
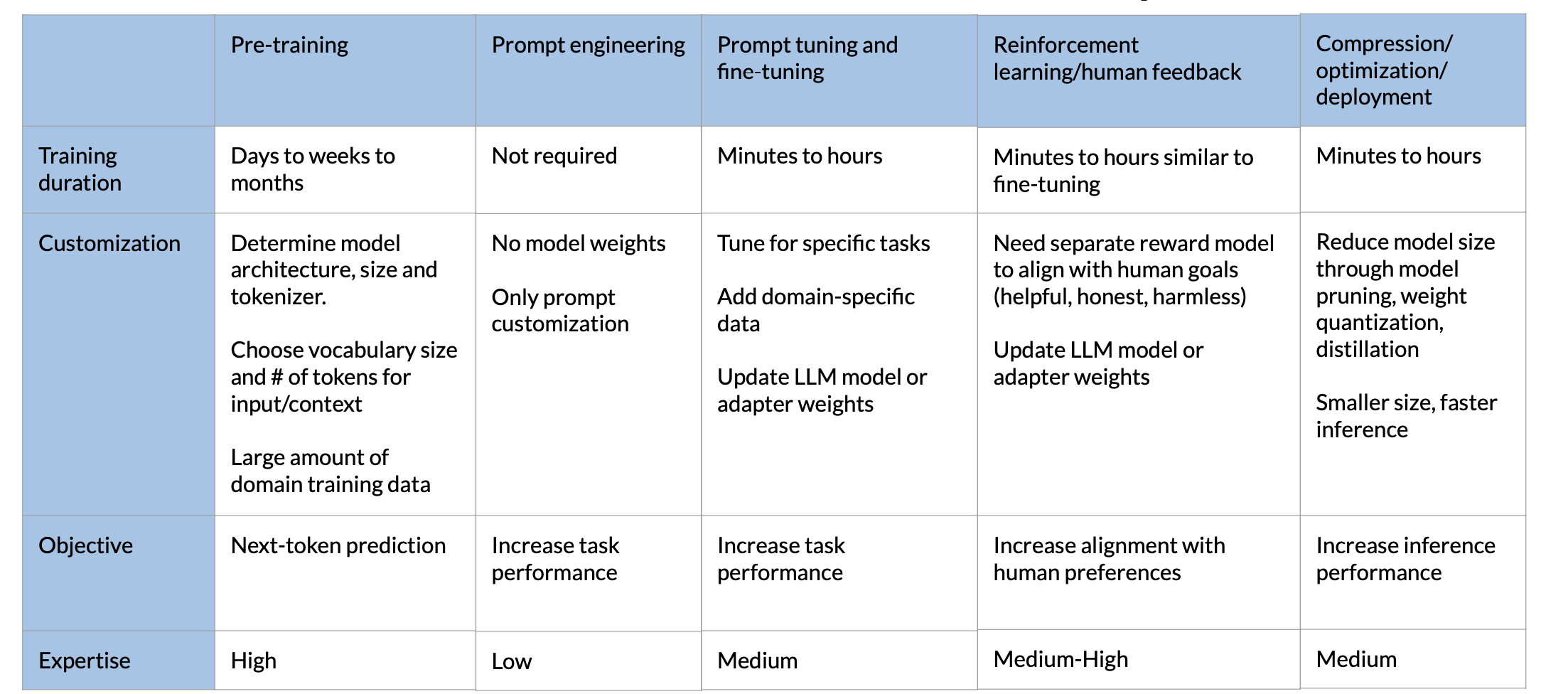
An Overview of LLM Training
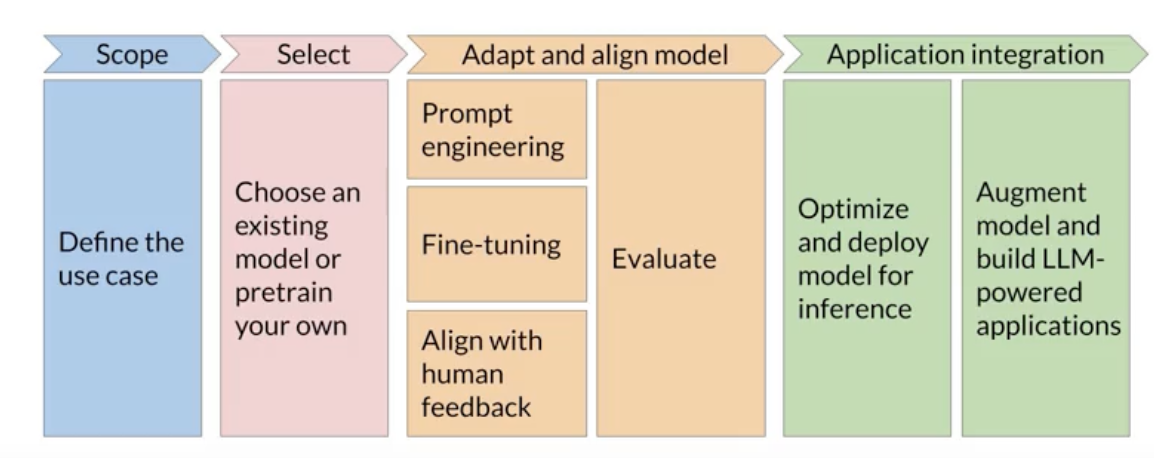
GenAI project lifecycle
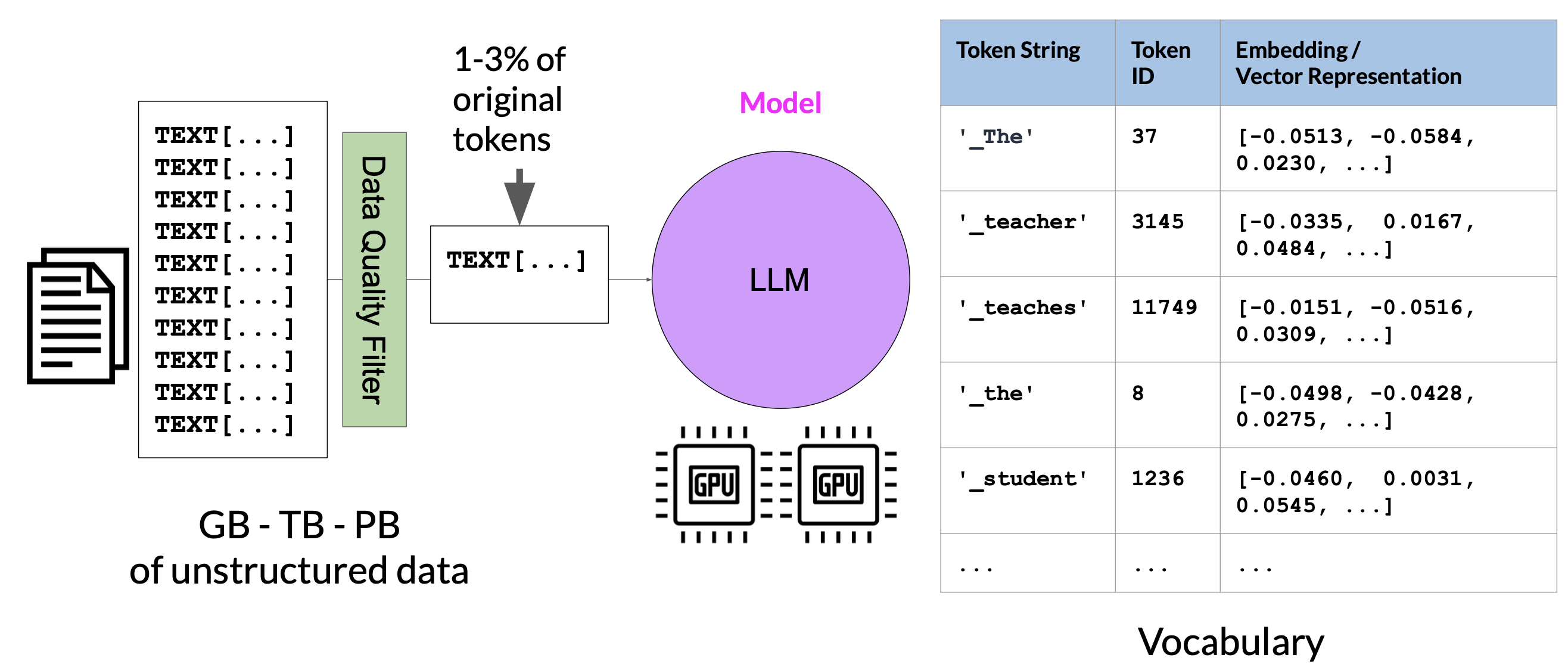
LLM pre-training at high level
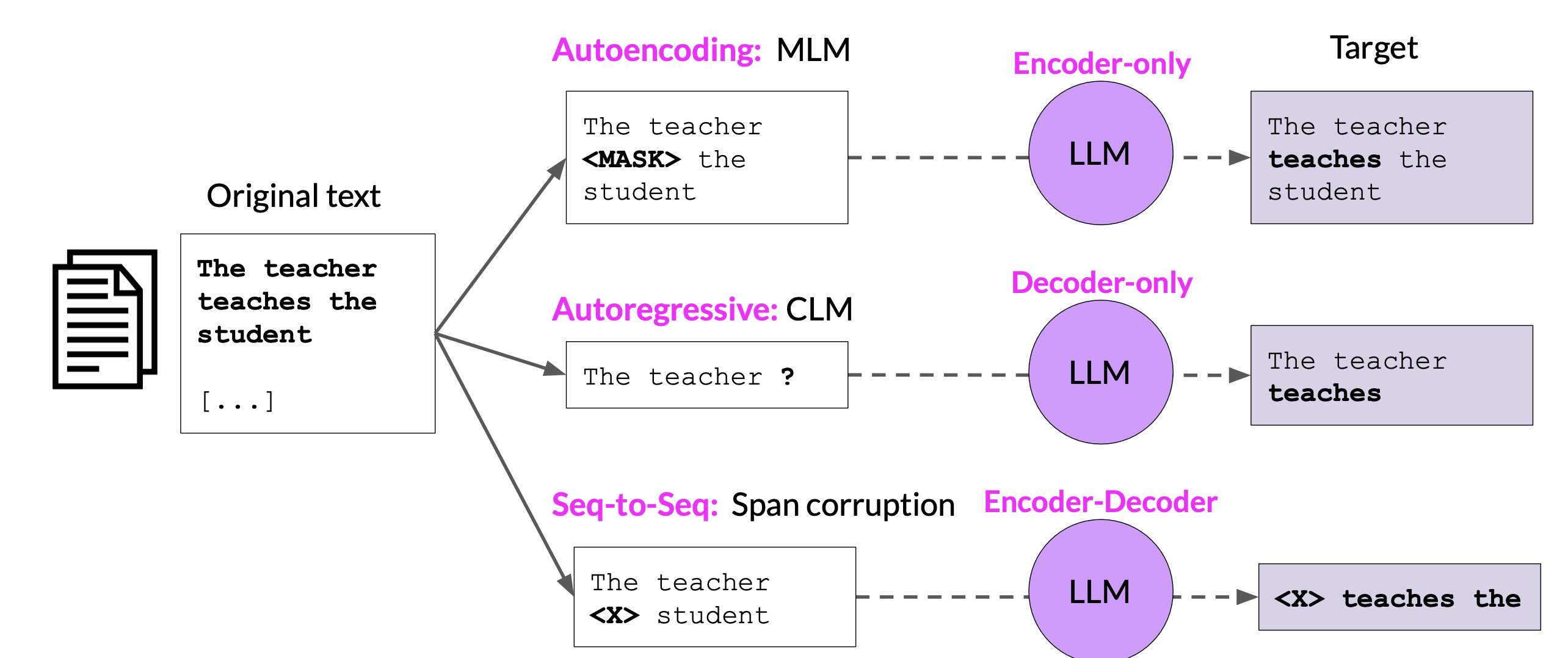
Encoder-Only Model
Encoder-only models are also known as Autoencoding models, and they are pre-trained using masked language modeling
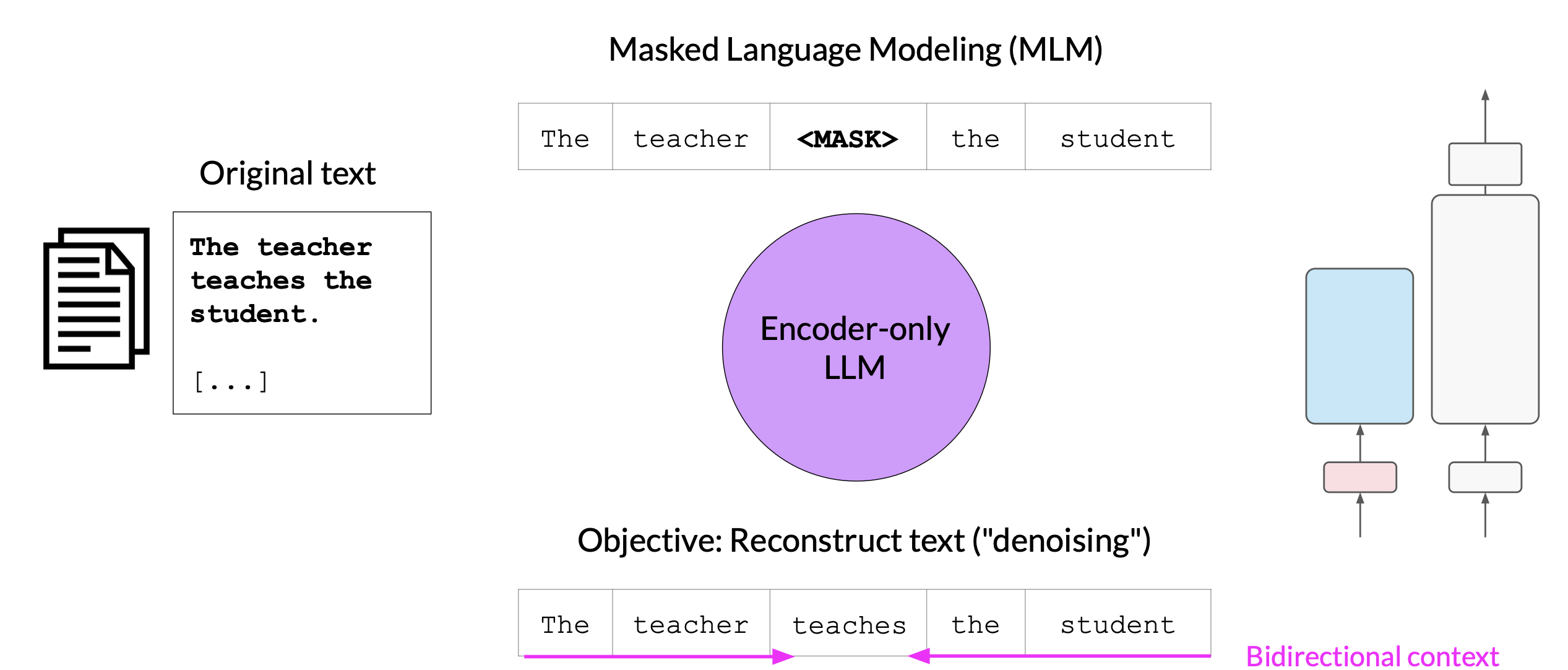
Here, tokens in the input sequence are randomly masked, and the training objective is to predict the mask tokens in order to reconstruct the original sentence. This is also called a denoising objective. Autoencoding models spilled bi-directional representations of the input sequence, meaning that the model has an understanding of the full context of a token and not just of the words that come before.
Good use cases:
- Sentiment analysis
- Named entity recognition
- Word classification
Example models:
- BERT
- ROBERTA
Decoder-Only Model
The decoder-only or autoregressive models are pre-trained using causal language modeling. The training objective is to predict the next token based on the previous sequence of tokens.
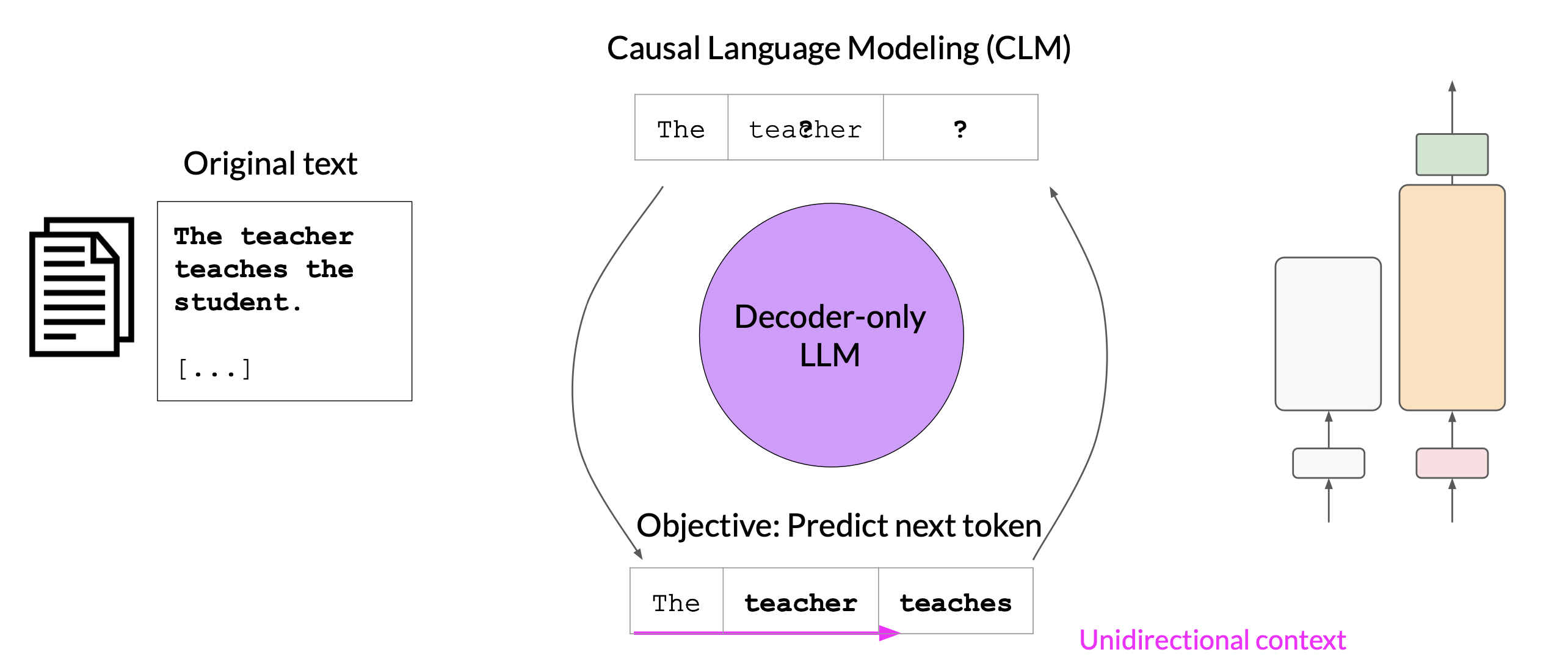
Decoder-based autoregressive models, mask the input sequence and can only see the input tokens leading up to the token in the question mark. The model has no knowledge of the end of the sentence. The model then iterates over the input sequence one by one to predict the following token.
In contrast to the encoder architecture, the context is unidirectional. By learning to predict the next token from a vast number of examples, the model builds up a statistical representation of language. Models of this type make use of the decoder component off the original architecture without the encoder.
Good use cases:
- Text generation
- Other emergent behavior
- Depends on the model size
Example models:
- GPT
- BLOOM
Sequence-to-Sequence Model
The final variation of the transformer model is the sequence-to-sequence model that uses both the encoder and decoder parts off the original transformer architecture.
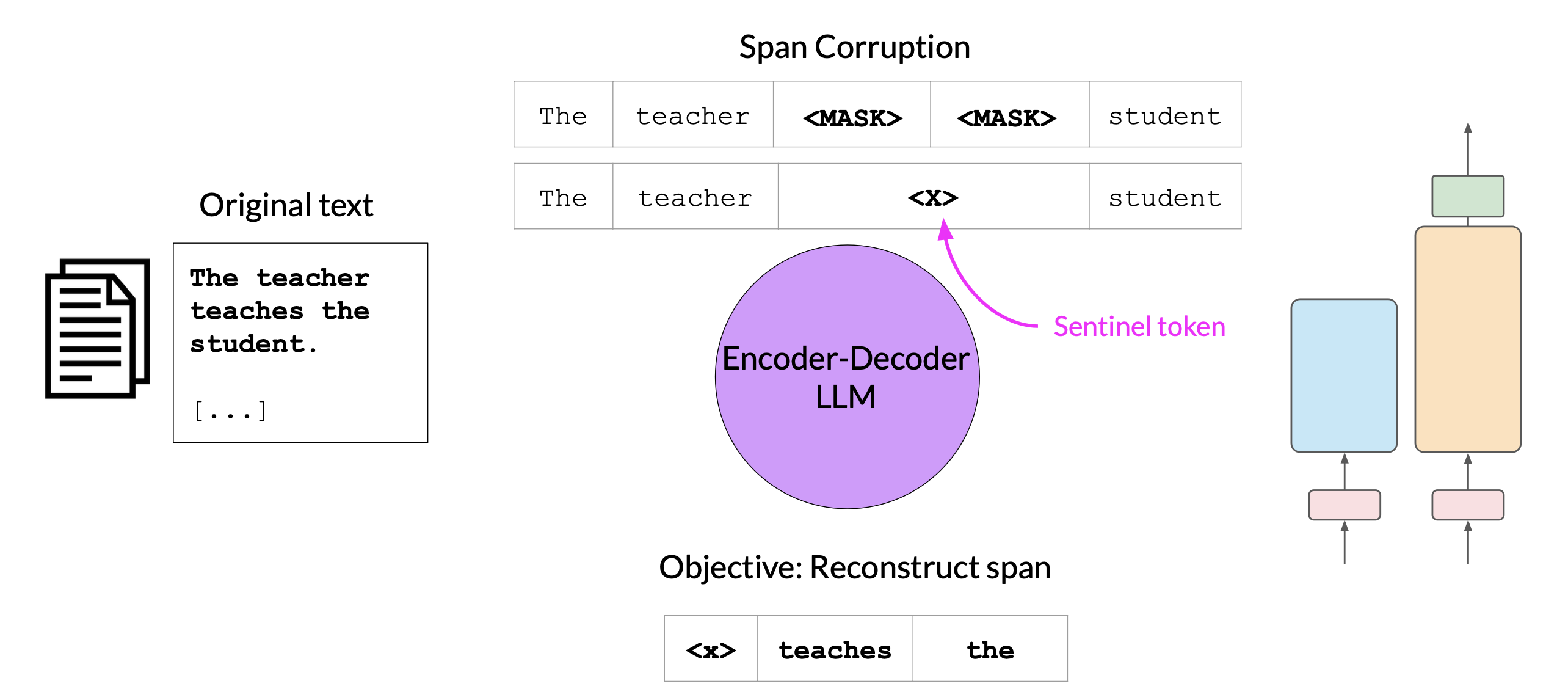
A popular sequence-to-sequence model T5, pre-trains the encoder using span corruption, which masks random sequences of input tokens.
Those masked sequences are then replaced with a unique Sentinel token, shown here as x. Sentinel tokens are special tokens added to the vocabulary, but do not correspond to any actual word from the input text.
The decoder is then tasked with reconstructing the mask token sequences auto-regressively. The output is the Sentinel token followed by the predicted tokens.
Good use cases:
- Translation
- Text summarization
- Question answering
Example models:
- T5
- BART
Summary
Computational Challenges
- Approximate GPU RAM needed to store 1B parameters
- 1 param (fp32) -> 4 bytes
- 1B params -> 4GB
- Additional GPU RAM needed to train 1B parameters
- weights -> +4 bytes per param
- Adam optimizer -> +8 bytes per param
- Gradients -> +4 bytes per param
- Activations and other temp memory -> +8 bytes per param
- In total we will need ~24GB GPU memory (fp32)
- As model sizes get larger, you will need to split your model across multiple GPUs for training
Quantization
- fp16 (2 bytes)
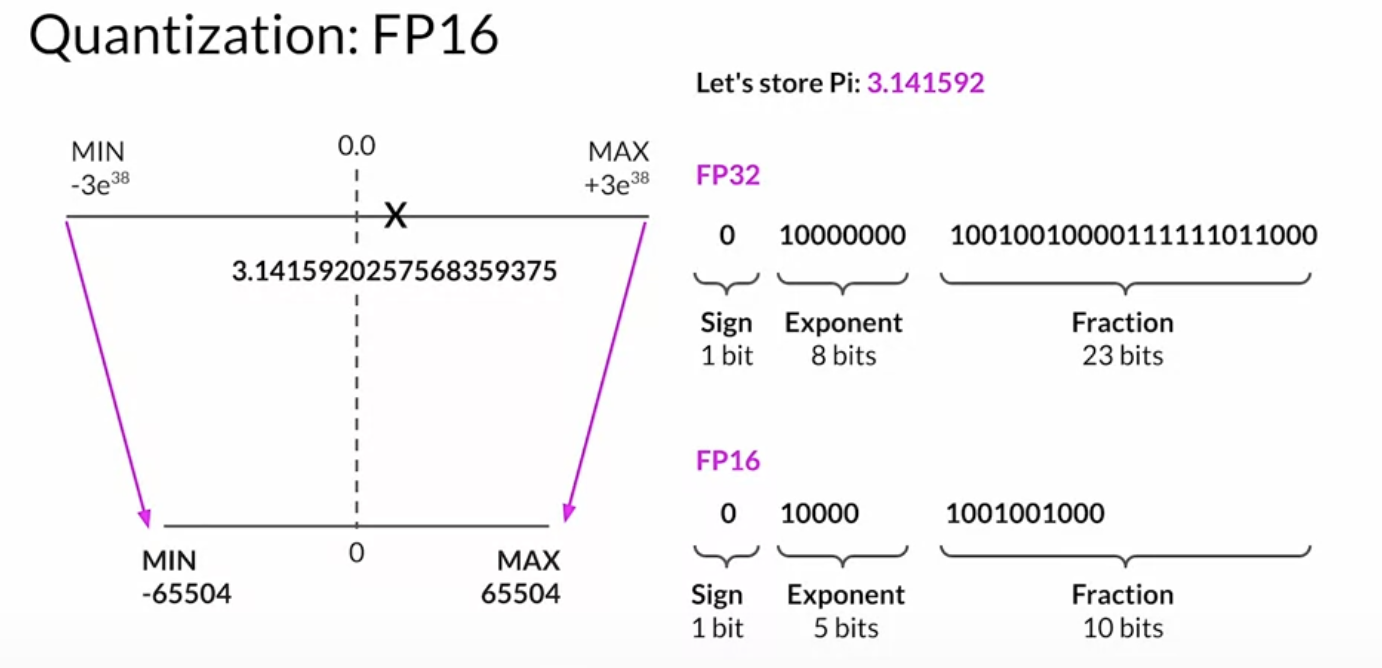
- int8 (1 byte)
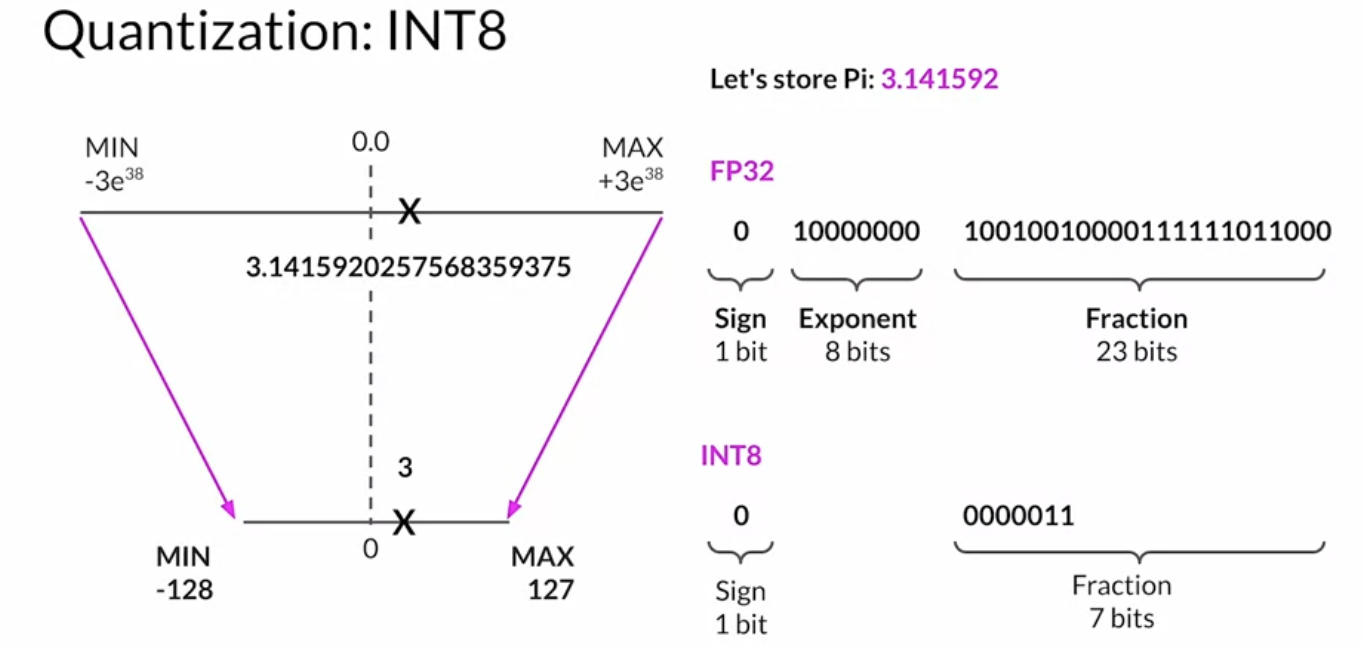
- Summary
- Reduce required memory to store and train models
- Projects original 32-bit float numbers into lower precision spaces
- Quantization-aware training(QAT) learns the quantizataion scaling factors during training
bfloat16is a popular choice
Multi-GPU Compute Strategies
- Distributed data parallel (DDP)
- copy the model to each GPU’s memory space (if the model can be fit into a single GPU)
- send batches of data to each GPU in parallel
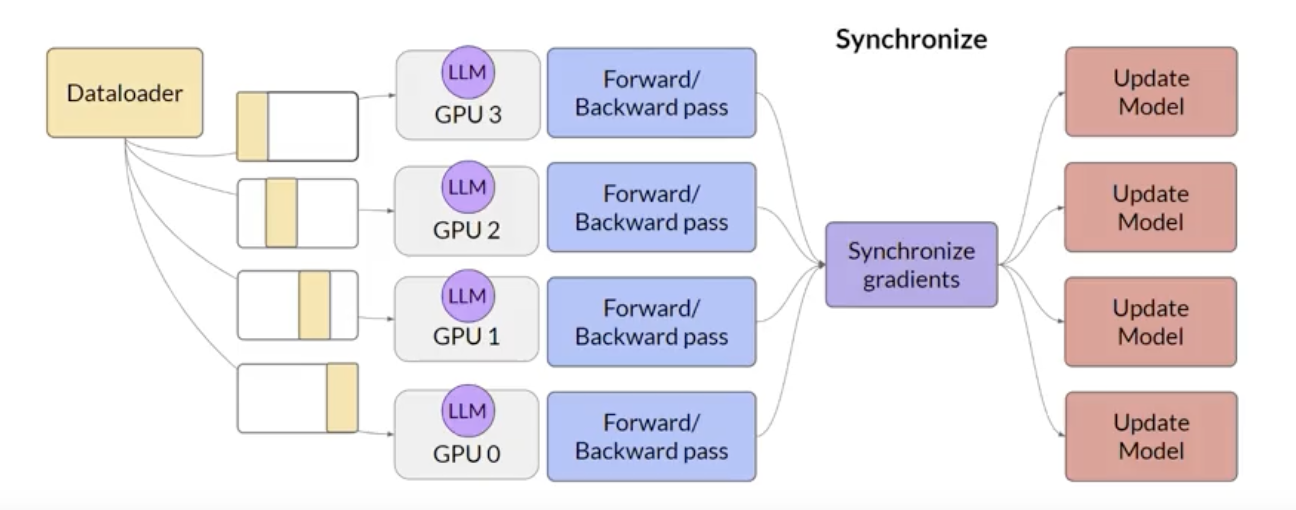
DDP copyists your model onto each GPU and sends batches of data to each of the GPUs in parallel. Each data-set is processed in parallel and then a synchronization step combines the results of each GPU, which in turn updates the model on each GPU, which is always identical across chips. This implementation allows parallel computations across all GPUs that results in faster training.
- Fully sharded data parallel (FSDP)
- Motivated by the “ZeRO” paper - zero data overlap between GPUs
- Reduce memory by distributing(sharding) the model parameters, gradients, and optimizer states across GPUs
- Supports offloading to CPU if needed
- Configure level of sharding via
sharding factor
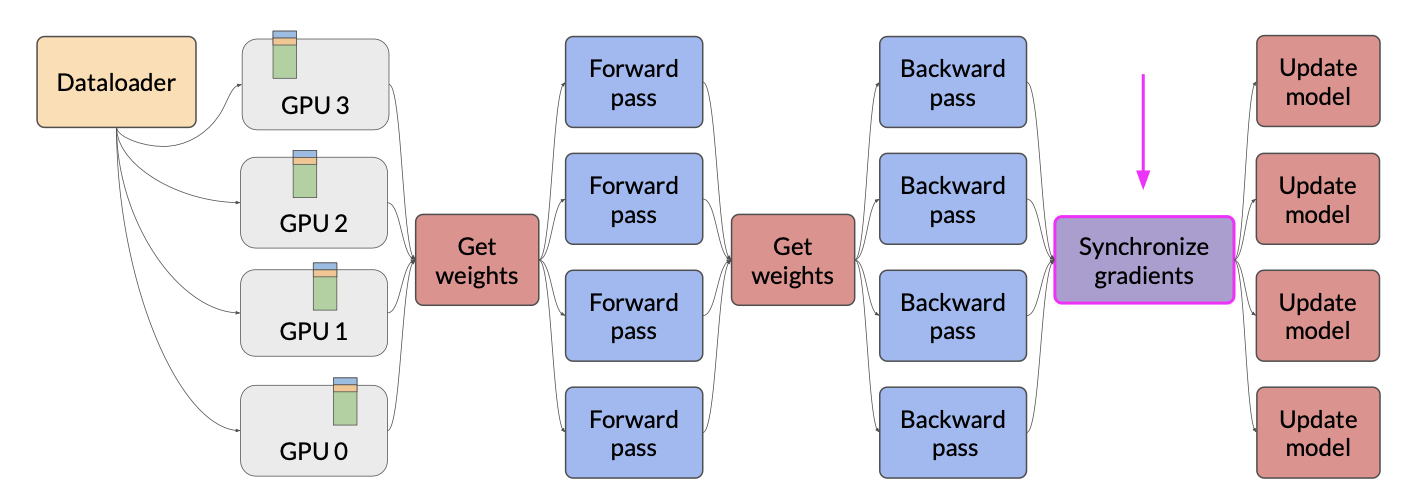
In contrast to DDP, where each GPU has all of the model states required for processing each batch of data available locally, FSDP requires you to collect this data from all of the GPUs before the forward and backward pass
Each CPU requests data from the other GPUs on-demand to materialize the sharded data into uncharted data for the duration of the operation. After the operation, you release the uncharted non-local data back to the other GPUs as original sharded data You can also choose to keep it for future operations during backward pass for example. Note, this requires more GPU RAM again, this is a typical performance versus memory trade-off decision. In the final step after the backward pass, FSDP is synchronizes the gradients across the GPUs in the same way they were for DDP.
Scaling laws and compute-optimal models
Researchers have explored the relationship between model size, training data size, compute budget and performance in an effort to determine just how big models need to be.
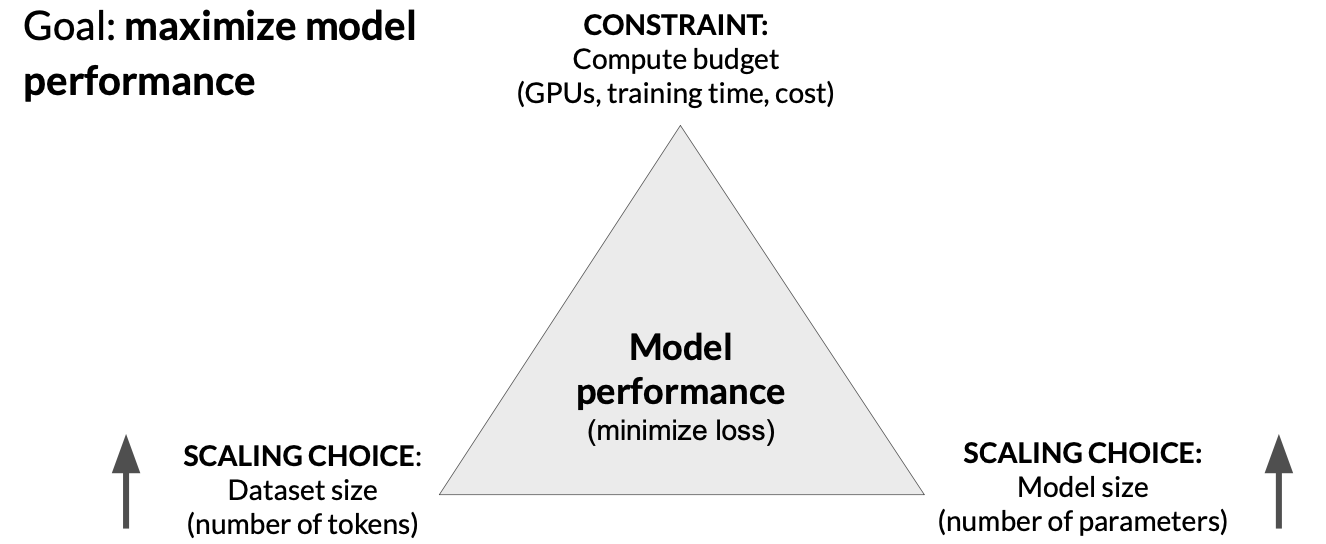
- compute budget
- model size
- data size
Compute budget for training LLMs
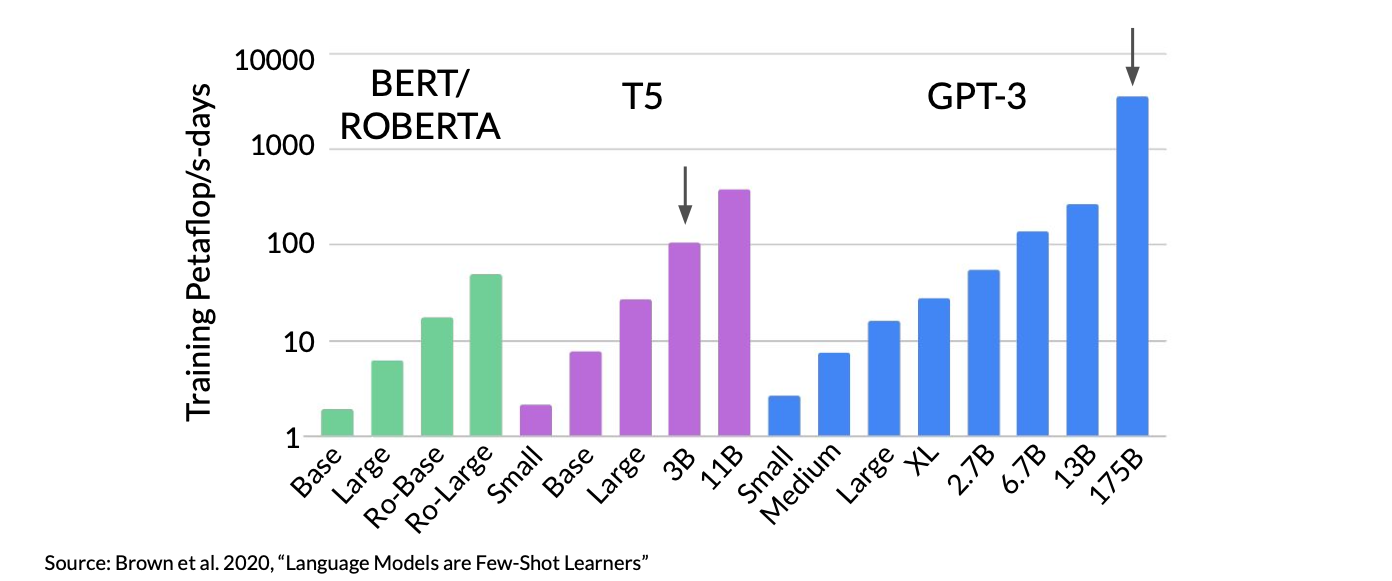
Let’s first define a unit of compute that quantifies the required resources. A petaFLOP per second day is a measurement of the number of floating point operations performed at a rate of one petaFLOP per second, running for an entire day
When specifically thinking about training transformers, one petaFLOP per second day is approximately equivalent to 8 NVIDIA V100 GPUs, operating at full efficiency for one full day.
If you have a more powerful processor that can carry out more operations at once, then a petaFLOP per second day requires fewer chips. For example, two NVIDIA A100 GPUs give equivalent compute to the eight V100 chips.
- Compute budget vs. model performance
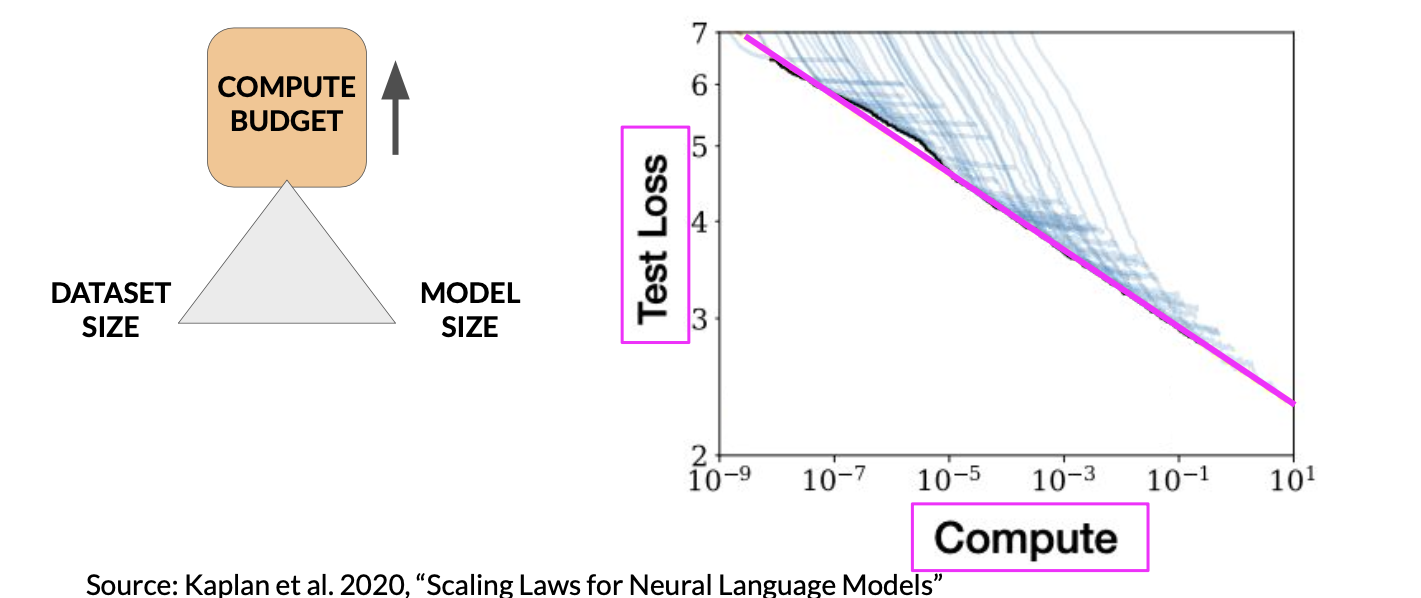
This suggests that you can just increase your compute budget to achieve better model performance. In practice however, the compute resources you have available for training will generally be a hard constraint set by factors such as the hardware you have access to, the time available for training and the financial budget of the project
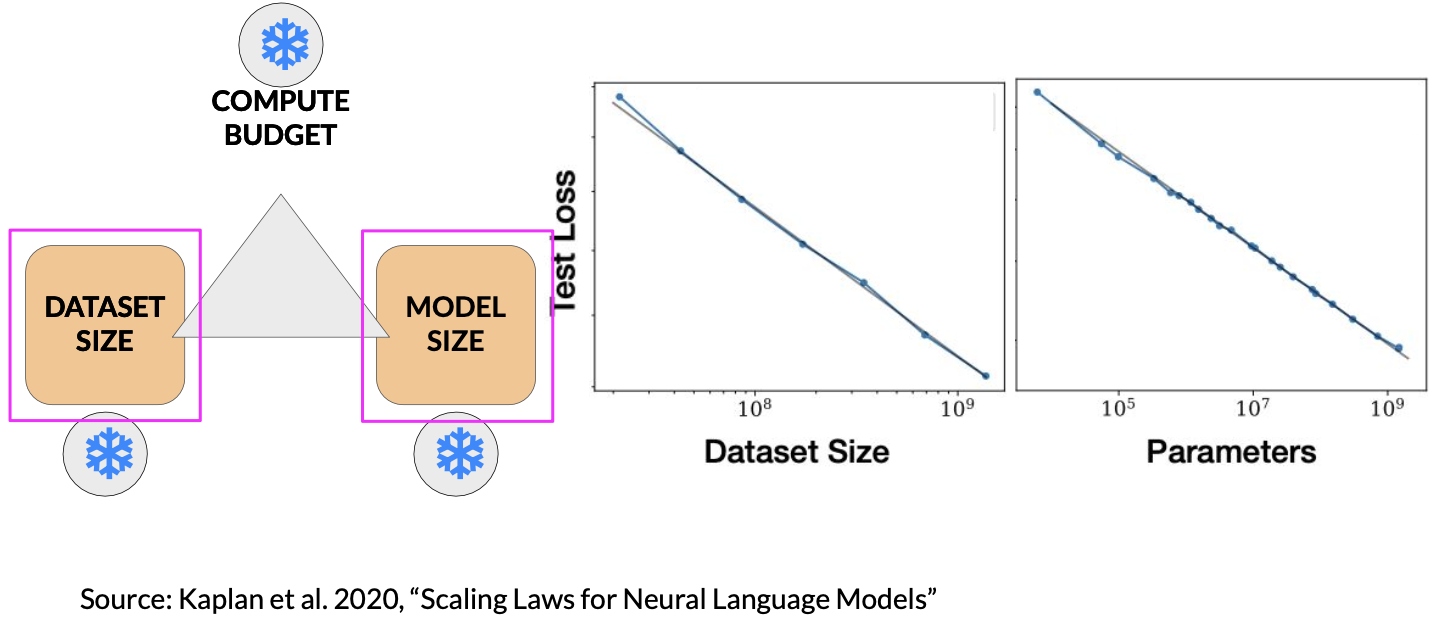
- Dataset size and model size vs. performance
If we give a fixed value for compute budget. The increase of data size and model size can all lead to a better model performance
The Chinchilla paper
There is a paper published in 2022. The goal was to find the optimal number of parameters and volume of training data for a given compute budget.
- very large models (e.g. GPT3) may be
over-parameterizedandunder-trained. - Smaller models trained on more data could perform as well as large models
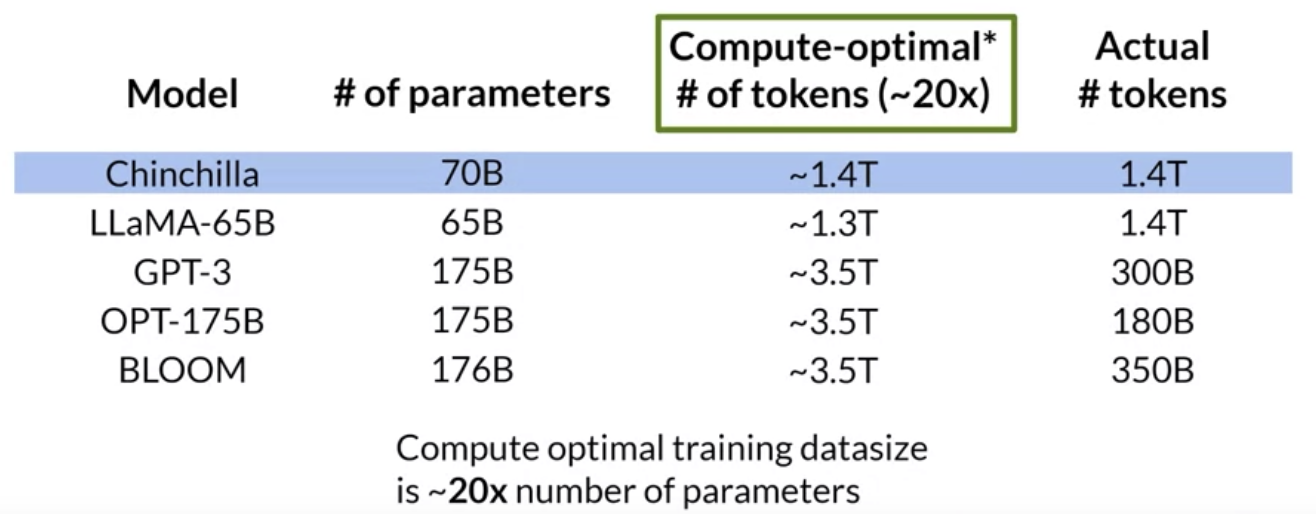
One important takeaway is that the optimal training dataset size for a given model is about 20 times larger than the number of parameters in the model.
The BloombergGPT was trained in a compute optimal way following the Chinchilla loss and so achieves good performance with the size of 50 billion parameters.
Pre-training for domain adaptation
So far, we’ve emphasized that you’ll generally start with an existing LLM as you develop your application. However, there are domain specific situation where you may find it necessary to pretrain your own model from scratch. For example, legal languages, medical languages.
“sig: 1 tab po qid pc & hs” meaning Take one tablet by mouth four times a day, after meal and at bedtime
A good example here is the BloombergGPT model, which was trained using an extensive financial dataset comprising news articles, reports, and market data, to increase its understanding of finance and enabling it to generate finance-related natural language text.
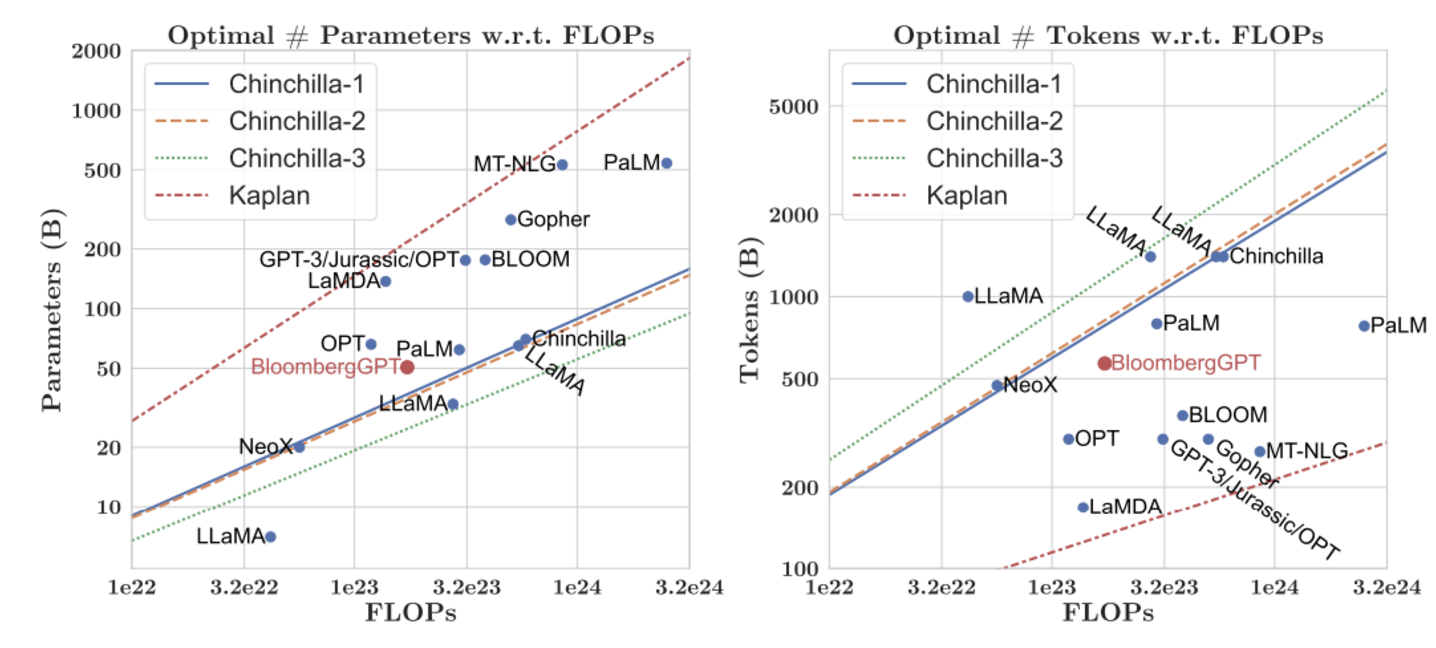
During the training of BloombergGPT, the authors used the Chinchilla Scaling Laws to guide the number of parameters in the model and the volume of training data, measured in tokens. The recommendations of Chinchilla are represented by the lines Chinchilla-1, Chinchilla-2 and Chinchilla-3 in the image, and we can see that BloombergGPT is close to it.
The recommended configuration was 50 billion parameters and 1.4 trillion training tokens. However, acquiring 1.4 trillion tokens of training data in the finance domain proved challenging. Consequently, they constructed a dataset containing just 700 billion tokens, less than the compute-optimal value. Furthermore, due to early stopping, the training process terminated after processing 569 billion tokens.
The BloombergGPT project is a good illustration of pre-training a model for increased domain-specificity, and the challenges that may force trade-offs against compute-optimal model and training configurations.
Resources
- Scaling Laws for Neural Language Models
- What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
- LLaMA: Open and Efficient Foundation Language Models
- Language Models are Few-Shot Learners
- Training Compute-Optimal Large Language Models
- BloombergGPT: A Large Language Model for Finance