
LLM Fine-tuning with RLHF
Fine-tuning with human feedback(RLHF)
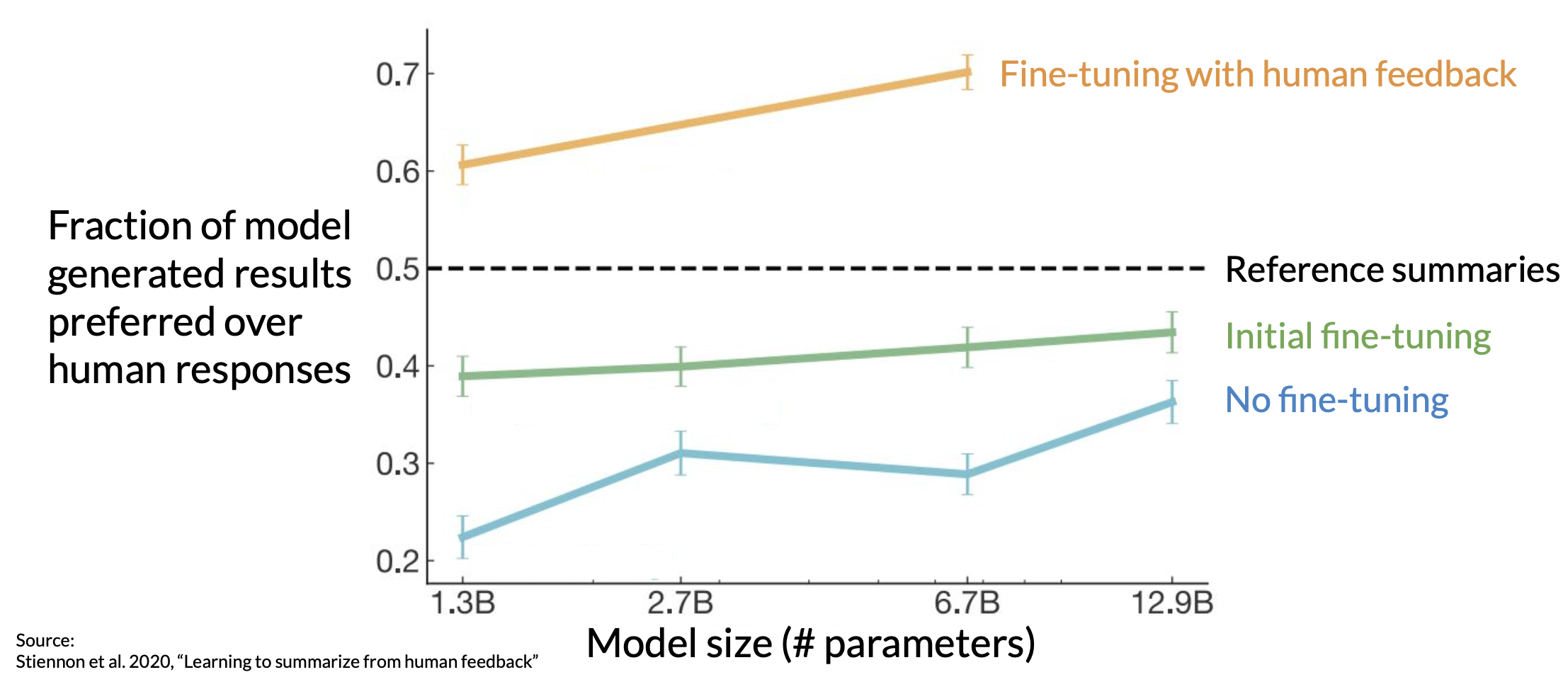
In 2020, researchers at OpenAI published a paper that explored the use of fine-tuning with human feedback to train a model to write short summaries of text articles
A popular technique to fine-tune large language models with human feedback is called reinforcement learning from human feedback, or RLHF for short.
Reinforcement learning (RL) overview
Reinforcement learning is a type of machine learning in which an agent learns to make decisions related to a specific goal by taking actions in an environment, with the objective of maximizing some notion of a cumulative reward.
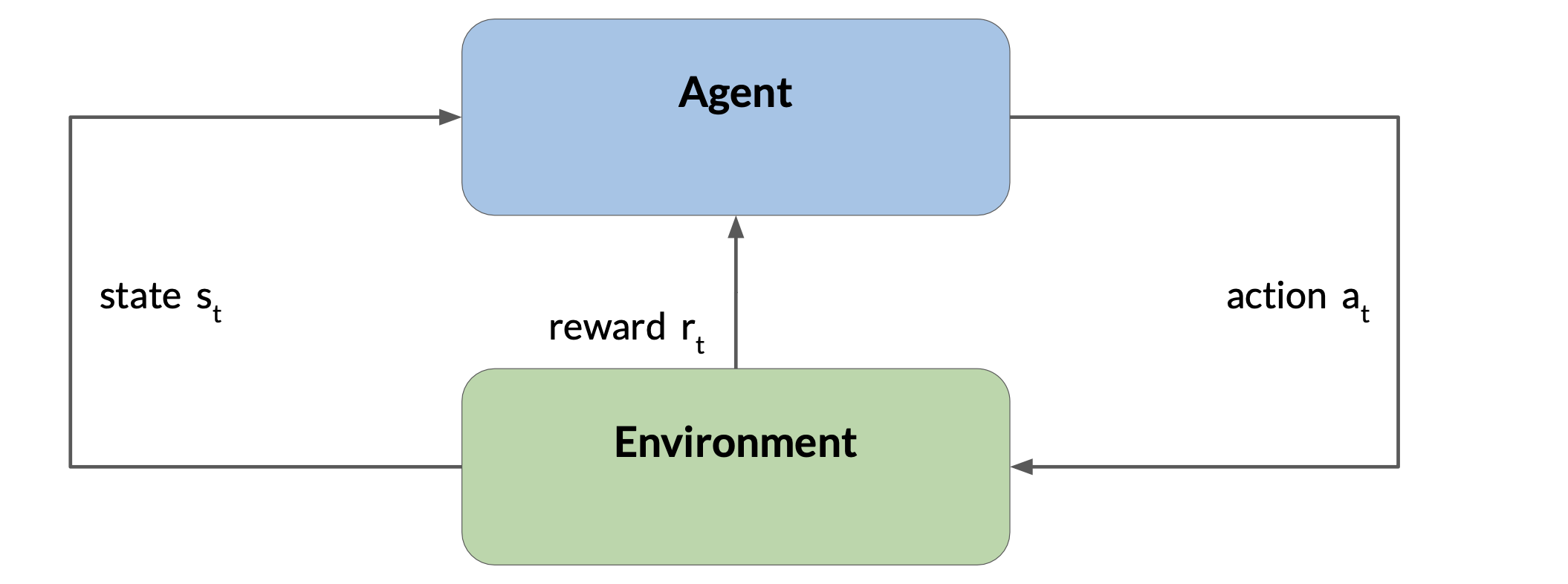
In this framework, the agent continually learns from its experiences by taking actions, observing the resulting changes in the environment, and receiving rewards or penalties, based on the outcomes of its actions. By iterating through this process, the agent gradually refines its strategy or policy to make better decisions and increase its chances of success. The series of actions taken by the model and corresponding states form a result, often called a rollout
Reinforcement learning: fine-tune LLMs
-
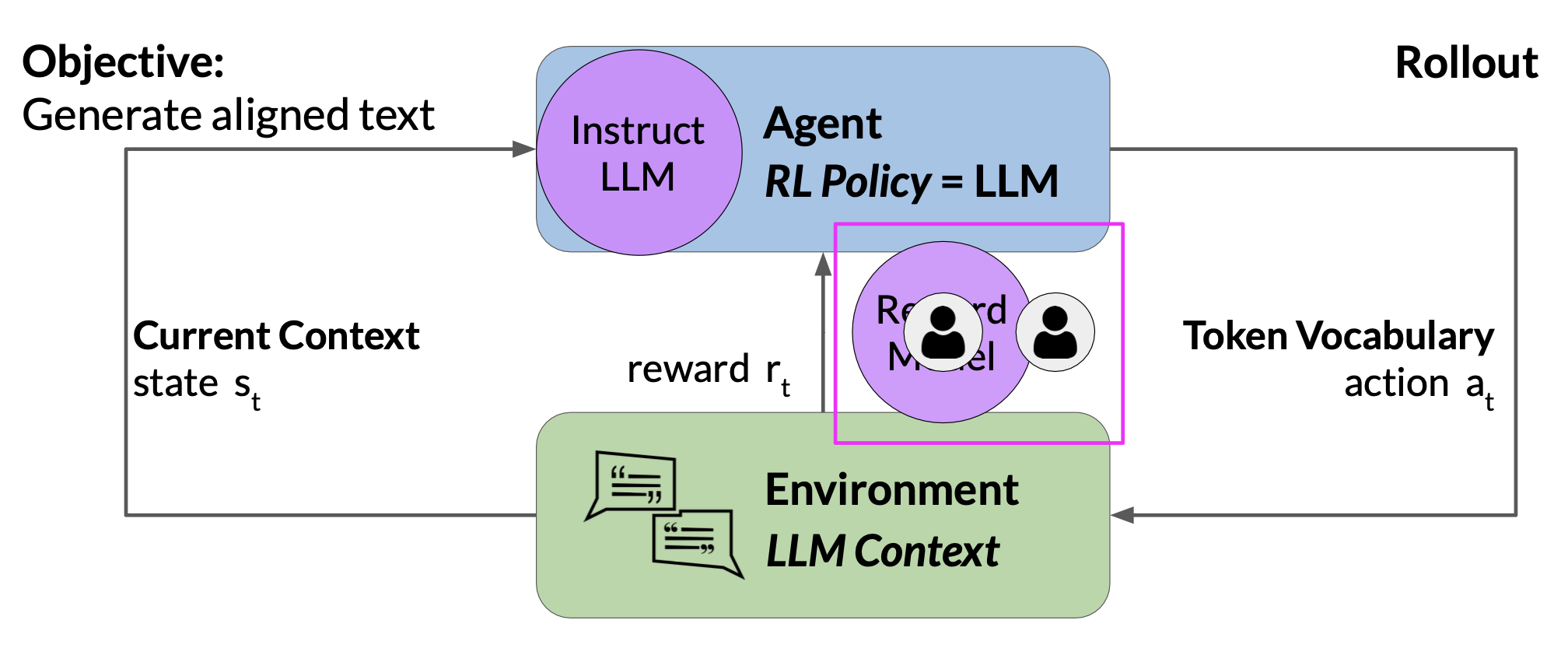
In the LLM world, the agent’s policy that guides the actions is the LLM, and its objective is to generate text that is perceived as being aligned with the human preferences
-
The environment is the context window of the model, the space in which text can be entered via a prompt
-
The state that the model considers before taking an action is the current context. That means any text currently contained in the context window
-
The action here is the act of generating text. This could be a single word, a sentence, or a longer form text, depending on the task specified by the user. The sequence of actions and states is called a rollout
-
The action space is the token vocabulary, meaning all the possible tokens that the model can choose from to generate the completion
At any given moment, the action that the model will take, meaning which token it will choose next, depends on the prompt text in the context and the probability distribution over the vocabulary space. The reward is assigned based on how closely the completions align with human preferences.
One way you can do this is to have a human evaluate all of the completions of the model against some alignment metric, such as determining whether the generated text is toxic or non-toxic. This feedback can be represented as a scalar value, either a zero or a one. The LLM weights are then updated iteratively to maximize the reward obtained from the human classifier, enabling the model to generate non-toxic completions.
However, obtaining human feedback can be time consuming and expensive. As a practical and scalable alternative, you can use an additional model, known as the reward model, to classify the outputs of the LLM and evaluate the degree of alignment with human preferences.
You’ll start with a smaller number of human examples to train the secondary model by your traditional supervised learning methods. Once trained, you’ll use the reward model to assess the output of the LLM and assign a reward value
The reward model is the central component of the reinforcement learning process. It encodes all of the preferences that have been learned from human feedback, and it plays a central role in how the model updates its weights over many iterations
Collecting human feedback
Starting with a fine-tuned LLM to generate some completions. Then we need to use human workforce to hand-pick the ones that we think meets the criteria.
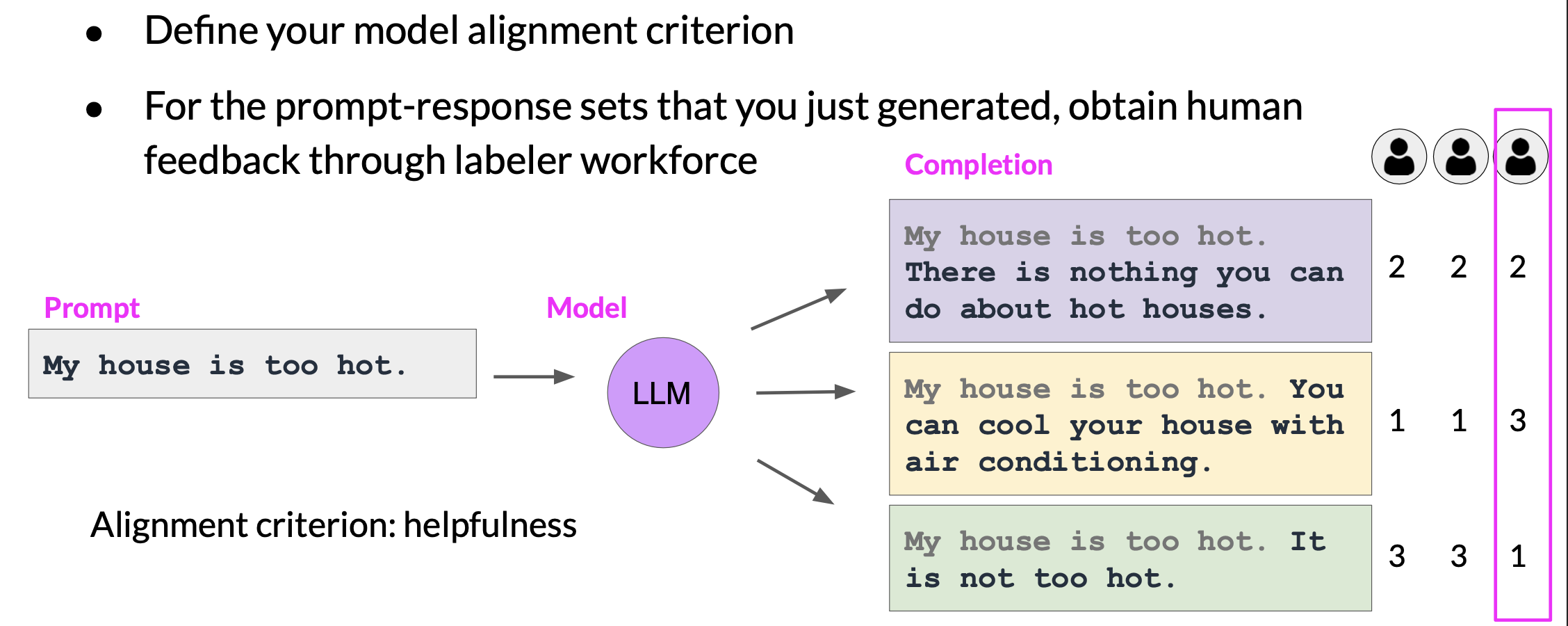
This process then gets repeated for many prompt completion sets, building up a data set that can be used to train the reward model.
Prepare labeled data for training
Once your human labelers have completed their assessments off the Prom completion sets, you have all the data you need to train the reward model

- In the example shown here, there are three completions to a prompt, and the ranking assigned by the human labelers was
2, 1, 3, as shown, where1is the highest rank corresponding to the most preferred response. - With the three different completions, there are three possible pairs purple-yellow, purple-green and yellow-green. Depending on the number
Nof alternative completions per prompt, you will haveNchoosetwocombinations - For each pair, you will assign a reward of
1for the preferred response and a reward of0for the less preferred response - Then you’ll reorder the prompts so that the preferred option comes first. This is an important step because the reward model expects the preferred completion, which is referred to as $Y_{j}$ first.
Train the reward model
This reward model is usually also a language model. For example, a BERT that is trained using supervised learning methods on the pairwise comparison data that you prepared from the human labelers assessment above.
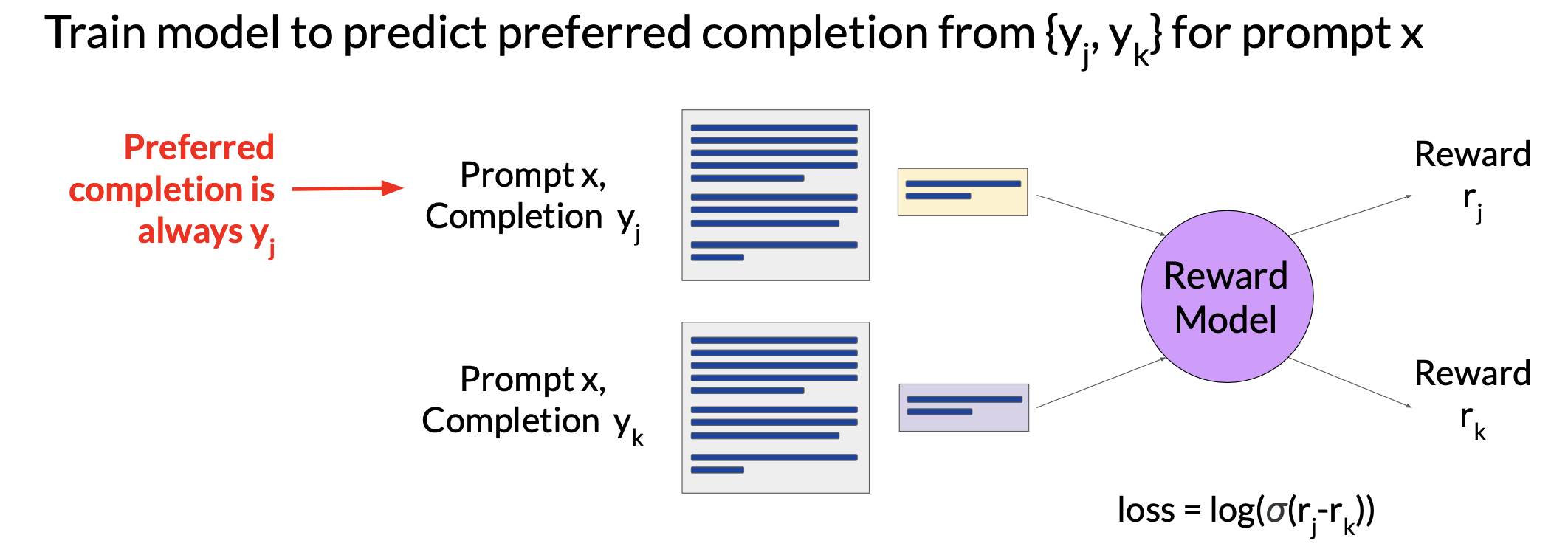
For a given prompt X, the reward model learns to favor the human-preferred completion $y_{j}$, while minimizing the loss sigmoid off the reward difference, $r_{j} - r_{k}$.
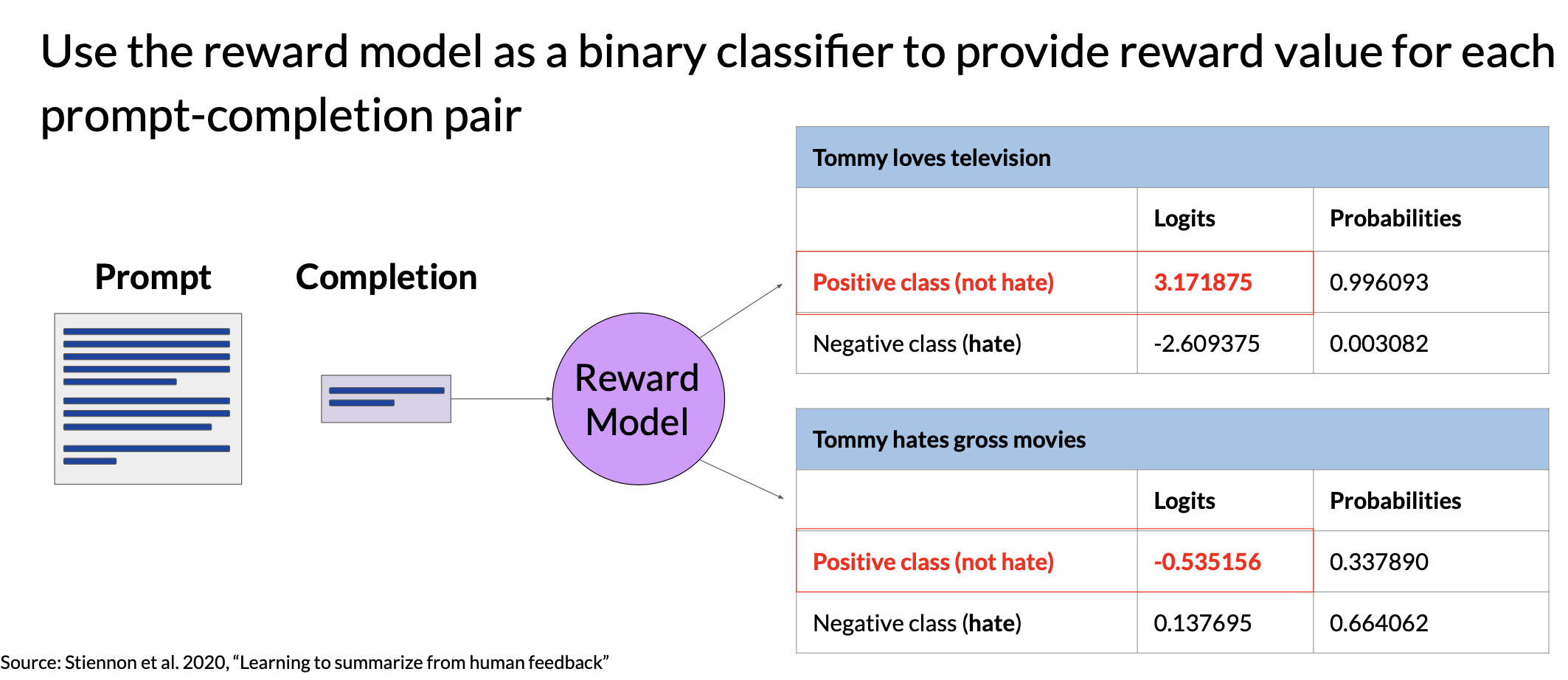
Use the reward model
Once the model has been trained, you can use the reward model as a binary classifier to provide a set of logics across the positive and negative classes
Fine-tuning with RLHF
Let’s bring everything together, and look at how you will use the reward model in the reinforcement learning process to update the LLM weights, and produce a human aligned model.
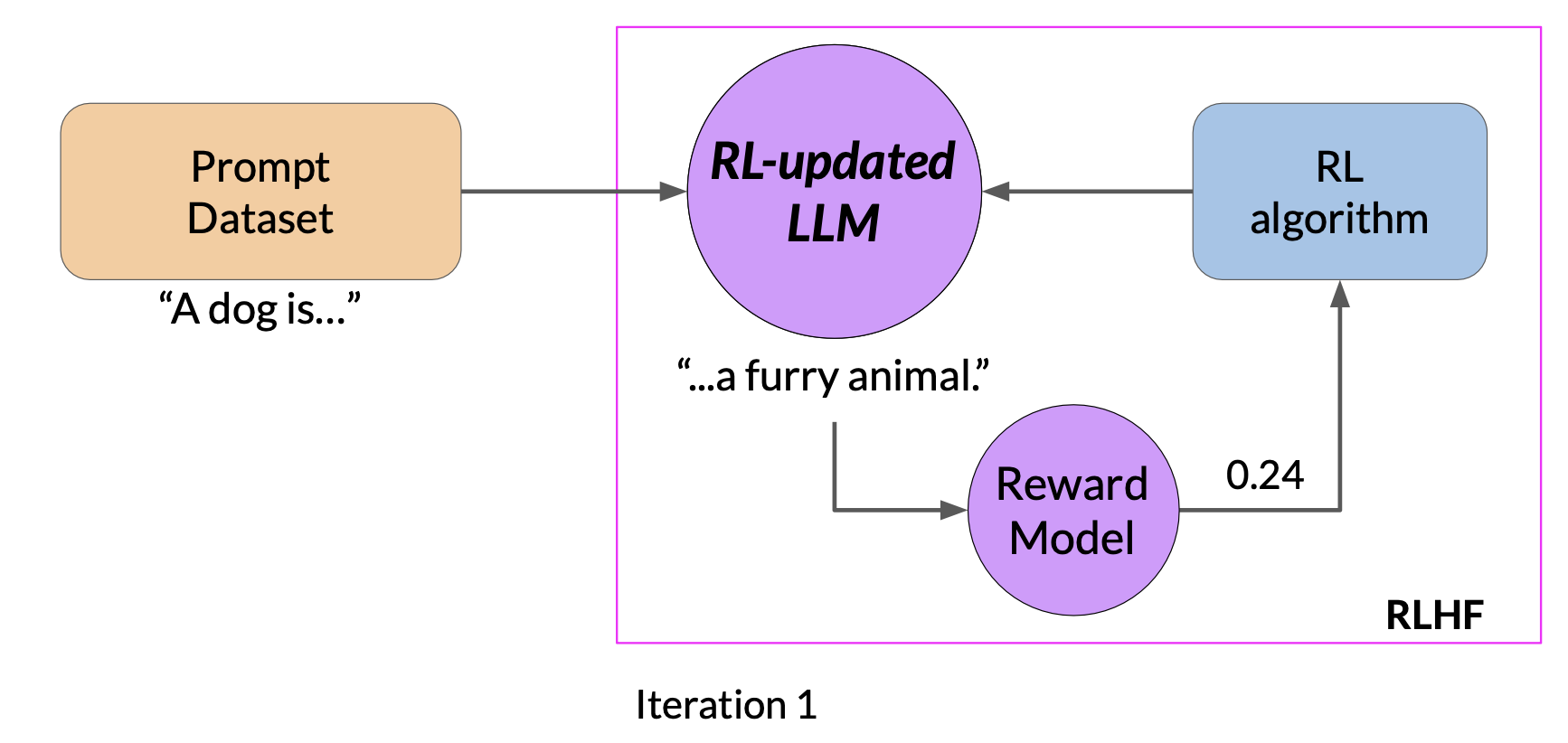
- First, you’ll pass a prompt from your prompt dataset. In this case,
a dog is, to the instruct LLM, which then generates a completion, in this casea furry animal. - Next, you sent this completion, and the original prompt to the reward model as the prompt completion pair
- The reward model evaluates the pair based on the human feedback it was trained on, and returns a reward value. A higher value such as
0.24as shown here represents a more aligned response - You’ll then pass this reward value for the prom completion pair to the reinforcement learning algorithm to update the weights of the LLM, and move it towards generating more aligned, higher reward responses. Let’s call this intermediate version of the model the RL updated LLM
These iterations continue for a given number of epics, similar to other types of fine tuning.
If the process is working well, you’ll see the reward improving after each iteration as the model produces text that is increasingly aligned with human preferences. You will continue this iterative process until your model is aligned based on some evaluation criteria.
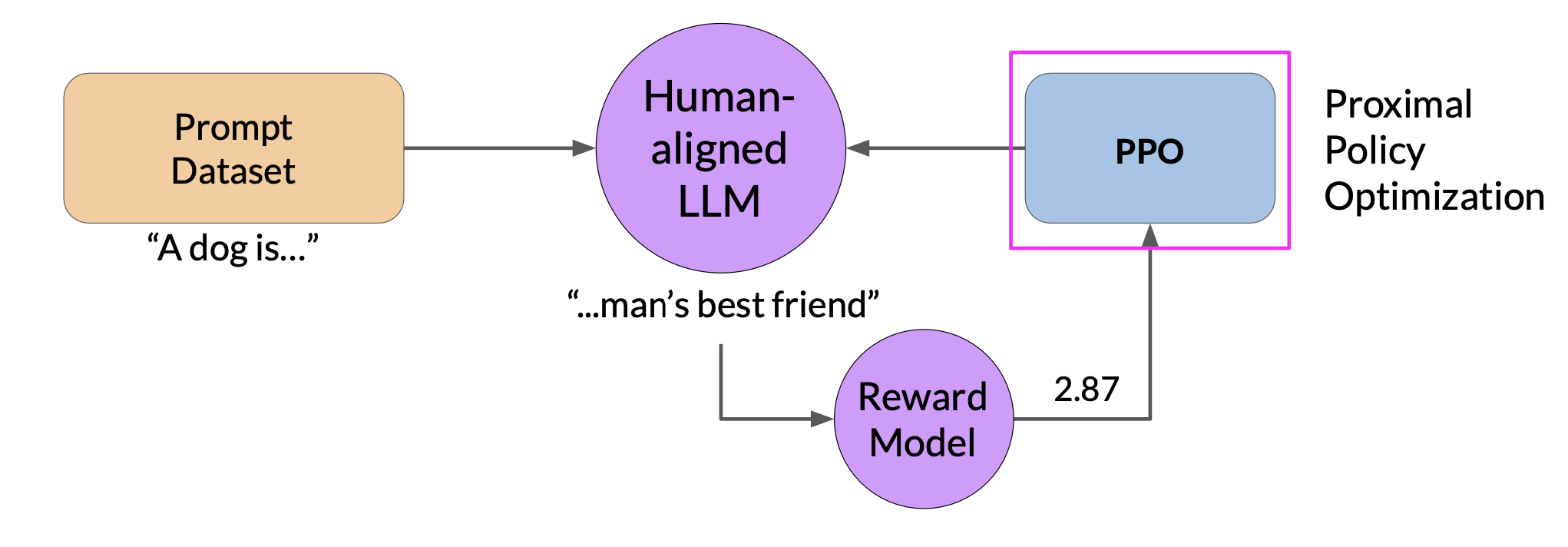
There are several RL algorithms that you can use for this part of the RLHF process. A popular choice is proximal policy optimization or PPO for short.
Model optimizations for deployment
- Distillation
- Post-training Quantization
- Pruning
Distillation
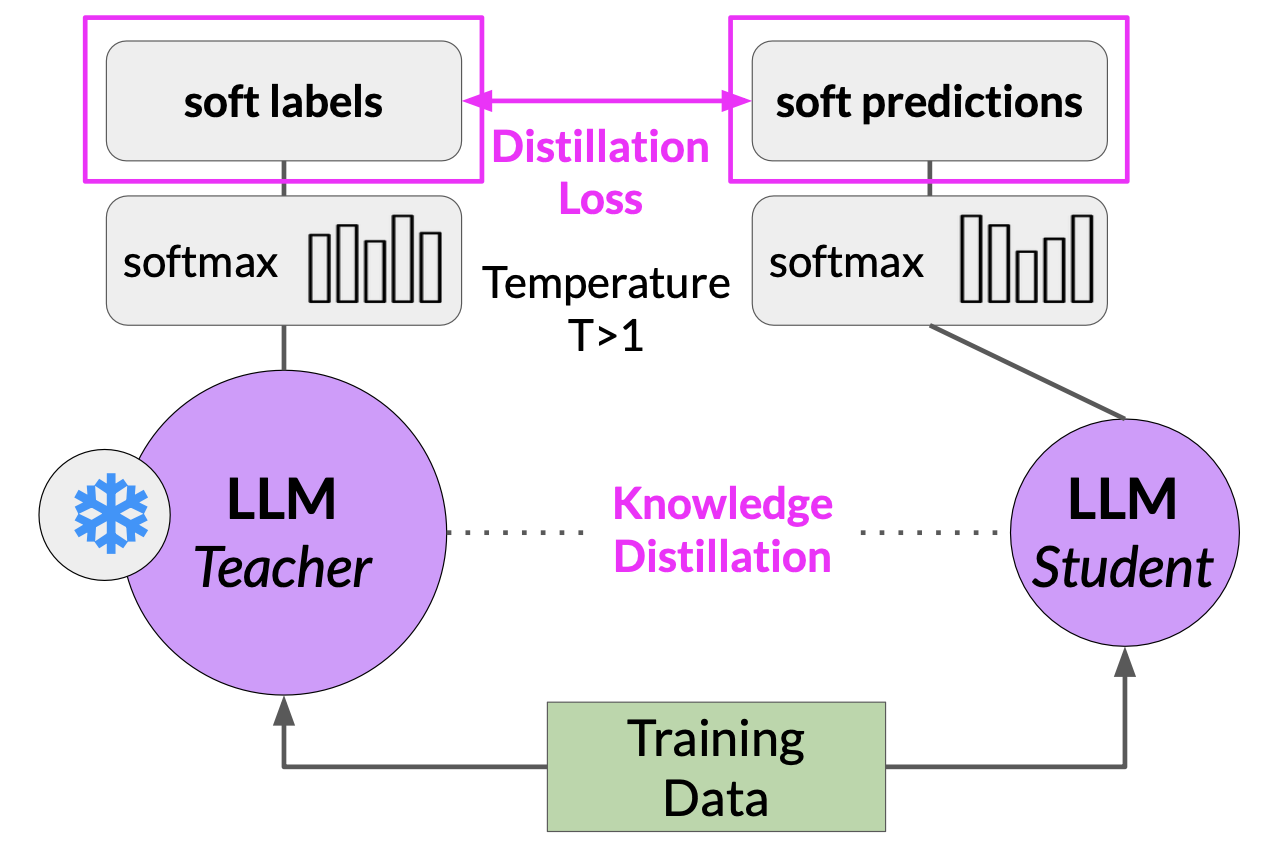
Model Distillation is a technique that focuses on having a larger teacher model train a smaller student model. The student model learns to statistically mimic the behavior of the teacher model, either just in the final prediction layer or in the model’s hidden layers as well.
- You start with your fine tune LLM as your teacher model and create a smaller LLM for your student model.
- You freeze the teacher model’s weights and use it to generate completions for your training data
- At the same time, you generate completions for the training data using your student model.
- The knowledge distillation between teacher and student model is achieved by minimizing a loss function called the distillation loss. To calculate this loss, distillation uses the probability distribution over tokens that is produced by the teacher model’s softmax layer
In parallel, you train the student model to generate the correct predictions based on your ground truth training data. Here, you don’t vary the temperature setting and instead use the standard softmax function. Distillation refers to the student model outputs as the hard predictions and hard labels. The loss between these two is the student loss. The combined distillation and student losses are used to update the weights of the student model via back propagation.
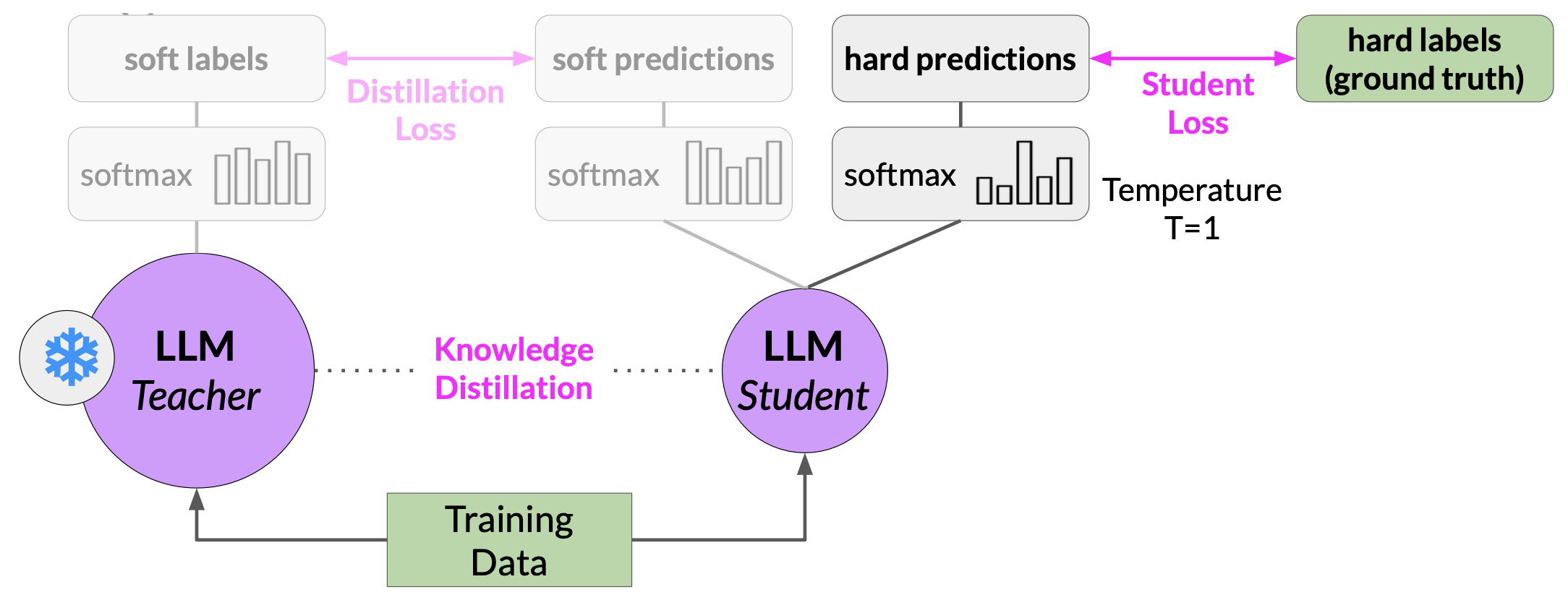
The key benefit of distillation methods is that the smaller student model can be used for inference in deployment instead of the teacher model. In practice, distillation is not as effective for generative decoder models. It's typically more effective for encoder only models, such as BERT that have a lot of representation redundancy.
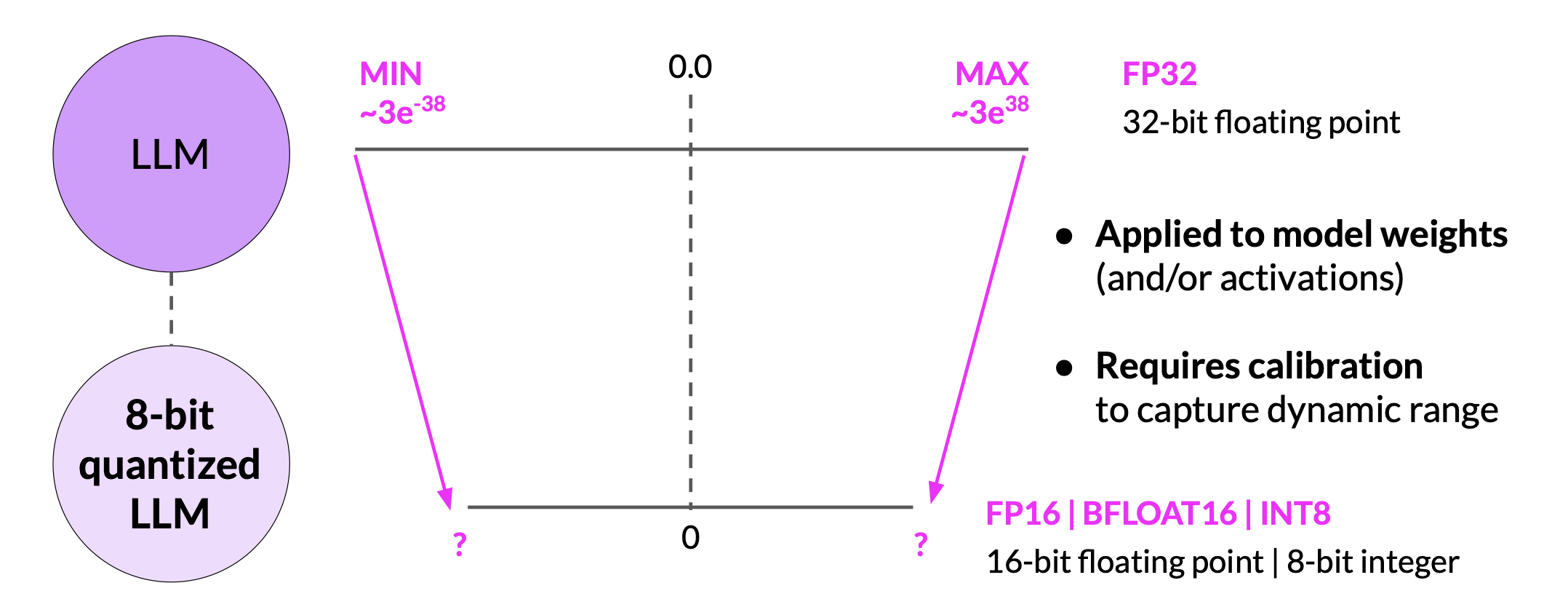
Post-Training Quantization (PTQ)
Pruning
At a high level, the goal is to reduce model size for inference by eliminating weights that are not contributing much to overall model performance. These are the weights with values very close to or equal to zero
Retrieval augmented generation (RAG)
Retrieval Augmented Generation, or RAG for short, is a framework for building LLM powered systems that make use of external data sources and applications to overcome some of the limitations of these models.
RAG is useful in any case where you want the language model to have access to data that it may not have seen. This could be new information documents not included in the original training data, or proprietary knowledge stored in your organization’s private databases.

-
At the heart of this implementation is a model component called the
Retriever, which consists of a query encoder and an external data source. The encoder takes the user’s input prompt and encodes it into a form that can be used to query the data source. -
These two components are trained together to find documents within the external data that are most relevant to the input query. The Retriever returns the best single or group of documents from the data source and combines the new information with the original user query.
-
The new expanded prompt is then passed to the language model, which generates a completion that makes use of the data.
-
External Information Sources
- Documents / Wikis
- Expert Systems
- Web pages
- Databases
- Vector Store
Data preparation for vector store for RAG
Two considerations for using external data in RAG:
- Data must fit inside context window
- Data must be in format that allows its relevance to be assessed at inference time: Embedding vectors
Building generative applications

Resources
- Training language models to follow instructions with human feedback
- Learning to summarize from human feedback
- Proximal Policy Optimization Algorithms
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Constitutional AI: Harmlessness from AI Feedback
- Chain-of-thought Prompting Elicits Reasoning in Large Language Models
- PAL: Program-aided Language Models
- ReAct: Synergizing Reasoning and Acting in Language Models
- LangChain Library (GitHub)
- Who Owns the Generative AI Platform?