
CoreML Essentials
What is CoreML
CoreML is built on top of low-level frameworks such as Accelerate, BNNS and Metal Performance Shaders(MPS).
- Benefits of using CoreML includes:
- Flexible hardware usage: Depending on the user’s device, CoreML can run the model on the CPU, GPU, or Neural Engine, making optimal use of available hardware.
- Hybrid execution: The model can be split so that computationally intensive tasks run on the GPU while other parts remain on the CPU.
- Neural Engine support: On devices with an A12 chip or newer, CoreML can take advantage of the Neural Engine to significantly speed up inference.
- Downsides of using CoreML
- Limited layer types: Only a narrow set of network layers is officially supported. You can implement custom layers, but this means writing your own ML algorithms—and losing Neural Engine support.
- Unpredictable performance: Model speed may vary unexpectedly, indicating that CoreML’s scheduling strategies don’t always produce consistent results.
- Opaque runtime: The CoreML runtime is a “black box”, so there’s no guarantee that your model will always run on the Neural Engine.
The CoreML model format
CoreML models are stored in .mlmodel files, which use a protobuf format described by the coremltools package. The main specification is defined in Model.proto and includes:
- Model description: The model’s name, plus its input and output types.
- Model parameters: Parameters that represent a specific instance of the model.
- Metadata: Information about the model’s origin, license, and author.
Although a CoreML model is essentially a protobuf-based binary, .mlmodel files must be compiled into an intermediate format before they can run on actual devices.
Compile CoreML models
There are two methods for compiling CoreML models. One approach uses coremlc, an offline command-line tool included with Xcode. For instance, you can run the following command on your macOS machine:
xcrun coremlc compile ${MODEL_PATH} ${DST_PATH}
Running the command above on a .mlmodel file produces a .mlmodelc folder with the structure shown below.
├── analytics
│ └── coremldata.bin
├── coremldata.bin
├── metadata.json
├── model
│ └── coremldata.bin
├── model.espresso.net
├── model.espresso.shape
├── model.espresso.weights
├── model.rank.info.json
└── neural_network_optionals
└── coremldata.bin
Because the internal details of CoreML are not publicly documented, there’s no official explanation for each file. Here’s what we’ve discovered so far:
coremldata.bin: Contains metadata about the model, such as the author’s name and classification labels.model.espresso.net: A JSON-style description of the model’s structure, detailing the layers and how they connect.model.espresso.shape: Defines the output dimensions for each layer, consistent with what appears in the build output.model.espresso.weights: Stores the trained weights for the network (often large, for instance around 12 MB for MobileNetV2).model/coremldata.bin: The purpose of this file is still unclear.
“Espresso” is Apple’s internal codename for the part of CoreML that runs neural networks.
Another way to compile CoreML models is via the compileModelAtURL API at runtime, which essentially is how TensorFlowLite compiles its models.
The CoreML Performance
CoreML proves to be incredibly fast with most of the popular computer vision models, achieving an average of 4.3 ms iPhone 11. As a reference, the GPU inference time is about 17.59 ms. So where does this performance boost come from?
- CoreML has lower overhead and more efficient memory management.
- Regardless of the data type in the
.mlmodel(float32, float16, or quantized), CoreML internally converts the weights to half-precision floats when running on the GPU or Neural Engine. - It leverages the Neural Engine. If we set a symbolic breakpoint on
-[_ANEModel program]and saw it get triggered—which means ANE (Apple Neural Engine) was in play. (ANEModelis part of the privateAppleNeuralEngine.framework.)
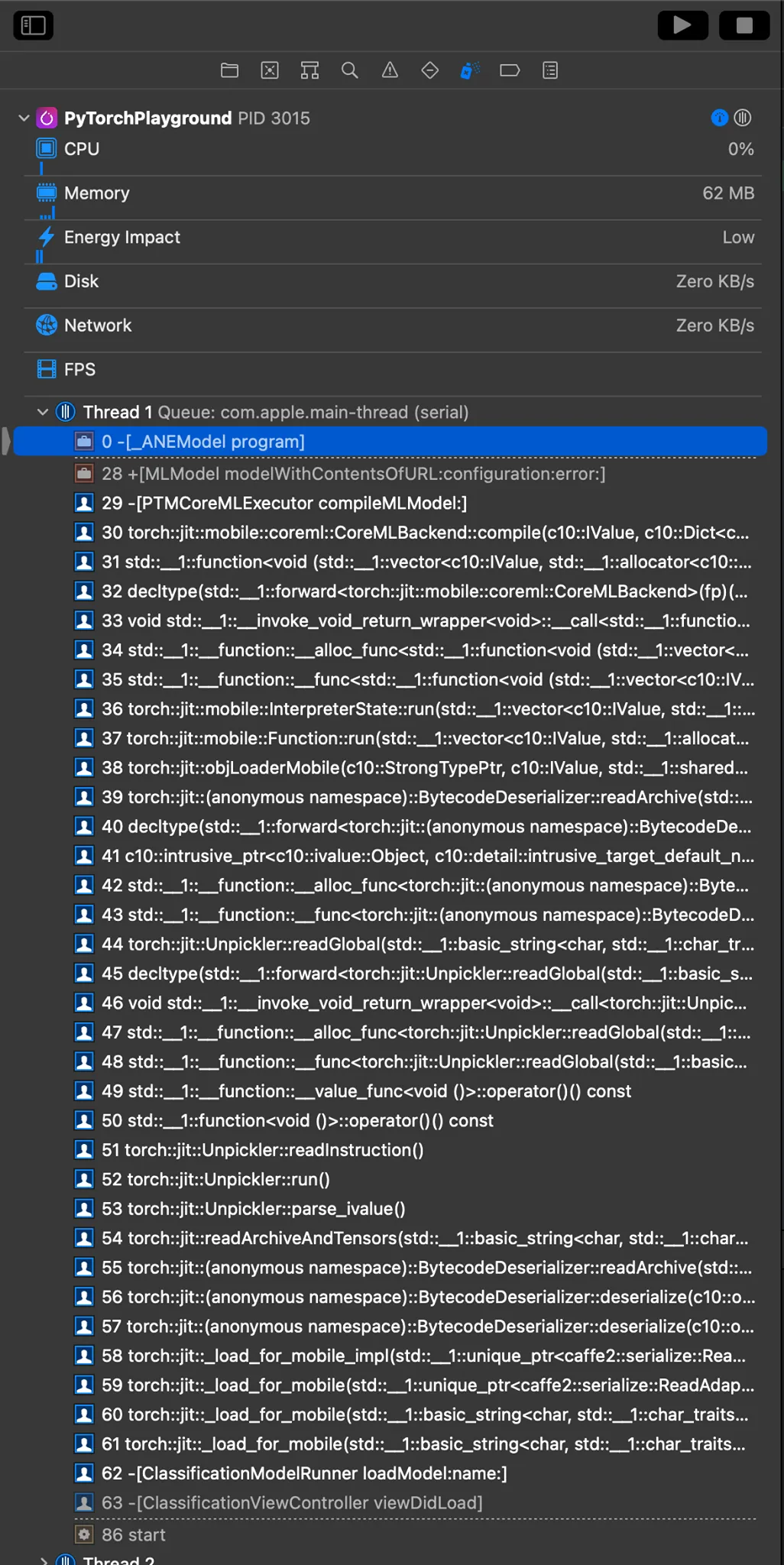
We can also use instrument to peek what’s running under the hood
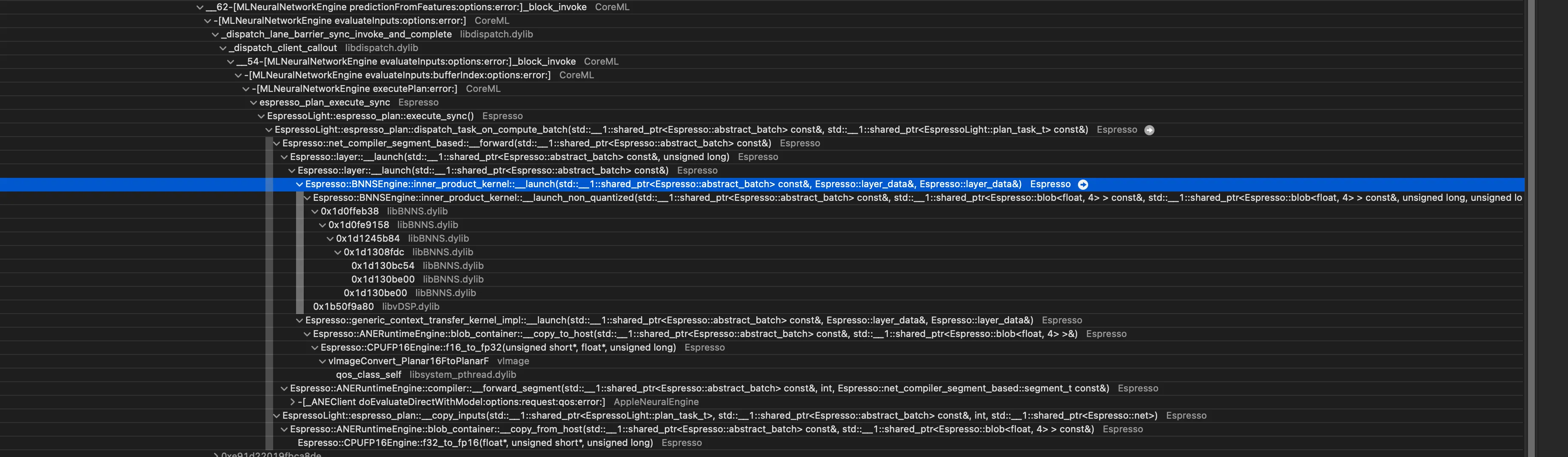
- Matrix multiplication with BNNS: CoreML relies on BNNS for matrix multiplication
- Mixed precision operations: Under the hood, Core ML performs operations like convolution in half precision (16-bit), keeps intermediate results in 32-bit, then stores the final outputs in 16-bit again.
Meanwhile, the GPU approach seems to introduce a lot of overhead. The command buffer execution alone took roughly 8.8 ms, yet the total runtime was 17.59 ms, which highlights the impact of that overhead. It may be worthwhile to explore a delegation-based GPU backend to see if we can boost performance further.