
CLIP Encoders
CLIP (Contrastive Language-Image Pre-training)
Contrastive learning is a family of self-supervised learning methods that help models learn meaningful representations from data that don’t have labels. The key idea is that images showing similar objects should have similar representations.
CLIP is one of the contrastive models. It was first introduced by OpenAI. The goal is to learn a shared embedding space where text descriptions and images are mapped to vectors that are semantically aligned.
The CLIP model is trained using 400 million (image, text) pairs, where the text is the caption of the image. Thus, after training, the model can encode images and text into a vector that can best represent the images’ content in the CLIP embedding space.
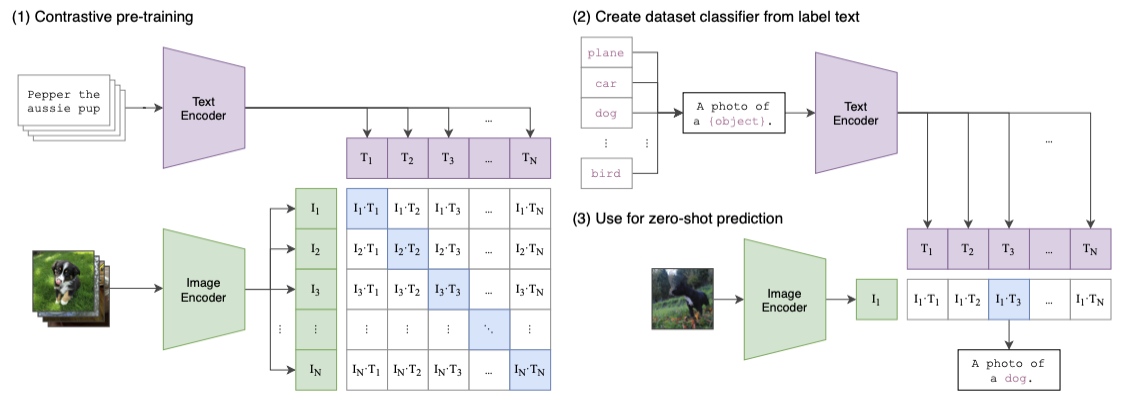
Here are the high-level steps of the training process:
- Let a batch of images go through an image encoder (a ResNet50/ViT model) to produce the feature embeddings $I_e$.
- Let a batch of the corresponding text captions go through a text encoder (a Transformer model) to produce the text embedding $T_e$.
- Calculate the embedding cosine similarities between $I_e$ and $T_e$
- Update both encoders’ weights to maximize the similarity for the correct pairs (the blue squares along the diagonal direction in the diagram)
- Update both encoders’ weights to minimize the similarity for the incorrect pairs (white squares in the diagram)
Once the model is pre-trained, it proceeds through a zero-shot transfer learning phase. Due to length of this post, we won’t cover it in detail here—refer to the original CLIP paper for a thorough explanation.
In Stable Diffusion, only the CLIP text encoder is used to convert text prompts into embeddings. These text embeddings then condition the image generation process. Let’s take a look at one example:
prompt = "a running dog"
# convert prompt to tokens
input_tokens = clip_tokenizer(
prompt,
return_tensors = "pt"
)["input_ids"]
print(input_tokens) # [49406, 320, 2761, 7251, 49407]
clip_text_encoder = CLIPTextModel.from_pretrained(
"runwayml/stable-diffusion-v1-5",
subfolder = "text_encoder",
cache_dir=CACHE_DIR
)
# encode input_tokens to embeddings
text_embeds = clip_text_encoder(input_tokens)[0]
# each input token is encoded into a 768-dim vector
print(text_embeds) # ([1, 5, 768])
For Stable Diffusion 1.5, each token will be encoded as a 768-dimensional vector in the CLIP embedding space. They will be used later in the downstream of the network.
Resources
- High-Resolution Image Synthesis with Latent Diffusion Models
- CLIP
- Contrastive Learning
- Auto-Encoding Variational Bayes
- Variational Autoencoders | Generative AI Animated
- Using Stable Diffusion with Python
Appendix: CLIP text encoder model architecture
CLIPTextModel(
(text_model): CLIPTextTransformer(
(embeddings): CLIPTextEmbeddings(
(token_embedding): Embedding(49408, 768)
(position_embedding): Embedding(77, 768)
)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPSdpaAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)