
Machine Learning at Facebook - Understanding Inference at the Edge
This is a summary of this great paper paper link. And here is the video on Youtube.
Introduction
In our dataset,an overwhelming majority of mobile CPUs use in-order ARM Cortex-A53 and Cortex-A7 cores
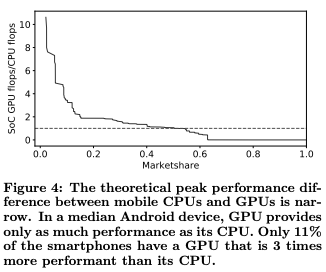
Considering theoretical peak FLOP performance, less than 20% of mobile SoCs have a GPU 3× more powerful than CPUs and, on a median mobile device, GPUs are only as powerful as CPUs.
This paper makes the following key observations:
-
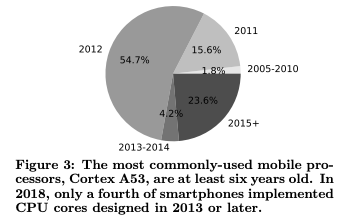
Nearly all mobile inference run on CPUs and most deployed mobile CPU cores are old and low-end. In 2018, only a fourth of smartphones implemented CPU cores designed in 2013 or later. In a median Android device, GPU provides only as much performance as its CPU. Only 11% of the Android smartphones have a GPU that is 3 times more performant than its CPU.
-
System diversity makes porting code to co-processors, such as DSPs, challenging. We find it more effective to provide general, algorithmic level optimizations that can target all processing environments. When we have control over the system environment (e.g., Portal [4] or Oculus [5] virtual reality platforms) or when there is little diversity and amature SW stack (e.g., iPhones), performance acceleration with co-processors becomes more viable
-
The main reason to switch to an accelerator/coprocessor is power-efficiency and stability in execution time. Speedup is largely a secondary effect.
-
Inference performance variability in the field is much worse than standalone benchmarking results. Variability poses a problem for user-facing applications with real-time constraints. To study these effects,there is a need for system-level performance modeling.
A LOOK AT SMARTPHONES FACEBOOK RUNS ON
2.2 Mobile CPUs show little diversity
Figure 3 shows a breakdown of the year smartphone CPU cores were designed or released. 72% of primary CPU cores being used in mobile devices today were designed over 6 years ago. Cortex A53 represents more than 48% of the entire mobile processors whereas Cortex A7 represents more than 15% of the mobile processors
iOS devices tend to use fewer, more powerful cores while Android devices tend to have more cores, which are often less powerful. A similar observation was made in 2015 [6]. To optimize a production application for this degree of hardware diversity, we optimize for the common denominator: the cluster of most performant CPU cores.
About half of the SoCs have two CPU clusters: a cluster of high-performance cores and another cluster of energy-efficient cores. Only a small fraction include three clusters of cores. Cores in the different clusters may differ in microarchitectures, frequency settings, or cache sizes. A few SoCs even have two clusters consisting of identical cores. In nearly all SoCs, cores within the same cluster have a shared cache, but no cache level is shared between cores in the different clusters. The lack of a shared cache imposes a high synchronization cost between clusters. For this reason, Facebook apps target the high-performing cluster by, for example, matching thread and core count for neural network inference.
2.3 The performance difference between a mobile CPU and GPU/DSP is narrow
High-performance GPUs continue to play an important role in the success of deep learning. It may seem natural that mobile GPUs play a similar part for edge neural network inference. However, today nearly all Android devices run inference on mobile CPUs due to the performance limitations of mobile GPUs as well as programmability and software challenges.
Figure 4 shows the peak performance ratio between CPUs and GPUs across Android SoCs. In a median device, the GPU provides only as much theoretical GFLOPS performance as its CPU. 23% of the SoCs have a GPU at least twice as performant as their CPU, and only 11% have a GPU that is 3 times as powerful than its CPU
Realizable mobile GPUs performance is further bottlenecked by limited memory bandwidth capacities. Unlike high-performance discrete GPUs, no dedicated high-bandwidth memory is available on mobile. Moreover, mobile CPUs and GPUs typically share the same memory controller, competing for the scarce memory bandwidth.
2.4 Available co-processors: DSPs and NPUs
However DSPs face the same challenge GPUs do – “compute” DSPs are available in only 5% of the Qualcomm-based SoCs the Facebook apps run on. Most DSP do not yet implement vector instructions. While all vendors are adding vector/compute DSPs, it is likely to take many years before we see a large market presence.
2.5 Programmability is a primary roadblock for using mobile co-processors
Vulkan is a successor to OpenGL and OpenGL ES. It provides similar functionality to OpenGL ES 3.1, but with a new API targeted at minimizing driver overhead. Looking forward, Vulkan is a promising GPGPU API. Today, early adoption of Vulkan is limited, being found on less than 36% of Android devices.
Metal is Apple’s GPU programming language. Mobile GPUs on iOS devices paint a very different picture.Because Apple chipsets with the A-series mobile processors are vertically-designed, the system stack is more tightly integrated for iPhones. Since 2013 all Apple mobile processors, starting with A7, support Metal. Metal is similar to Vulkan but with much wider market share and more mature system stack support. 95% of the iOS devices support Metal. Moreover the peak performance ratio between the GPU and the CPU is approximately 3 to 4 times, making Metal on iOS devices with GPUs an attractive target for efficient neural network inference. Guided by this data and experimental performance validation, Facebook apps enable GPU-powered neural network inference on iOS for several models.
MACHINE LEARNING AT FACEBOOK
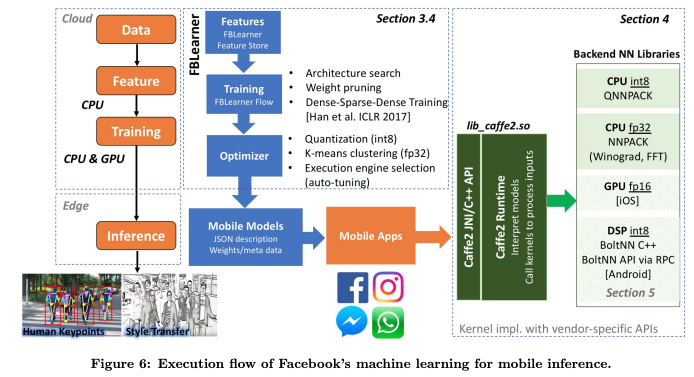
3.3 Important Design Aspects for Mobile Inference and Potential Approaches
model and code sizes are imperative for mobile because of the limited memory capacity of a few GBs. Techniques, such as weight pruning, quantization, and compression, are commonly used to reduce the model size for mobile.
Code size is a unique design point for mobile inference. First option is to compile applications containing ML models to platform-specific object code using, for example, Glow [10], XLA [11], or TVM [12]. This often leads to larger model sizes (as the model now contains machine codes but enables a smaller interpreter.). Second option is to directly use vendor-specific APIs, such as iOS CoreML [13], from operating system vendors. Another approach is to deploy a generic interpreter, such as Caffe2 or TF/TFLite, that compiles code using optimized backend. The first approach is compiled execution which treats ML models as code whereas the later approach is interpreted execution which treats ML models as data.Techniques are chosen depending on design tradeoff suitable in different usage scenarios.
For edge inference, to improve computational performance while maximizing efficiency, techniques, such as quantization, k-means clustering, execution engine selection, are employed to create mobilespecific models
4.HORIZONTAL INTEGRATION: MAKING INFERENCE ON SMARTPHONES
NNPACK (Neural Networks PACKage) performs computations in 32-bit floating-point precision and NCHW layout, and targets high-intensity convolutional neural networks, which use convolutional operators with large kernels, such as 3x3 or 5x5. NNPACK implements asymptotically fast convolution algorithms, based on either Winograd transform or Fast Fourier transform, which employ algorithmic optimization to lower computational complexity of convolutions with large kernels by several times. With algorithmic advantage and low-level microarchitecture-specific optimizations, NNPACK often delivers higher performance for direct convolution implementation.
QNNPACK (Quantized NNPACK) on the other hand performs computations in 8-bit fixed-point precision and NHWC layout. It is designed to augment NNPACK for low-intensity convolutional networks, e.g.neural networks with large share of 1x1, grouped, depthwise, or dilated convolutions. These types of convolutions do not benefit from fast convolution algorithms, thus QNNPACK provides a highly efficient implementation of direct convolution algorithm. Implementation in QNNPACK eliminates the overhead of im2col transformation and other memory layout transformations typical for matrix-matrix multiplication libraries. Over a variety of smartphones, QNNPACK outperforms stateof-the-art implementations by approximately an average of two times.