
Batch Normalization
上一篇文章我们介绍了不同的优化算法,同时我们也引入了一系列可调节参数,包括
- Gradient Descent Momentum: $\beta$
- Adam: $\beta_1$, $\beta_2$
- Learning Rate Decay
- Mini-batch size
加上之前文章中提到的关于神经网络的各种参数包括:
- Learning Rate: $\alpha$
- number of layers: $L$
- number of hidden units for each layer
这些参数中有一些比其它的重要,一般来说,$\alpha$是最重要的参数
Batch Normalization
前面文章我们曾提到对训练数据进行归一化处理可以加快训练速度:
\[\begin{aligned} \mu &= \frac{1}{m} \sum_i x^{(i)} \\ X &= X - \mu \\ \sigma^2 &= \frac{1}{m} \sum_i x^{(i)2} \quad \text{(element-wise)} \\ X &= \frac{X}{\sigma} \end{aligned}\]对于一个深层的神经网络来说,我们同样可以normalize每层的activation units: $a^{[l]}$,或者之前的hidden units: $z^{[l]}$,来使训练变得更快,这就是Batch Normalization的基本思想。具体做法如下
- 对于model中每层的hidden layer输出结果: $z^{(1)}$, $z^{(2)}$ … $z^{(m)}$,计算它们的均值 $\mu = \frac{1}{m} \sum_i z^{(i)}$和方差 $\sigma^2 = \frac{1}{m} \sum_i (z^{(i)}-\mu)^2$
- 对$z(i)$进行归一化处理: $z_{norm}^{(i)} = \frac{z^{(i)} - \mu}{\sqrt{\sigma^2 + \epsilon}}$,其中$\epsilon$的作用是避免$\sigma$为0
- 对$z^{(i)}$进行泛化处理: $\tilde{z}^{(i)} = \gamma \times z_{norm}^{(i)} + \beta$,此时$\gamma$和$\beta$是待训练的参数(learnable parameters)
在训练的过程中,由于sigmoid或者其它非线性activation函数的存在,我们往往不希望出现$\mu=1$, $\sigma = 0$的情况,这会导致我们的非线性函数无法发挥最大的作用。此时,通过控制$\gamma$和$\beta$的值来控制$z_{norm}^{(i)}$的取值范围,比如当$\gamma = \sqrt{\sigma^2 + \epsilon}$, $\beta = \mu$时,$\tilde{z}^{(i)} = z_{norm}^{(i)}$,当选取不同的$\gamma$和$\beta$时,我们可以间接的控制$z^(i)$的均值和方差。
接下来我们需要将每层hidden units的输出从$z^(i)$ 替换为 $\tilde{z}^{(i)}$:
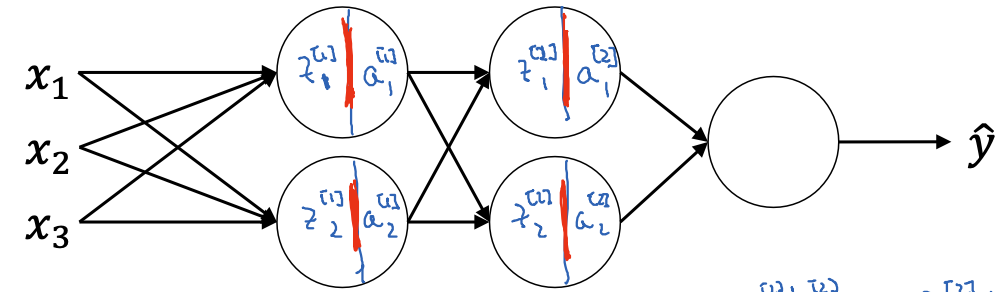
(w_1, b_1) (beta_1, gamma_1)
x --------> z_1 ---------------> batch_norm -> z'_1 -> a_1
(w_2, b_2) (beta_2, gamma_2)
a_1 -------> z_2 ---------------> batch_norm -> z'_2 -> a_2
Batch Norm通常和mini-batch一起使用:
\[X^{\text{\{1\}}} \xrightarrow[]{W^{[1]}, b^{[1]}} z^{[1]} \xrightarrow[]{\beta^{[1]}, \gamma^{[1]}} \tilde{z}^{[1]} \xrightarrow[]{g^{[1]} (\tilde{z}^{[1]})} a^{[1]} \xrightarrow[]{W^{[2]}, b^{[2]}} z^{[2]} \rightarrow \dots\] \[X^{\text{\{2\}}} \xrightarrow[]{W^{[1]}, b^{[1]}} z^{[1]} \xrightarrow[]{\beta^{[1]}, \gamma^{[1]}} \tilde{z}^{[1]} \xrightarrow[]{g^{[1]} (\tilde{z}^{[1]})} a^{[1]} \xrightarrow[]{W^{[2]}, b^{[2]}} z^{[2]} \rightarrow \dots\] \[\dots\] \[X^{\text{\{m\}}} \xrightarrow[]{W^{[1]}, b^{[1]}} z^{[1]} \xrightarrow[]{\beta^{[1]}, \gamma^{[1]}} \tilde{z}^{[1]} \xrightarrow[]{g^{[1]} (\tilde{z}^{[1]})} a^{[1]} \xrightarrow[]{W^{[2]}, b^{[2]}} z^{[2]} \rightarrow \dots\]此时,我们需要训练的参数有:$w^{[l]}$,$b^{[l]}$,$\gamma^{[l]}$和$\beta^{[l]}$,其中后三个参数都是$(n^{[l]},1)$的矩阵,实际上如果使用了Batch Norm,$b^{[l]}$会被cancel out,因此,我们可以直接去掉bias或者另其值为0即可,此时
\[\tilde{z}^{[l]} = \gamma^{[l]} z_{norm}^{[l]} + \beta^{[l]}\]在backprop时,我们只需要更新其余三个参数即可
\[\begin{aligned} W^{(l)} &:= W^{(l)} - \alpha \, dW^{(l)} \\ \beta^{(l)} &:= \beta^{(l)} - \alpha \, d\beta^{(l)} \\ \gamma^{(l)} &:= \gamma^{(l)} - \alpha \, d\gamma^{(l)} \\ \end{aligned}\]Why does Batch Norm work
一个简单的intuition是BN减少了前面layer的weights对后面layer的weights的影响。具体来说,在训练的时候,由于输入的训练数据不断变化,它会影响每一个layer的activation的值分布,进而可能出现covariant shift的情况。而由上面可以,通过控制$\gamma$和$\beta$,BN可以做到对任意两层hidden units($z^{[l]}$, $z^{[l-1]})$的均值和方差保持不变,来抵消掉activation在分布上的偏移,从而使模型更加的泛化。此外,由于BN对activation的修正,它还起到了regularization的作用。
Batch Norm at inference time
前面提到,在training的时候,BN通常和mini-batch一起使用,具体来说,BN一次处理一个mini batch的数据。但是当model训练完成后,$\beta$和$\gamma$的值也相应的确定,并且是基于mini batch的batch size训练得到的,此时,如果我们对某一条数据做inference时,该如何处理?
此时我们需要对$\mu$和$\sigma$做一些处理,具体做法是在training的时候计算$\mu$和$\sigma$的exponential weighted average,在inference时候用这个结果做近似。实际应用中。大部分Deep Learning Framework内部会实现这个过程,所以不需要特别担心。