RoI,由于我们之前生成的RoI尺寸是基于图片的原始尺寸(512, 512),而此时的feature map的大小已经从(512, 512)变成了(16, 16), 因此我们的RoI区域也要等比例缩小。例如一个(x:296, y:192, h:145, w:200)的bounding box在feature map中将变成(x:9.25, y:6, h:4.53, w:6.25 )如下图所示
此时我们发现bbox出现了小数,我们需要其quantize成整数,但是这会损失一部分数据,如下图三中的深蓝色部分所示
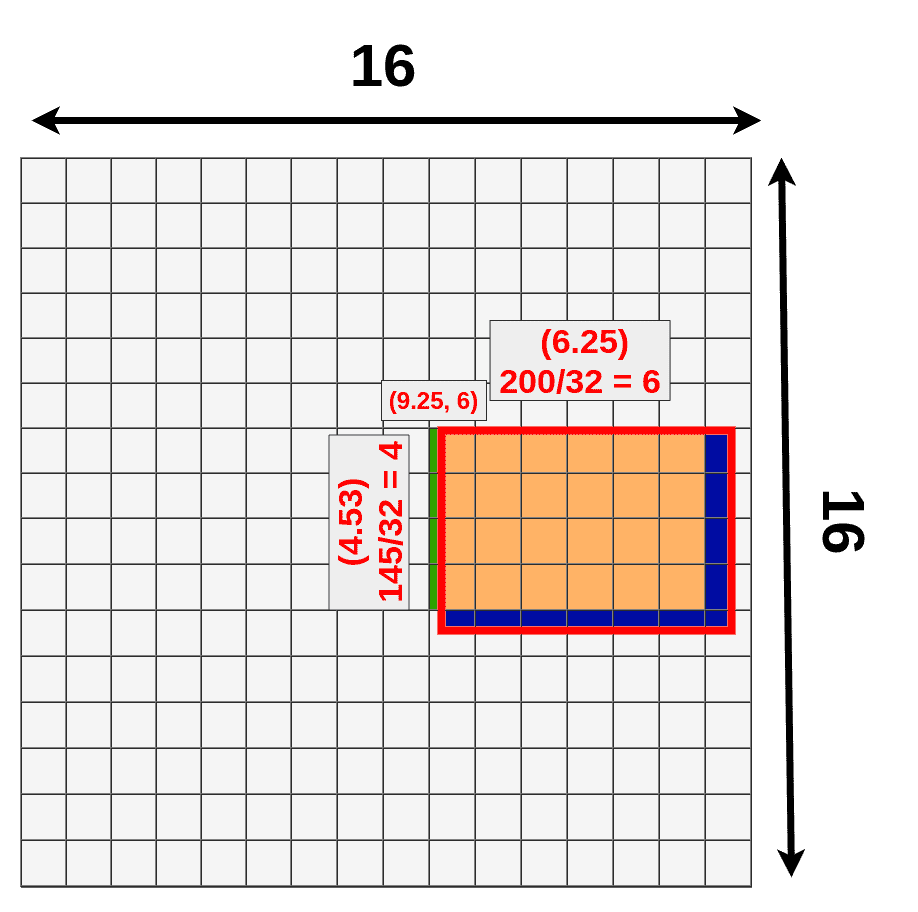
接下来我们要对RoI中的像素进行RoI Pooling,其目的是将各种大小不一的bbox映射成长度统一的vector以便进行后面的FC。具体做法是使用max pooling,还是上面的例子,经过quantization后,我们的bbox变成了4x6的,接下来我们用max pooling把它映射成3x3的,如下图所示
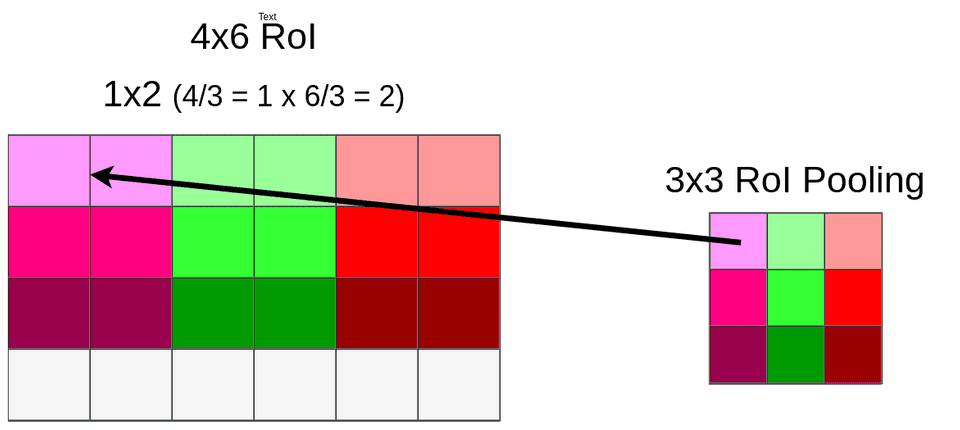
上图中我们发现最下面一行数据也被丢弃掉了,这是由于在竖直方向上,4无法整除3。通过RoI Pooling我们可以得到一组($roi,512,3,3)的feature map,这也是后面FC层的输入,最终通过两层FC我们得到了两个输出结果,一个是RoI的class,另一个是RoI的bbox。
虽然Fast R-CNN可以在training和inference的速度上比R-CNN快,但生成region proposal仍然占据了大部分的时间
Faster R-CNN
显然下一步的优化目标就是将region proposal也整合进网络,这也是Faster R-CNN的主要设计思路,具体来说
- 去掉了Selective Search,增加了一个RPN network来生成RoI
- 引入了 anchor box的概念
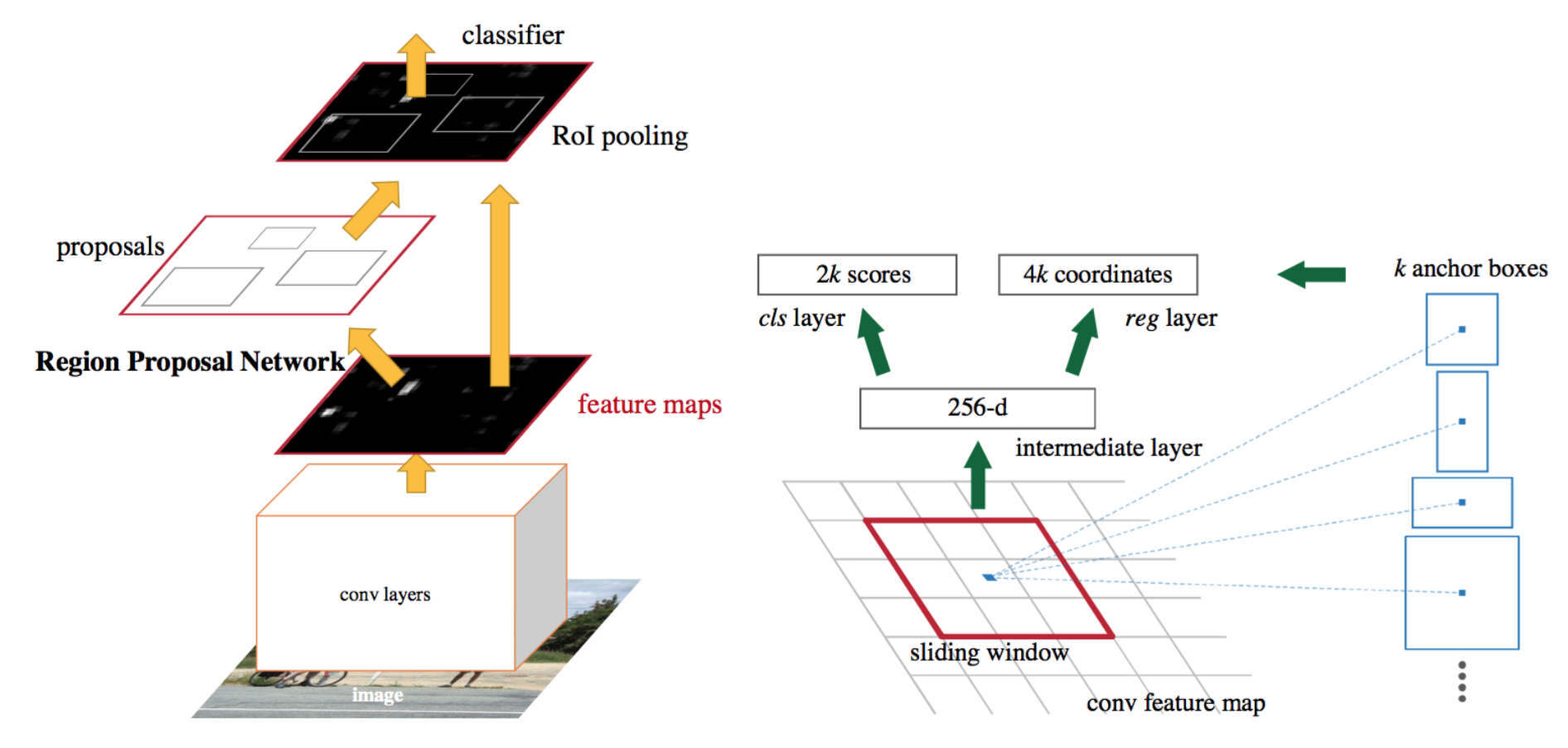
这里简单先介绍一下RPN的工作原理。假设我们的输入图片尺寸为(800,800),经过VGG后,得到的feature map为(512, 50, 50)。接下来我们需要对每个feature map中的每个pixel生成9个bounding box
anchors_boxes_per_location = 9
scales = [8, 16, 32]
ratios = [0.5, 1, 2]
# (1,1)
ctr_x, ctr_y = 16/2, 16/2
这样得到的每个bbox的size和ratio都不同。注意,我们虽然是在feature map上对50 x 50个点操作,但实际上生成的bbox的大小和位置却是相对于原输入图片的,如下图所示
Mask R-CNN
Mask R-CNN是基于Faster R-CNN的架构,引入了Instant Segmentation。它除了输出目标物体的类型和bbox意外,还输出一个segmentation mask,其结构如下图所示
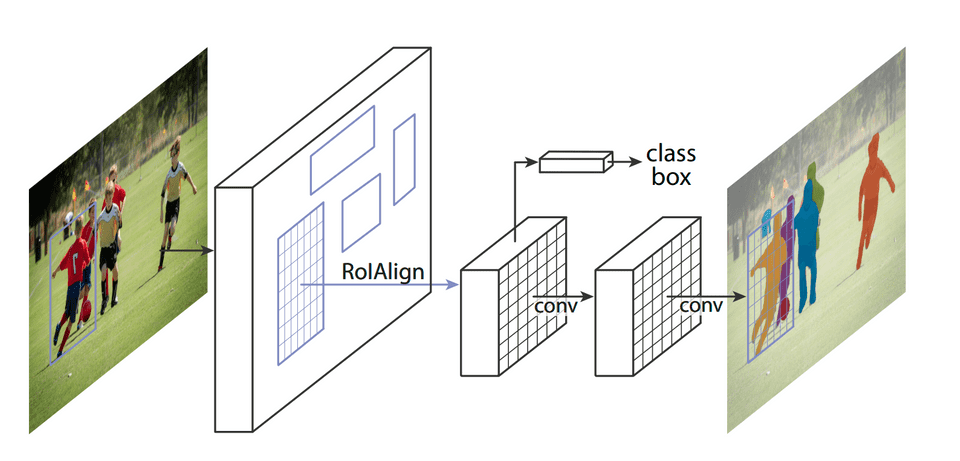
由于Mask R-CNN需要生成像素级别的mask,前面提到的RoI Pooling由于损失太多data因此精度大大降低。为了解决这个问题Mask R-CNN对上面RoI pooling的改进,提出了RoI Align。我们下面来重点介绍这个算法
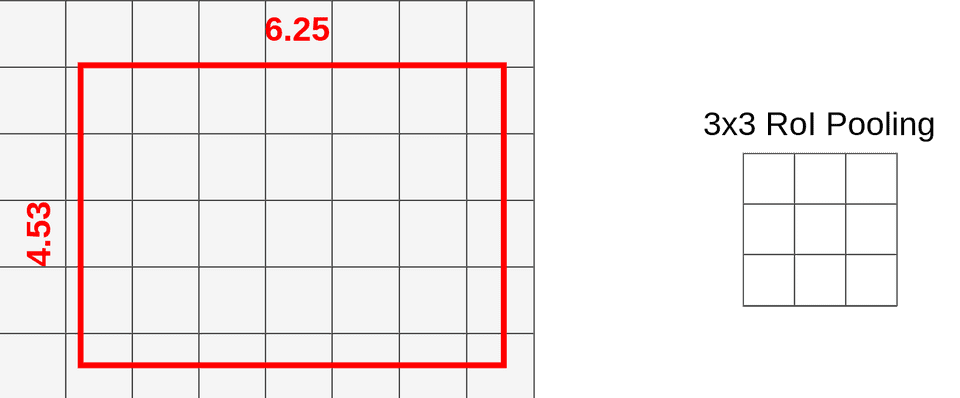
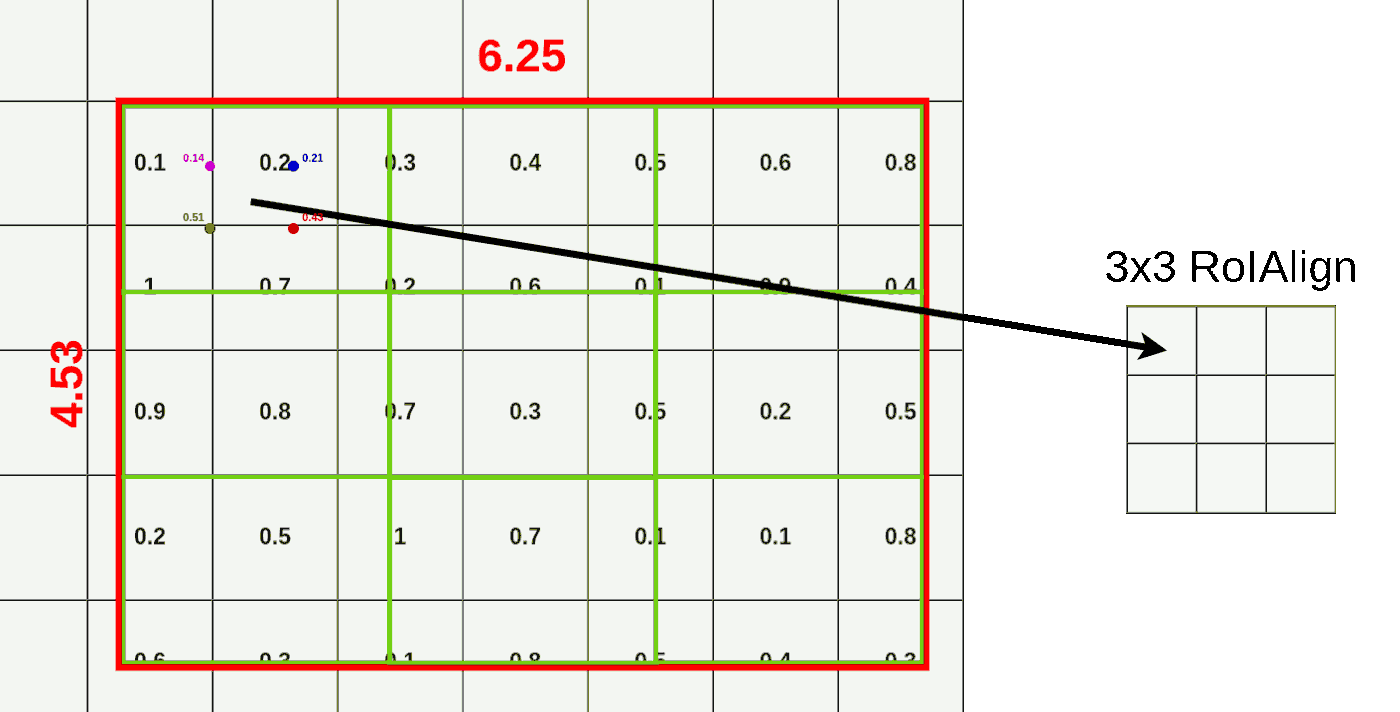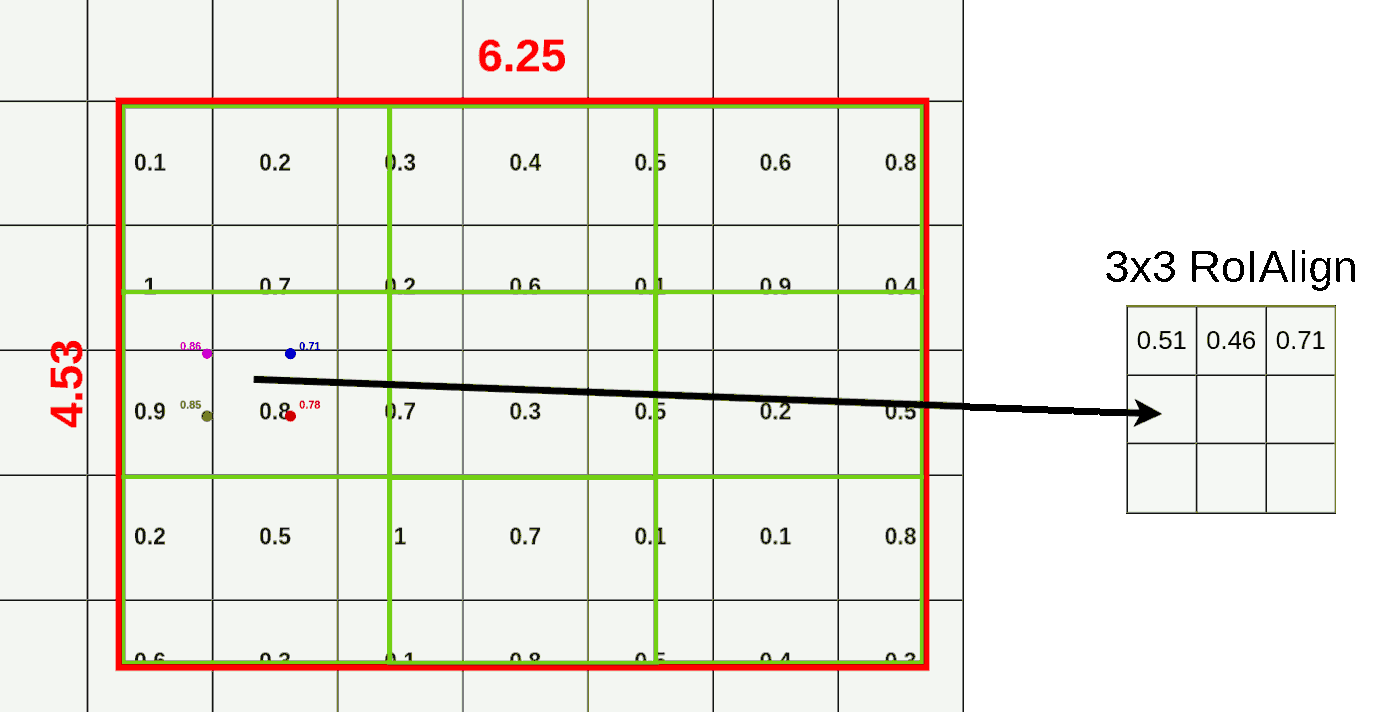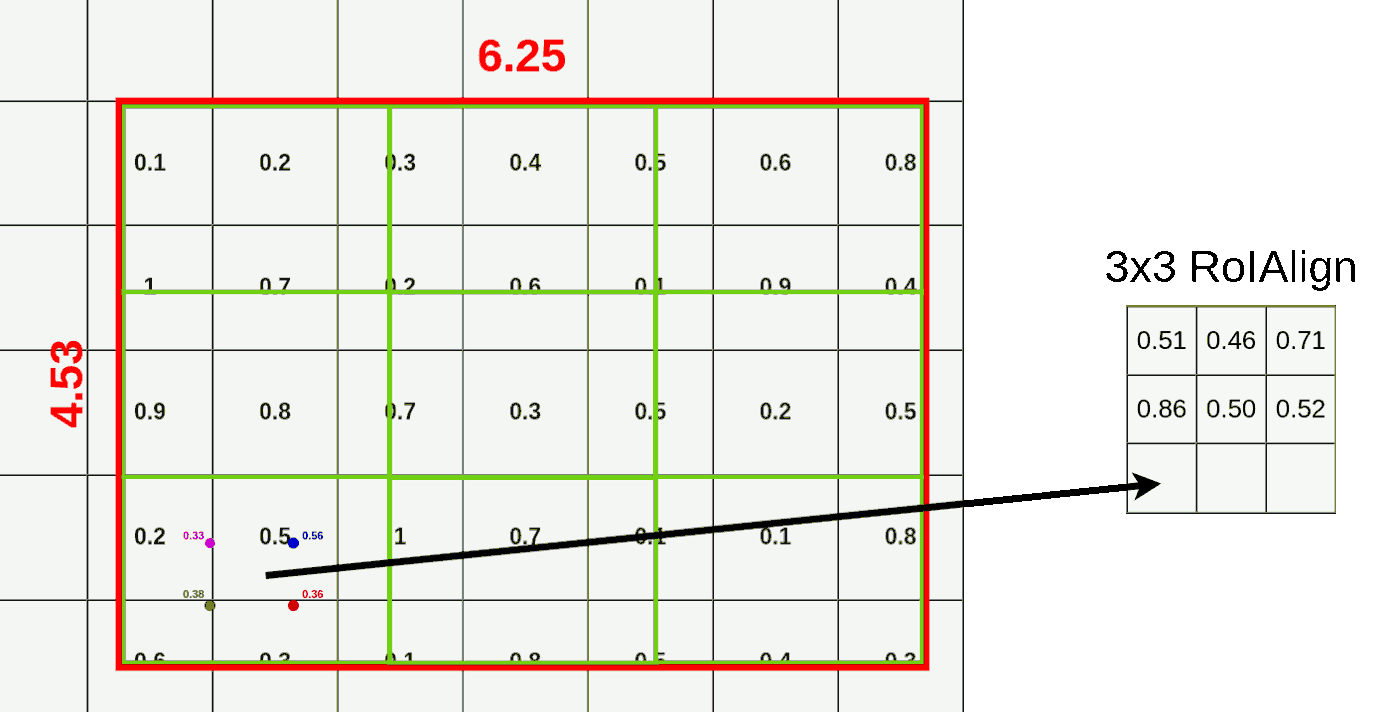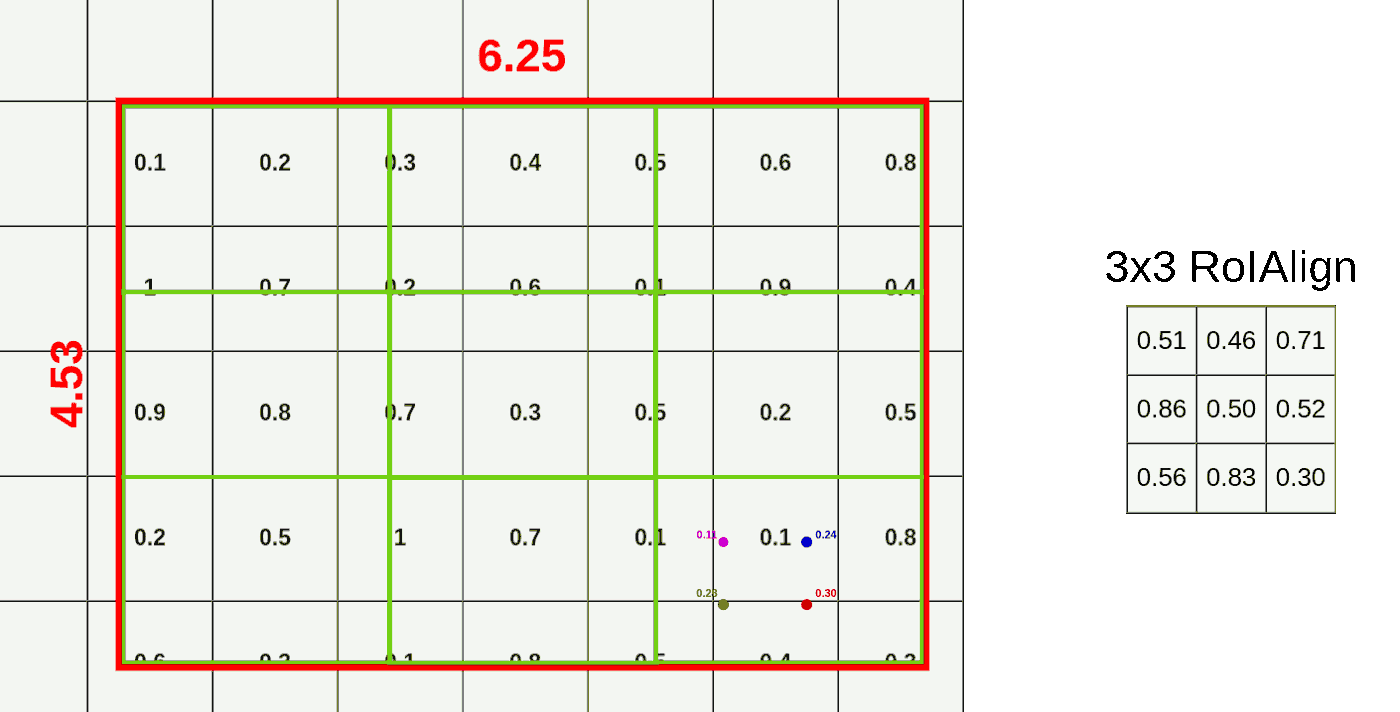
前面已经知道RoI Pooling的两次quantization损失了很多data,RoI Align通过使用双线性二次插值弥补了这一点。还是以前面例子来说明,下图是我们前面的bbox,我们的目标还是对其进行3x3的RoI Pooling操作
和之前不同的是,我们此时不对x,y,w,h进行取整,而是将bbox分成3x3个格子,格子的宽高可以为小数,然后在每个格子内应用双线性插值,如下图所示
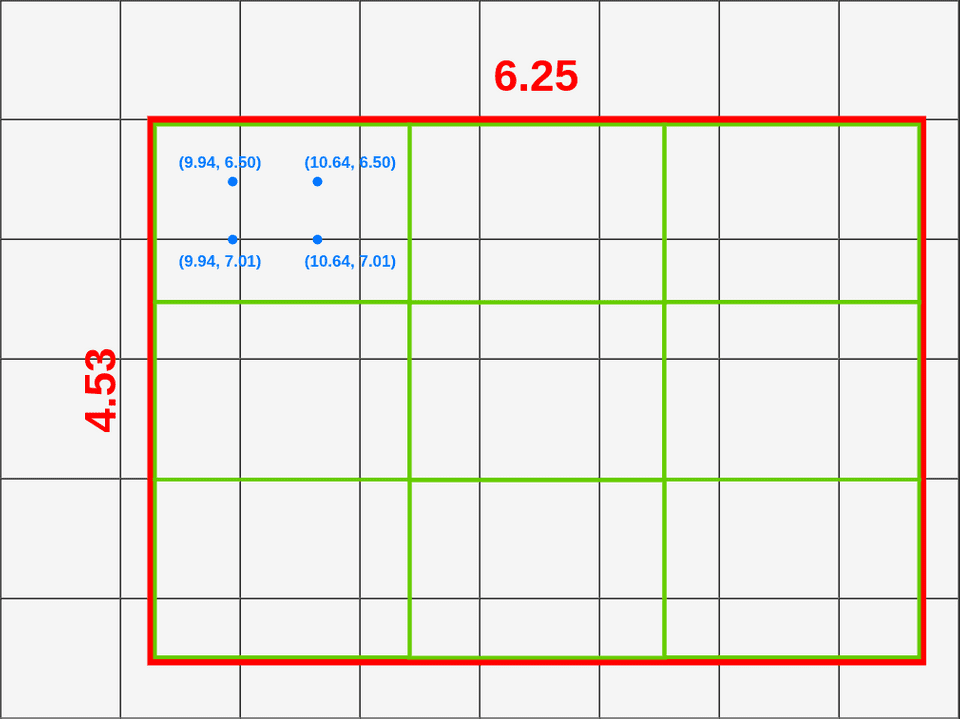
首先我们在每个格子里取四个点,每个点的位置为格子长宽的三等分点,每个点的插值结果用下面公式计算,其中Q值为每个点对应的像素值
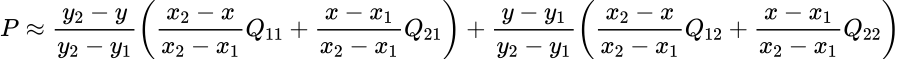
下面我们以左上角(9.44, 6.50)为例,看一下双线性插值是如何计算的。公式里的x,y分别对应(9.44, 6.50)。其中(x1, x2, y1, y2)分别对应四个点邻接cell的中心值,以(9.44, 6.50)为例,和它最近的cell的中心点为(9.50, 6.50),因此x1为9.5,y1为6.50; 左下角点邻接cell的中心值为(9.50, 7.50),由于x1没有发生变化还是9.5,而y2变成了7.5; 以此类推,我们可以得到右上和右下两个cell的中心点分别为 (10.50, 6.50)和(10.50, 7.50),此时x1,x2,y1,y2的值均已确定,我们可以套用上面公式计算出(x,y)点处的值为0.14。
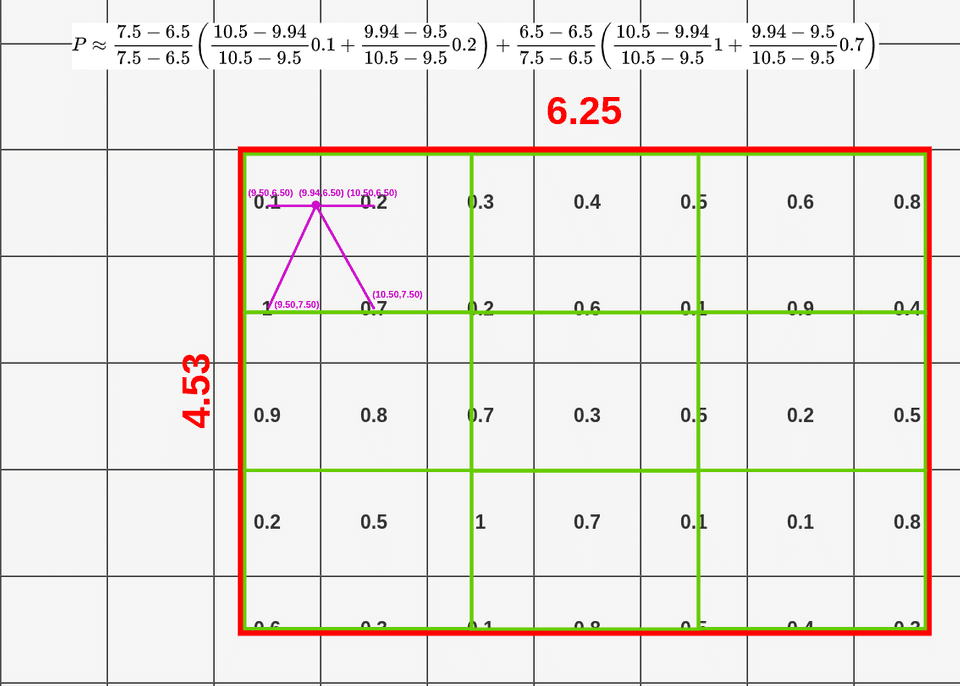
按照上述方式我们可以为剩余三个点计算其双线性插值结果,如下图所示
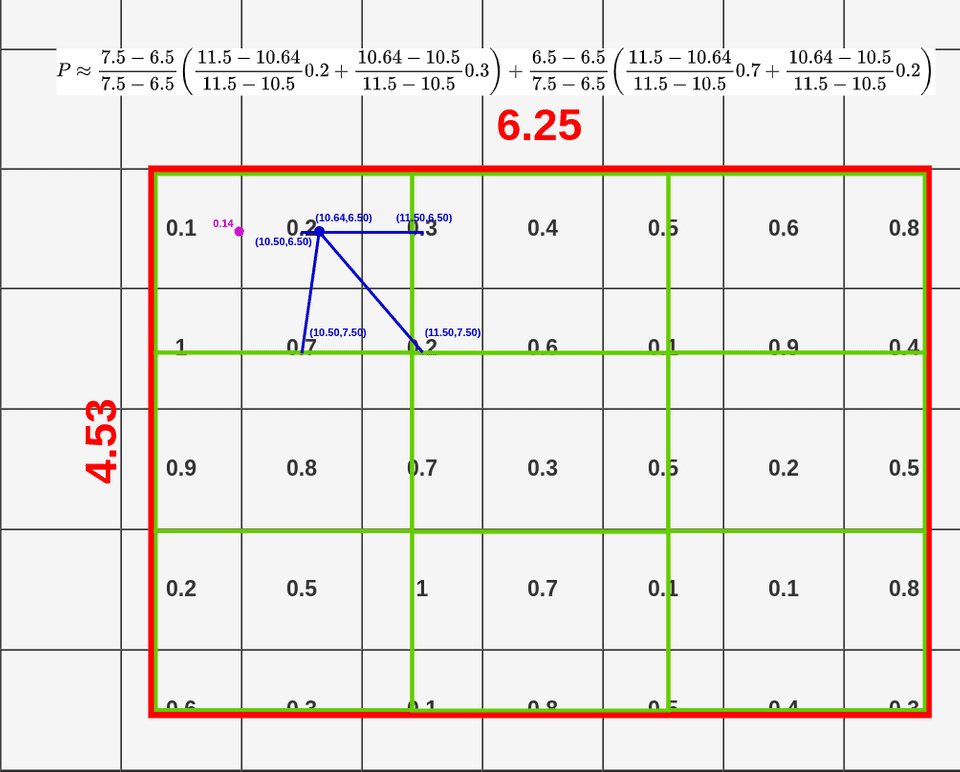
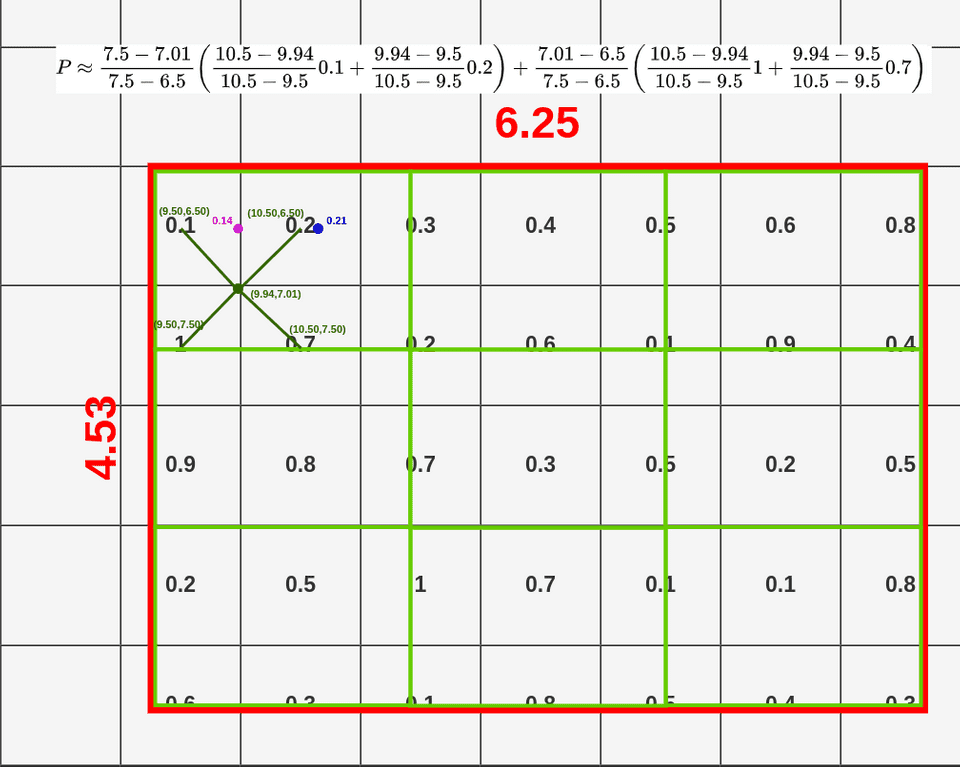
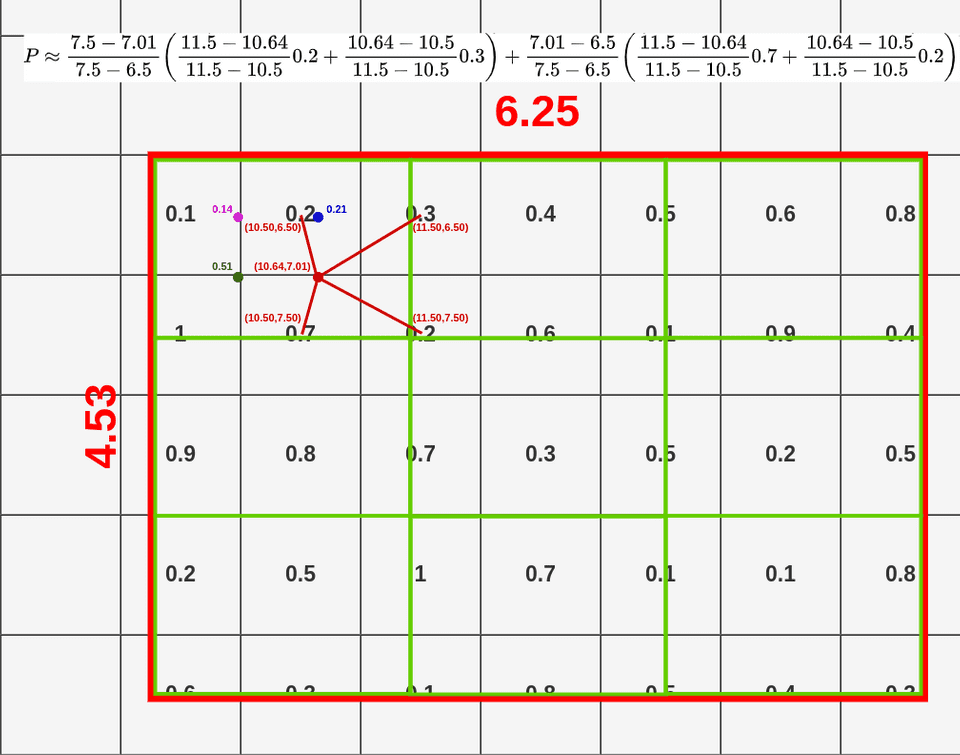
当我们结算完这个4个点的双线性插值结果,我们便可以用max pooling得到该区域的RoI Align的结果。
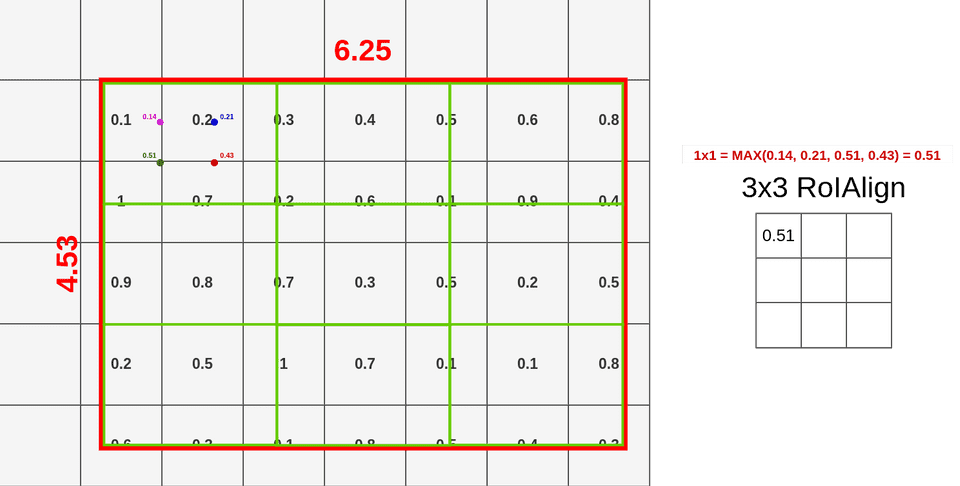
重复上述步骤我们可以得到这RoI Region的结果,如下图所示
理解了RoI Align之后,我们便可以和Fast R-CNN一样对所有的feature map进行RoI Align的操作,得到一组($roi,512,3,3)的feature map,作为后续layer的输入
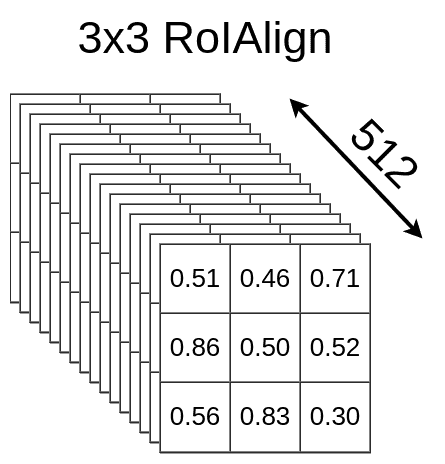
和RoI Pooling相比,RoI Align利用了更多RoI Region周围的像素信息(上图中左边绿色部分),因此可以得到更准确的结果