
Machine Learning for Trading
Prerequisites
- Solid Python understanding
- Pandas, Numpy, Matplotlib Frameworks
- Fundamental concepts of investing, financial markets
Motivation
在我还在上大学的时候,就对股票投资格外有兴趣,我印象中2006年春节前几天我一个人跑去图书馆,翻看一本厚厚的书,书名叫做《股市趋势技术分析》,并认真的做了笔记。当时的想法是通过一些列技术指标的组合实现一套被动交易系统,并且能够稳定盈利。现在想想,当时的想法实在是太超前了,如果世界上真的有这种模型,就算是在今天这样的大数据时代也不太会被轻易的找到,更别提一个业余散户和那个互联网才刚刚在中国起步的年代了。
10几年过去了,虽然从事是非金融类工作,对投资还是一直很执着,学习过各种金融知识,各种市场理论,但这些知识确对提高投资水平的帮助却不大,对于投资,我觉得有句话说的特别好(忘记是谁说的了)
\[投资水平 \thinspace = \thinspace (技术+艺术) \times 经验\]我个人比较相信市场有效理论,散户是很难竞争过机构的,原因就不展开了,这里推荐两本书,一本是纳西姆塔勒布的《随机漫步的傻瓜》,另一本是《漫步华尔街》。而对于机构来说(也就是所谓的大型对冲基金),他们的交易策略是什么样的呢,我相信外行人是没法回答这个问题的,但是如果你是名工程师,又恰好对投资感兴趣,或许可以从另一个角度来思考这个问题,因为工程师虽然不知道复杂的金融学理论,但却有可能搞清楚交易系统是如何设计的。
了解投资的朋友可能知道有这么一家对冲基金公司叫做Renaissance,翻译过来叫做文艺复兴公司,这家基金的员大部分是数学家,统计学家,计算机科学家和工程师,他们做的事情就是我10几年在笔记本第一页写的那句话,只不过这个年代有了大数据,机器学习,分布式计算等武器使得人们有可能制造出这样一个系统,也就是所谓的量化交易系统,这个系统也给工程师们开了一扇走进投资世界的大门。
今天用的比较火的Pandas, Numpy等数据分析framework,均诞生于金融分析这个领域
前一段时间在Cousera上找到了Geogia Tech的这门课,虽然学术界是不可能造出比工业界还领先的平台的(水平相当都很难),但这门课确是一个入门这个领域的好材料。后来发现它们在Udacity上也开了一门类似的课程叫做《Machine Learning For Trading》,内容上两门课有重叠,但可以相互补充这来看,以上就是写这个系列的Motivation,希望自己能坚持将它写完。
概述
在介绍计算投资理论之前,我想先用Python快速实现几个股票数据分析的例子,对接下来要做的事情先有一个直观的感受,毕竟我们是从工程的角度出发,而非从学术的角度,一上来就讲各种金融学概念难免会很枯燥,从而丧失继续学习的兴趣。这篇文章将会从Python数据分析的角度切入,介绍怎么对现有的股票数据进行简单的分析和可视化,后面的文章会逐步介绍一些基本的金融学知识
快速上手
假设我们有一组数据AAPL.csv,该数据包含了APPLE从1984-2008这几年的每日股票价格数据,格式如下
| Date | Open | High | Low | Close | Volume | Adj |
| 2008-10-14 | 116.26 | 116.40 | 103.14 | 104.08 | 70749800 | 104.08 |
| 2008-10-13 | 104.55 | 110.53 | 101.02 | 110.26 | 54967000 | 110.26 |
| … | … | … | … | … | … | … |
| 1984-09-10 | 26.50 | 26.62 | 25.87 | 26.37 | 2346400 | 3.01 |
| 1984-09-07 | 26.50 | 26.87 | 26.25 | 26.50 | 2981600 | 3.02 |
如果熟悉股票投资,应该可以大致了解每一列数据的含义,比如开盘价,收盘价,盘中最高,最低价,成交量等。现在有了这些数据,我们就可以用Python来对数据做一些简单的处理。比如我们可以统计出从1984年到2008年股价的最高点和成交量的中位数
import pandas as pd
import matplotlib.pyplot as plt
#Read csv file
df = pd.read_csv("data/AAPL.csv")
#Get max price
max_price = df['Close'].max() # max_price: 199.83
#Get avg. volume
mean_volume = df['Volume'].mean() #avg_volume: 13639864.0684098
#Data Visualization
df['Close'].plot()
plt.show()
从上面的Demo中可知,分析数据的基础是要先得到历史数据文件,我们可以从Yahoo Finance上找到任何感兴趣的公司的csv数据,它是我们数据分析和设计交易算法的基础。因此我们需要先搞清楚如何灵活的使用csv数据。
Building DataFrames
在Python中,将csv文件读入内存中后,其结构为DataFrame,Pandas提供了很多方便的API来处理DataFrame数据,例如前面demo中的统计最大值,均值,最小值等。显然csv数据也是一种关系型数据结构,所有对数据库的操作,对DataFrame同样适用,例如我们可以将多个公司的csv数据JOIN到一起
import pandas as pd
start_date = '2018-03-01'
end_date = '2018-03-30'
dates = pd.date_range(start_date, end_date)
# <class 'pandas.core.indexes.datetimes.DatetimeIndex'>
#dates[0] = 2018-03-22 00:00:00
#Create an empty dataframe
#index = date
df1 = pd.DataFrame(index=dates)
#index = "Date"
dfSPY = pd.read_csv("./data/SPY.csv",
index_col="Date",
parse_dates=True,
usecols=['Date','Adj Close'],
na_values=['nan'])
#Rename Column name
dfSPY = dfSPY.rename(columns={'Adj Close':'SPY'})
#Inner Join S&P500
df1 = df1.join(dfSPY,how="inner");
#Read symbols in ./data
symbols = ['GOOG','FB','AAPL'];
for name in symbols:
df_tmp = pd.read_csv(f"./data/{name}.csv",
index_col="Date",
parse_dates=True,
usecols=['Date','Adj Close'],
na_values=['nan']);
df_tmp = df_tmp.rename(columns={'Adj Close':name})
#left join all tables to df1
df1 = df1.join(df_tmp) #how="left";
print(df1.ix['2018-03-01':'2018-03-06']) #first 6 days
上面的例子是统计Apple,Google,Facebook三家公司过去一年的收盘价,参照标准是标准普尔500指数。上述代码中,可以将GOOG,FB,AAPL看成三张表,三张表进行JOIN的key是date,上述代码可得出下面的数据
SPY GOOG FB AAPL
2018-03-01 265.440216 1069.520020 175.940002 173.718521
2018-03-02 266.808533 1078.920044 176.619995 174.919678
2018-03-05 269.892303 1090.930054 180.399994 175.525208
2018-03-06 270.576477 1095.060059 179.779999 175.376297
这里要注意一点的是,上面JOIN语法和SQL的JOIN略有区别,SQL的JOIN需要指定key,这里默认使用主键来JOIN,因此创建DataFrame的时候需要指定主键的key
这样我们就可以同时期的比较多个股票的价格走势,如果要比较全年股价走势,使用数据表格则不够直观,我们也可使用matplotlib将其可视化
#normalized data
df1 = df1 / df1.ix[0,:]
ax = df1.plot(title='Stock Prices', fontsize=6)
ax.set_xlabel("Date")
ax.set_ylabel("Price")
plt.show()
上述代码需要注意的是,将股价归一化的算法是将行数据都除以其第一行的数据,这样四只股票的价格均从1.0开始,便于分析比较,得到结果如下
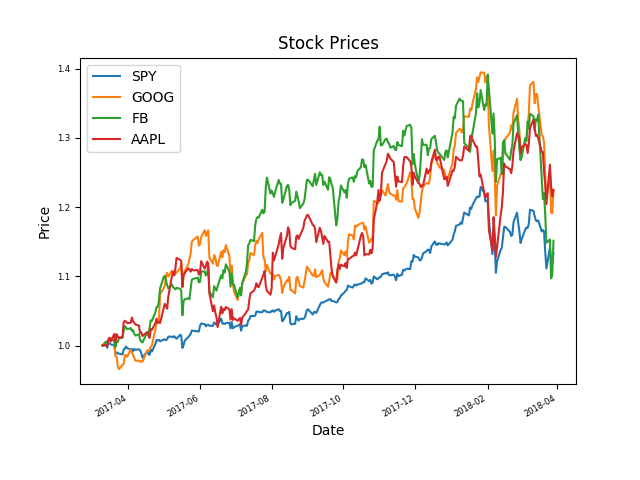
从上图中可以看出,全年来看这三只股票均跑赢了S&P500, 其中FB涨幅最大,APPLE涨幅最小,APPL回调幅度最大,FB在四月份回调幅度也很大。后面我们会计算夏普比率来分析哪只股票的风险收益比最高,以及资产配比的最优化策略。
(全文完)