
What Compilers can and cannot Do
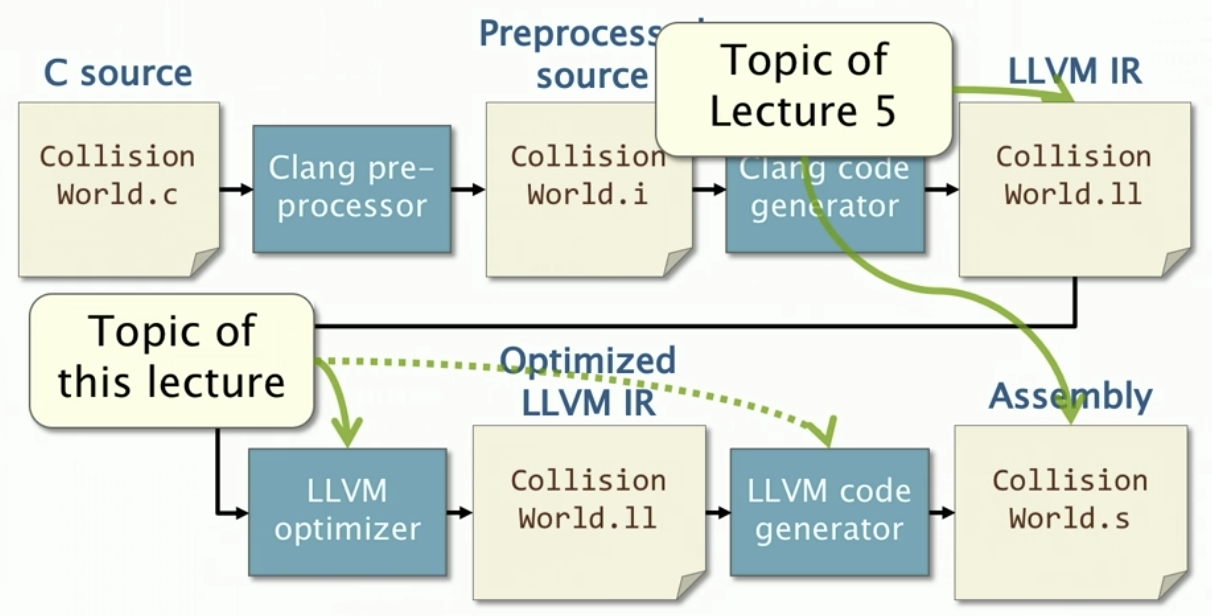
Clang/LLVM Compilation Pipeline
This lecture completes more of the story from Lecture 5 about the compilation process
Why study the compiler optimizations?
- Compiler can have a big impact on software performance
- Compilers can save you performance-engineering work.
- Compilers help ensure that simple, readable, and maintainable code is fast
- You can understand the differences between the source code and the IR or assembly
- Compilers can make mistakes
- Understanding compilers can help you use them more effectively.
Simple Model of the Compiler
An optimizing compiler performs a sequence of transformation passes on the code
LLVM IR -> Transform -> Transform -> Transform -> ... -> Transform -> Optimized LLVM IR
- Each transformation pass analyzes and edits the code to try to optimize the code’s performance
- A transformation pass might run multiple times
- Passes run in a predetermined order that seems to work well most of the time
Compiler Reports
Clang/LLVM can produce reports for many of its transformation passes, not just vectorization:
-Rpass=<string>: Produces reports of which optimizations matching<string>were successful.-Rpass-missed=<string>: Produces reports of which optimizations matching<string>were not successful.-Rpass-analysis=<string>: Produces reports of the analyses performed by optimizations matching<string>
The argument <string> is a regular expression. To see the whole report, use “.*” as the string.

The good news: The compiler can tell you a lot about what it’s doing
- Many transformation passes in LLVM can report places where they successfully transform code.
- Many can also report the conclusions of their analysis.
The bad news: Reports can be hard to understand.
- The reports can be long and use LLVM jargon.
- Not all transformation passes generate reports.
- Reports don’t always tell the whole story.
We want context for understanding these reports
Compiler Optimizations
- Data Structures
- Register allocation
- Memory to registers
- Scalar replacement of aggregates
- Alignment
- Loops
- Vectorization
- Unswitching
- Idiom replacement
- Loop fission
- Loop skewing
- Loop tiling
- Loop interchange
- Logic
- Elimination of redundant
- Memory to registers
- Strength reduction
- Dead-code elimination
- Idiom replacement
- Branch reordering
- Global value numbering
- Functions
- Unswitching
- Argument elimination
Optimizing a scalar
Handling one argument, -O0 code

- We first allocate some local storage on the stack.
- Then we store the value from
%2into that doublea. - Later on, we’ll load the value out of the
%6into%14before the multiply. - Then we load it again before the other multiply.
How do we optimize the code?
IDEA: Replace the stack - allocated variables with the copy in the register. Since the value of a is already in the register %2, it’s not necessary to allocate storage on stack. What we’re going to do is just replace those loads from memory with the original argument.
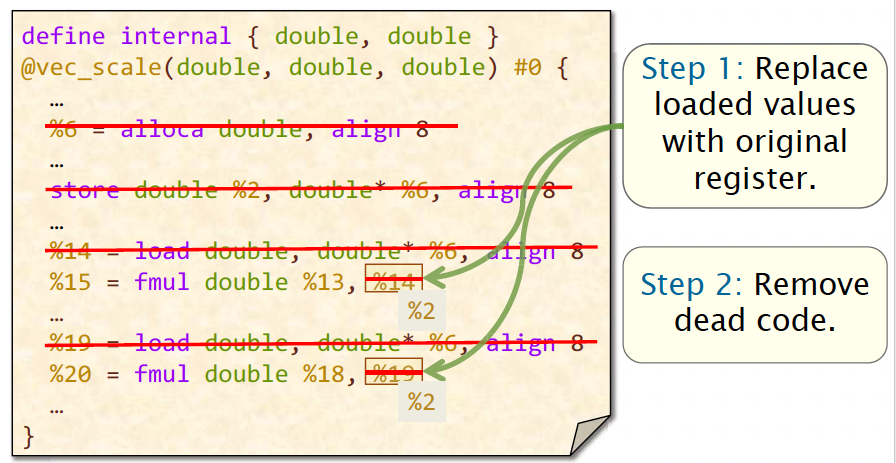
Summary: Compilers transform data structures to store as much as possible in registers.
Function Inlining
Let’s see how compilers optimize function calls. In the first LLVM IR snippet, we have a function call to vec_scale, which is the second snippet. In this case, the vec_scale is a small function, compiler can just inline that function directly.

This is called function inlining. We identify some function call, or the compiler identifies some function call.And it takes the body of the function, and just pastes it right in place of that call.
SUMMARY: Function inlining and additional transformations can eliminate the cost of the function abstraction.
Problems with Function Inlining
Why doesn’t the compiler inline all function calls?
- Some function calls, such as recursive calls cannot be inlined except in special cases, e.g., “recursive tail calls.”
- The compiler cannot inline a function defined in another compilation unit unless one uses whole-program optimization.
- Function inlining can increase code size, which can hurt performance.
Controlling Function Inlining
QUESTION: How does the compiler know whether or not inlining a function will hurt performance?
ANSWER: It doesn’t know. It makes a best guess based on heuristics, such as the function’s size.
Tips for controlling function inlining:
- Mark functions that should always be inlined with
__attribute__((always_inline)). - Mark functions that should never be inlined with
__attribute__((no_inline)). - Use link-time optimization (LTO) to enable whole-program optimization.
the
static inlinekeyword provides a hint to compiler but doesn’t guarantee the function to be inlined.
Loop Optimizations
Compilers also perform a variety of transformations on loops. Why?
Loops account for a lot of execution time.
Consider this thought experiment:
- Consider a 2 GHz processor with 16 cores executing 1 instruction per cycle.
- Suppose a program contains $2^{40}$ instructions and ample parallelism for 16 cores, but it’s all simple straight-line code, i.e., no loops.
QUESTION: How long does the code take to run? ANSWER: 32 seconds!
2 GHz means CPU has approximately 2*2^30 cycles per second. Now we have 16 cores, so the total cycle per second is 2^4 * 2 * 2^30 = 2^35. We have 2^40 instructions. So the total seconds is 2^40 / 2^35 = 32.
Usually the code will run much slower than 32 seconds. Because there is loops in the program.
Let us look at another common optimization on loops: code hoisting, a.k.a., loop-invariant- code motion (LICM).

If we translate this code into LLVM IR, we end up with, hopefully unsurprisingly, a doubly nested loop.
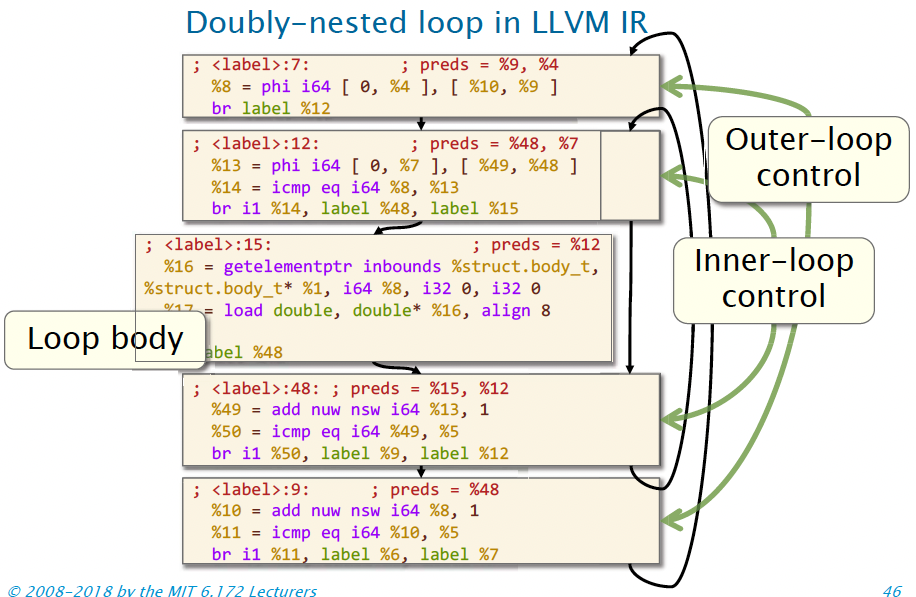
The first two address calculations only depend on the outermost loop variable, the iteration variable for the outer loop.
So what can we do with those instructions?
Move them out of the inner-loop body!

In general, if the compiler can prove some calculation is loop-invariant, it will attempt to hoist the code out of the loop.
Summary: What the Compiler Does
Compilers transform code through a sequence of transformation passes.
- The compiler looks through the code and applies mechanical transformations where it can.
- Many transformations resemble Bentley-rule work optimizations.
- One transformation can enable other transformations.