
Build an AST Interpreter
Interpreter
- Interpreted Languages
- Implement semantics themselves
- AST-based (recursive) interpreters
- Tree-like structure
- Bytecode-interpreters(VM)
- Instruction-like structure
- Compiled languages
- Delegate semantics to a target language
- Ahead-of-time(AOT) compilers (C++)
- Can call interpreter in during the compilation process
- Just-in-time(JIT) compilers
- AST-transformers
AST interpreter
Capture high-level semantics
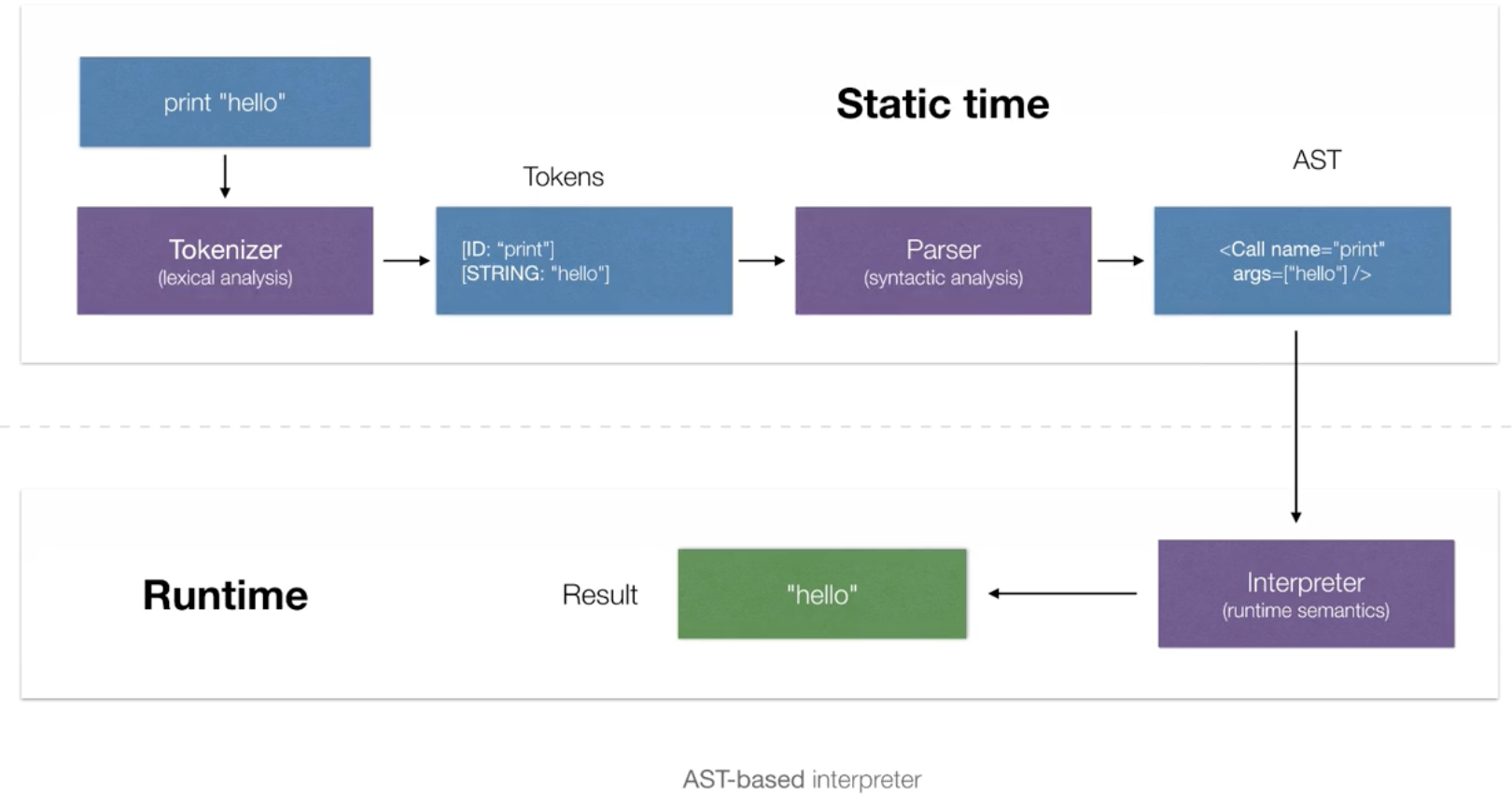
Let’s say we have the following example code:
x = 15;
x + 10 - 5;
The AST result could look like this
// AST
[program, [
[assign, x, 15],
[sub,
[add, x, 10],
5
]
]]
This AST result is handed to an AST interpreter.
You can find the AST definition for different languages in astexplorer.net.
Bytecode interpreter
Bytecode interpreter is also known as a virtual machine. It has one more step for generating bytecode instructions compared to the AST interpreter.
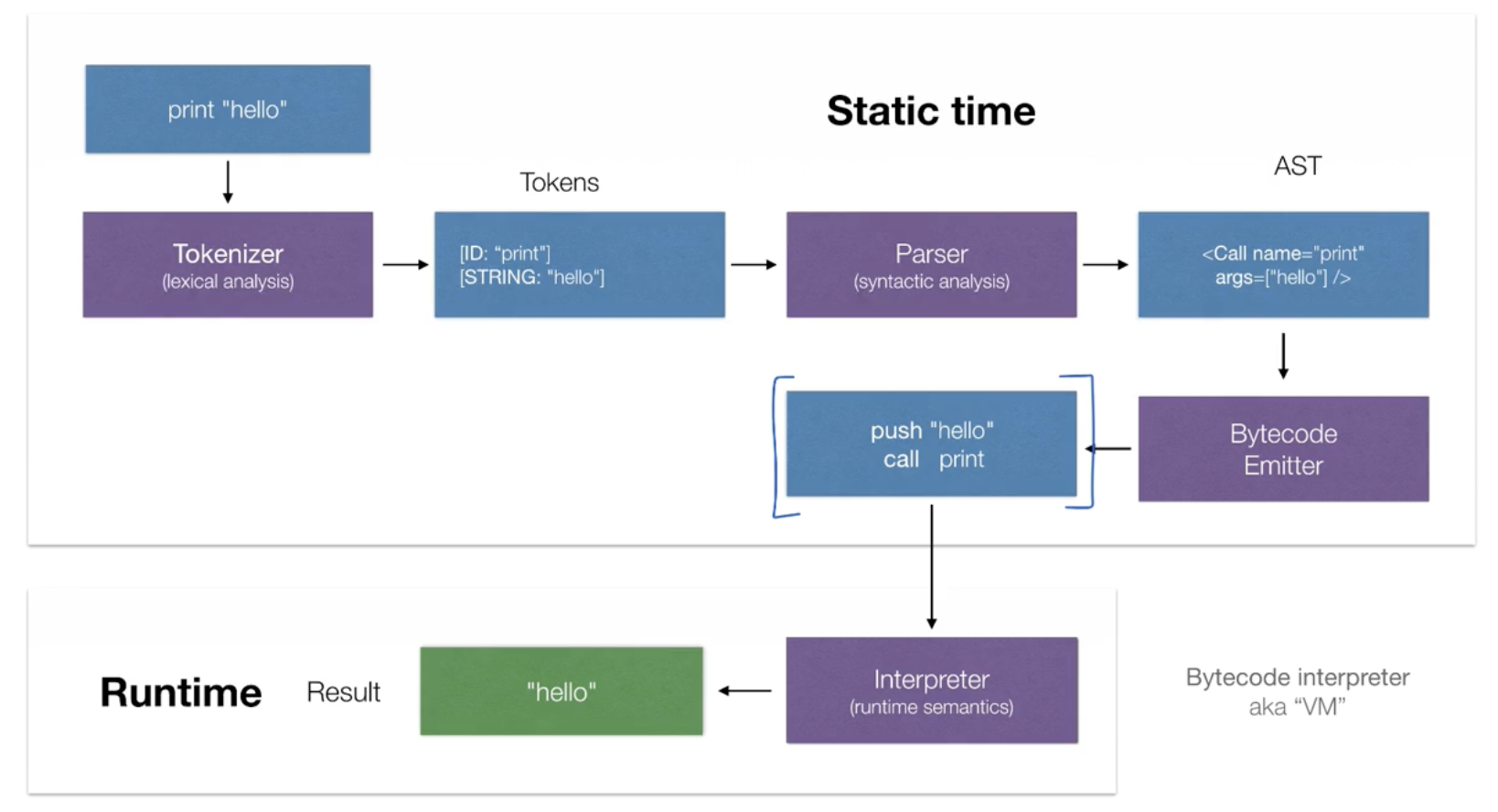
The reason we need this type of interpreter is that it produces memory/space efficient data structures (array of bytes) and is faster to traverse in contrast to tree-like data structures.
- Stack-based Machines
- Stack for operands and operators
- Result is “on top of the stack”
- Register-based machines
- Set of virtual registers
- Result is in “accumulator” register
- Mapped to real via register allocation
For Stack-based machines, take the following source code example, the produced bytecode can look something like this:
// Bytecode
push %15
set %0
push %0
push $10
add
push $5
sub
stack pointer(sp) and instruction pointer(ip) are the two most important pointers for any stack-based virtual machines.
S-Expressions
We will build a small toy language called Eva whose language rule can be outlined as follows:
//Expression format:
(+ 5 10) // addidtion
(set x 15) // assignment
(if (> x 10) // if
(print "ok")
(print "err")
)
// define a function:
(def foo (bar)
(+ bar 10))
// lambda function
(lambda (x) (* x x) 10)
// all functions in Eva are closures
(def createCounter()
(begin
(var i 0)
(lambda () (++i))
)
)
(var count (creatCounter))
(count) //1
(count) //2
// variable declaration
(var foo 10)
// assignment expression
(set foo 10)
Desgin goals
- Simple syntax: S-expression
- lambda functions, IILEs
- Everything is an expression
- Functional programming
- No explicit return; last evaluated expression is the result
- Imperative programming
- First-class functions: assgin to variables, pass as arguments, return as values
- Namespaces and modules
- Static scope: all functions are closures
- OOP: class-based, prototype-based
BNF (S-Expression)
Exp
: Atom
| List
;
Atom
: NUMBER { $$ = Number($1) }
| STRING
| SYMBOL
;
List
: '(' ListEntries ')' { $$ = $2 }
;
ListEntries
: ListEntries Exp { $1.push($2); $$ = $1 }
| /* empty */ { $$ = [] }
;
Environment
Environment is just a repository of variables and functions defined in the scope.
- Environment Record (actual storage)
- Optional reference to Parent Environment
Block
When entering a new block of code, a new environment will be created
(var x 10)
(print x) // 10
(begin
(set x 20)
(print x) // 20
)
(print x) // 10
Functions
// call to global `print` function
(print "Hellow World")
// call to global `+` function:
(+ ratio 30)
// function declaration
(var x 10)
(def foo() x)
(def bar()
(begin
(var x 20)
(+ (foo) x)
)
)
For function call, we need two things
- A new Activation Environment to store local variables and function parameters. The activation environment is also known as
- activation frame
- activation object
- activation record
- stack frame
- frame
- A parent link to capture parent scope
- A call stack for debugging. The stack is also known as
- execution stack
- control stack
- stack
It turns out that once we have the activation environment, if we don’t need to think about debugging, there is no need to build stacks for functions. All we need is a garbage collector that can clean up the objects stored in the activation environments. The environment itself can be allocated on heap.
Syntactic sugar
switch
The switch expression can be a syntax sugar of nested if-else expressions.
//Expression:
(switch
(<cond1> <block1>)
...
(<condN> <blockN>)
(else <alternate>)
)
// Example:
(switch
((> x 1) 100)
((= x 1) 200)
(else 0)
)
// Implementation
(if <cond1>
<block1>
...
(if <condN>
<blockN>
<alternate>
)
)
for
For loop is a syntax sugar of the while loop
// Expressions:
(for <init>
<condition>
<modifier>
<exp>
)
// Example:
(for (var x 10)
(> x 0)
(- x 1)
(print x)
)
// Implementation
(begin
<init>
(while <condition>
(begin
<exp>
<modifier>
)
)
)
OOP
There are generally two approaches to implement OOP: Class-based OOP and Prototype-based OOP.
- Classes and Instances (Inheritance chains)
(class Point null
(begin
(def constructor (self x y)
(begin
(set (prop self x) x)
(set (prop self y) y)
)
)
(def calc (self)
(+
(prop self x)
(prop self y)
)
)
)
)
(var p (new Point 10 20))
((prop p calc) p)
- Objects and Prototypes (Delegation chain)
(object base
(x 10)
(y 20)
)
(object child
(z 30)
(__proto__ base)
)
(prop child x) //10
(prop child z) //30
From the implementation perspective, a class is just a named environment which can be instantiated to create objects. Since it is an environment, it has an environment record (actual storage) and an optional reference to the parent environment.
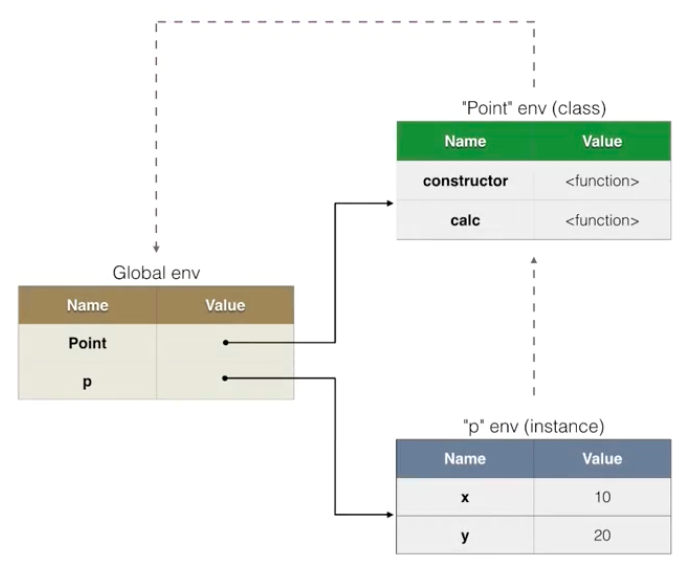
As you can see, the class is also an object that has its own space in memory similar to its instance.
Module
A module is nothing but a named first-class environment.
// `Math` module declaration
(module Math
(begin
(def abs (value)
(if (< value 0)
(- value)
value
)
)
(def square (x)
(* x x)
)
(var PI 3.1415926)
)
)