
Variables and Memory Part 1
Memory Model
基本上所有语言的变量内存模型都类似,如果习惯了使用静态语言或者偏底层一点的语言,对这个概念应该不陌生,它就是一块用存放某个对象的内存区域。对象创建方式的不同会导致变量在内存中分配位置的不同,比如C++中有栈对象和堆对象,这点在C++中很容易区分,分配在堆上的对象可以用指针索引,分配在栈上的对象按变量名索引。而现在的绝大部分的脚本语言淡化了这个概念,使得有时候搞不清楚变量到底是在哪里创建的,为什么这个问题如此重要呢?因为它关系到一些很重要的问题,比如拷贝控制,生命周期,内存回收等等。
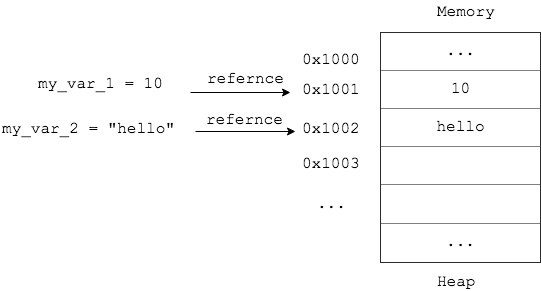
对于Python来说,它的对象是在堆上创建的,变量名相当于指针或者是引用。Python提供了一个函数id()可以查看对象的内存地址
a = 10
print(hex(id(a))) #0x107e2bb90
既然Python的对象都是分配在堆上,那么它就需要处理好指针的管理问题,对于指针来说,有两个重要的问题,分别是引用计数管理和内存回收问题
Reference Count
my_var = 10
other_var = my_var
上述代码如果C++中,它的行为是拷贝,也就是说other_var有自己的一片内存空间,值为10,而对于python来说,既然是指针索引,那么内存中只有一份10,my_var和other_var都是这片内存的引用,因此指针的引用计数为2。没错,Python也是使用引用计数的,引用计数可以通过系统的API查看
import sys
a = [1,2,3]
sys.getrefcount(a) #2
但是如果使用该API查看,a的引用计数并不准确,因为a做参数传递过去,其引用计数会自动+1,因此更精确的做法是使用下面的API,传递地址而非变量
import ctypes
def ref_count(address:int):
return ctypes.c_long.from_address(address).value
ref_count(id(a)) #1
注意,这里有一个问题是,将
a递个id函数时,引用计数也会+1, 但是当id函数返回时,引用计数-1,因此可以得到正确的结果
这时我们如果将a清空,a的引用计数变为0,a应该被回收
a_address = id(a)
a = None
ref_count(a_address) #1
ref_count(a_address) #0
ref_count(a_address) #9899200214
上述测试可见a并不是马上被回收的,而就算a被会后之后,它的地址仍有效,但引用计数就不对了,出现这中情况也不难理解,Python底层是C实现,a被释放后,其内存可能被其它对象占用,因此结果是不可预测的。通常情况下使用Python除了偶尔需要debug,并不会去折腾内存,因此了解到这里应该也就足够了,如果要继续深入,可以接着去研究C/C++的内存分配和回收机制
Garbage Collection
接下来我们讨论内存回收,提到这个话题,有经验的程序员很自然的想到一个非常头疼的问题,就是如何检测循环引用导致的内存泄漏,即某对象的引用计数永远不可能为1。循环引用,有点类似多线程的死锁,引用双方都等待对方释放,从而进入等僵持状态。Python脱离底层确更容易遇到这个问题
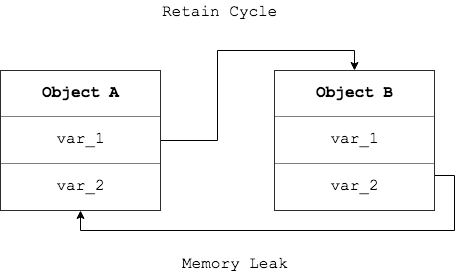
幸运的是,Python的垃圾回收机制可以检测到这种情况,从而强制将其双双回收掉。默认情况下GC是开着的,每隔几秒检查并回收一次,当然也可以手动调用让其强制回收一次。如果想要追求性能,也可以主动将其关掉,但要程序员来确保不出现循环引用的情况,which is very hard to do so.
对于Python<3.4的版本,如果其中一个循环引用的对象重载了析构函数
__del__,GC会认为该对象的对析构顺序有要求,但GC并不知道谁该被先析构,因此这种情况下GC会将两个对象标记为uncollectable,均不回收
我们可以使用下面代码来查找某object是否处于GC待回收的列表中
import ctypes
import gc
def ref_count(address):
return ctypes.c_long.from_address(address).value
def object_by_id(object_id):
for obj in gc.get_objects():
if id(obj) == object_id:
return "Object Exists"
return "Not Found"
接下来我们创建两个循环引用的对象,并暂停GC,观察内存地址
class A:
def __init__(self):
self.b = B(self)
print(f'A: self:{hex(id(self))},b:{hex(id(self.b))}')
class B:
def __init__(self, a):
self.a = a
print(f'B: self:{hex(id(self))},a:{hex(id(self.a))}')
gc.disable()
a = A()
# B: self:0x10aa2b208,a:0x10aa2b160
# A: self:0x10aa2b160,b:0x10aa2b208
从逻辑上分析,a持有b对象,b对象中的a又指回a,产生循环引用。查看a和b的引用计数
id_a = id(a)
id_b = id(a.b)
print(ref_count(id_a)) #2
print(ref_count(id_b)) #1
print(object_by_id(id_a)) #Object Exists
print(object_by_id(id_b)) #Object Exists
a的引用计数为2,a被自身引用和被b.a引用,b的引用计数为1,只被a.b引用,符合推理,同样,a,b均存在与GC的列表中。接下来我们将a的引用计数-1
a = None
print(ref_count(id_a)) #1
print(ref_count(id_b)) #1
可见即使显式的释放了对象,其内存仍然没有被安全回收,产生内存泄漏,最后我们可以开启GC,令其对a,b进行强制回收
gc.collect()
print(object_by_id(id_a)) #Not Found
print(object_by_id(id_b)) #Not Found
print(ref_count(id_a)) #0
print(ref_count(id_b)) #0
最后需要注意的是,被回收之后的a,b其地址仍然存在,但该地址是无效的,因为对象已经不存在了。
Important Note
上面讨论的内容,以及后面要讨论的内容均和Python的底层实现相关,这里我们是以标准的CPython作为引擎来研究Python。除了CPython之外,还有很多其他的Python引擎,比如
Jython可将python代码编译为JVM可识别的某种中间代码(类似javac)从可使其运行在JVM中IronPython是用C#编写的,可以运行在.net平台上的Python引擎PyPy是用Python写的一个Python解释器
更多的Python引擎可以参考wiki
(全文完)