
An Overview of the Transformer architecture
Generative models before Transformer
Previous generations of language models made use of an architecture called RNN. RNNs while powerful for their time, were limited by the amount of compute and memory needed to perform well at generative tasks.
To successfully predict the next word, models need to see more than just the previous few words. Models needs to have an understanding of the whole sentence or even the whole document.
Attention is all you need
In 2017, after the publication of this paper, “Attention is All You Need”, from Google and the University of Toronto. The transformer architecture had arrived. This novel approach unlocked the progress in generative AI that we see today. It can be scaled efficiently to use multi-core GPUs, it can parallel process input data, making use of much larger training datasets, and crucially, it’s able to learn to pay attention to the meaning of the words it’s processing.
The power of the attenion mechanism lies in its ability to learn the relevance and context of all of the words in a sentence, not just the words next to its neighbors, but every other word in a sentence.

We apply attention weights to those relationships so that the model learns the relevance of each word to each other words no matter where they are in the input. This gives the algorithm the ability to learn “who has the book”, “who could have the book”, and if it’s even relevant to the wider context of the document.

These attention weights are learned during LLM training. In the end, we will learn something called “attention map”, which can be useful to illustrate the attention weights between each word and every other words.
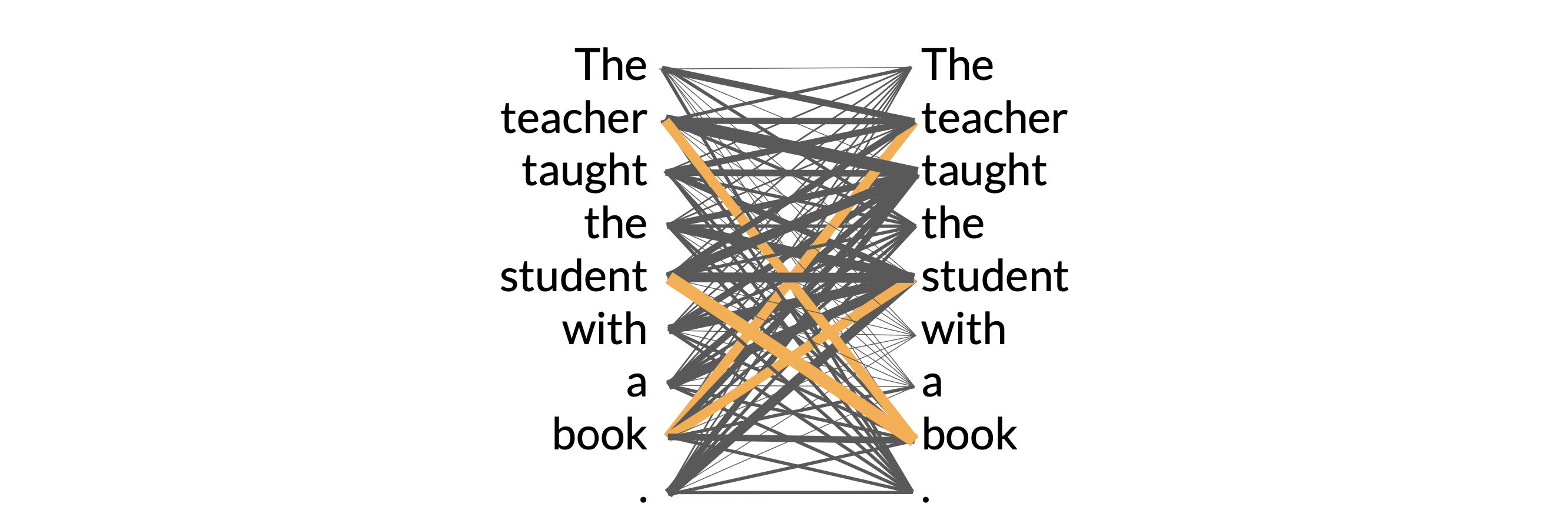
In this example, you can see that the word book is strongly connected with the word teacher and the word student.
This is called self-attention and the ability to learn attention in this way across the whole input significantly improves the model’s ability to encode language
The Transformer Architecture Overview
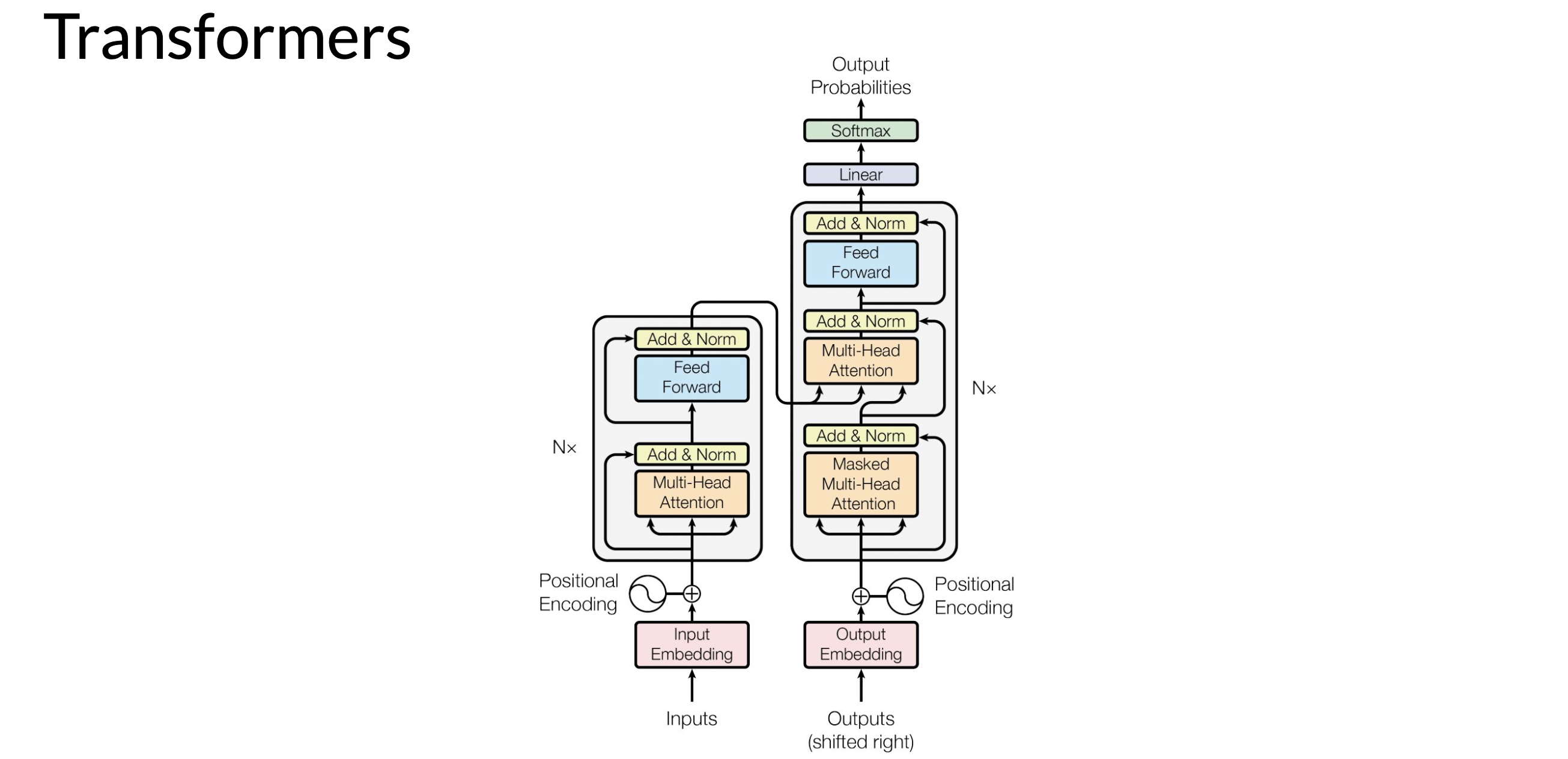
The transformer architecture is split into two distinct parts, the encoder and the decoder. These components work in conjunction with each other and they share a number of similarities.
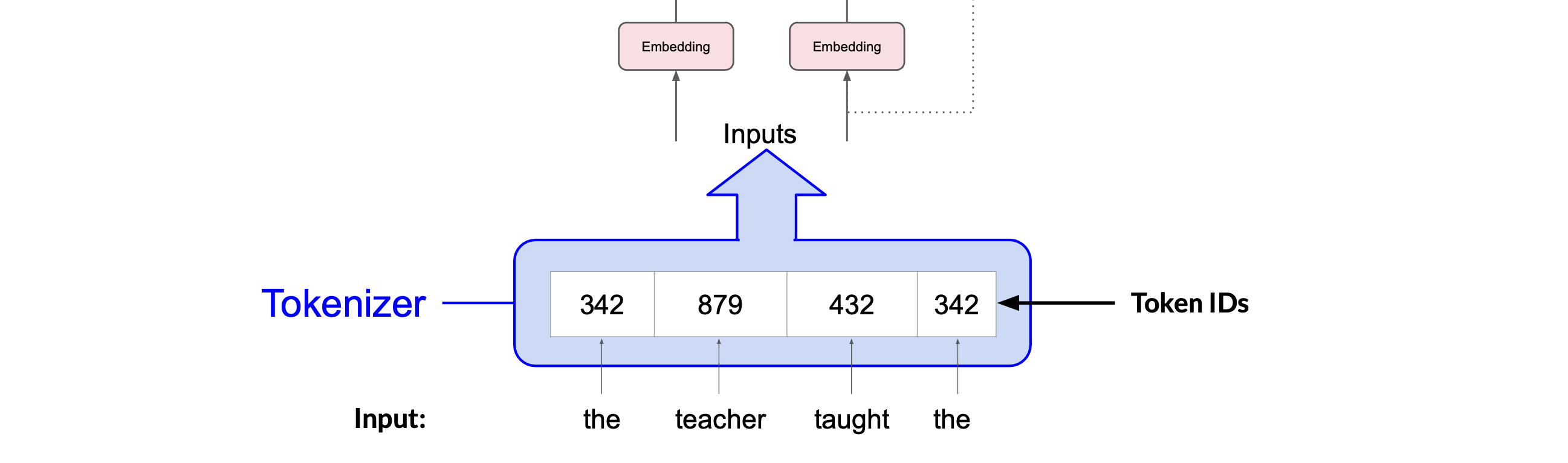
Inputs and embedding
The inputs are first converted to tokens(one-hot vectors), with each number representing a position in a dictionary of all the possible words that the model can work with.
What’s important is that once you’ve selected a tokenizer to train the model, you must use the same tokenizer when you generate text.
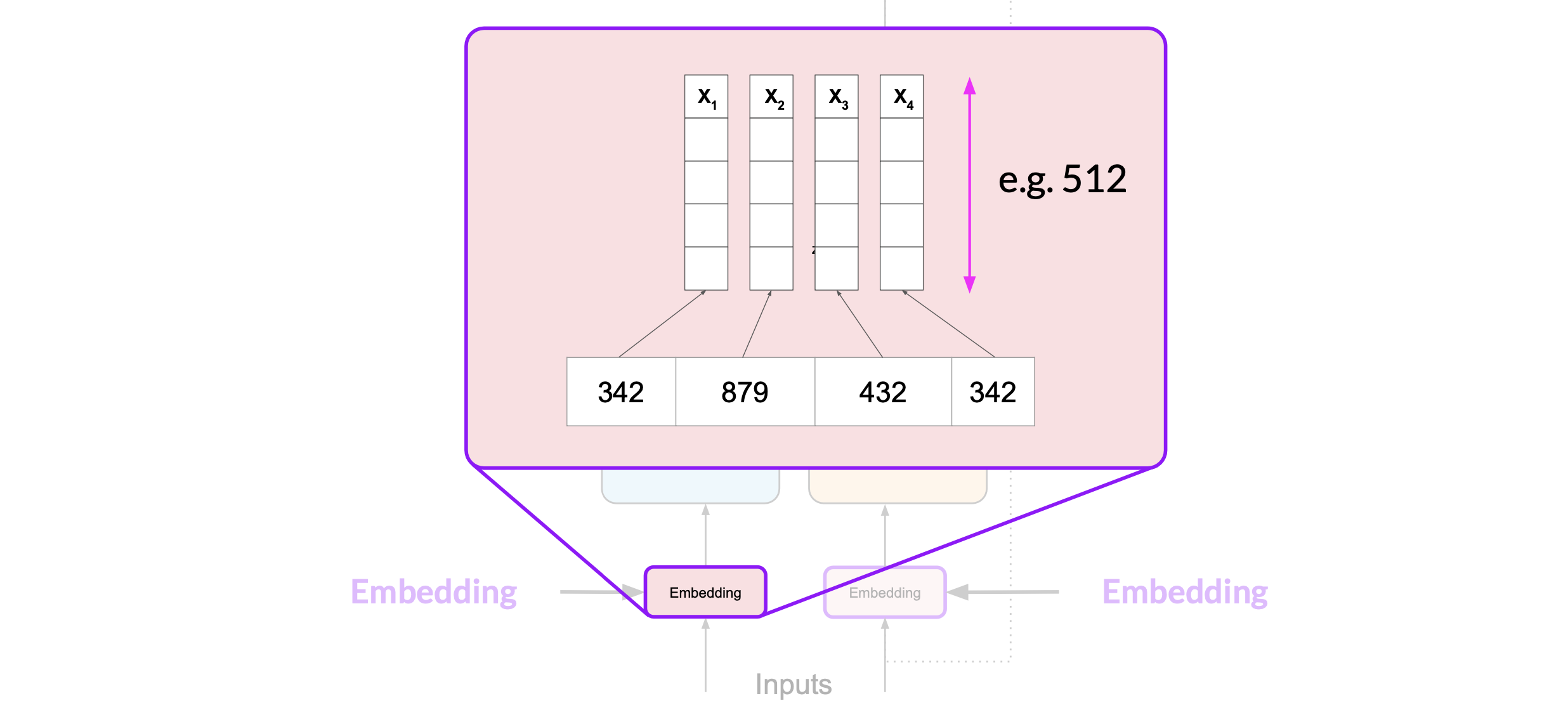
Now that your input is represented as numbers, you can pass it to the embedding layer. This layer is a trainable vector embedding space, a high-dimensional space where each token is represented as a vector and occupies a unique location within that space. The intuition is that these vectors learn to encode the meaning and context of individual tokens in the input sequence
In the original transformer paper, the vector size was actually 512.
For simplicity, if you imagine a vector size of just three, you could plot the words into a three-dimensional space and see the relationships between those words and calcuate the distance between those words.
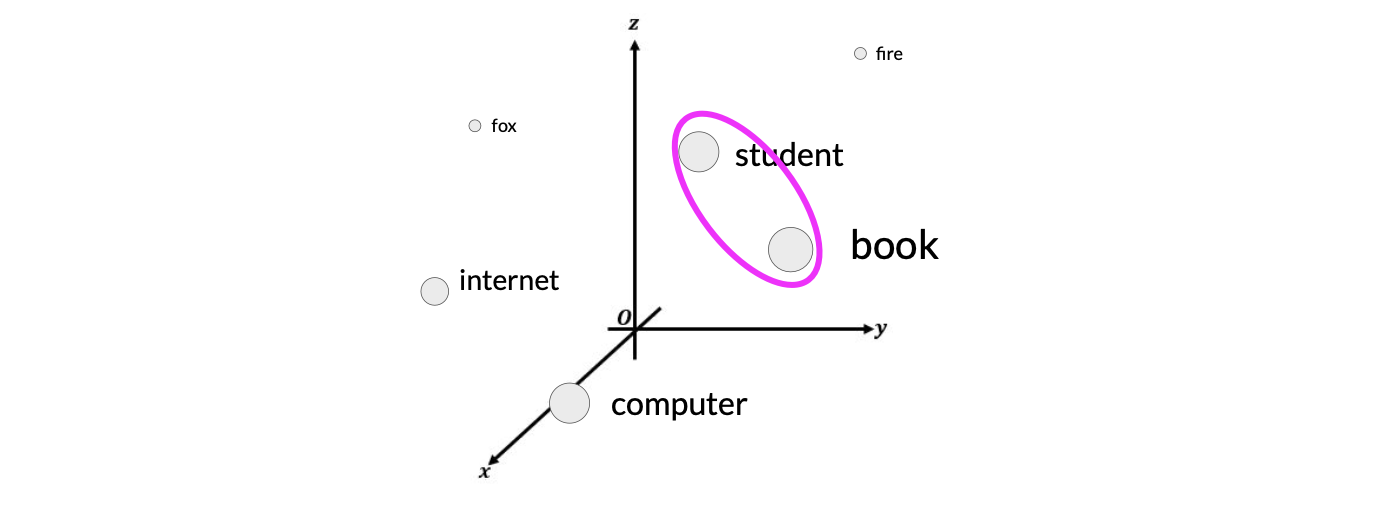
Since the model processes each of the input tokens in parallel. We need to preserve the information about the word order and don’t lose the relevance of the position of the word in the sentence. We do so by adding the positional encoding. Once the positional encoding vectors are merged into the input tokens, we pass the resulting vectors to the self-attention layer.
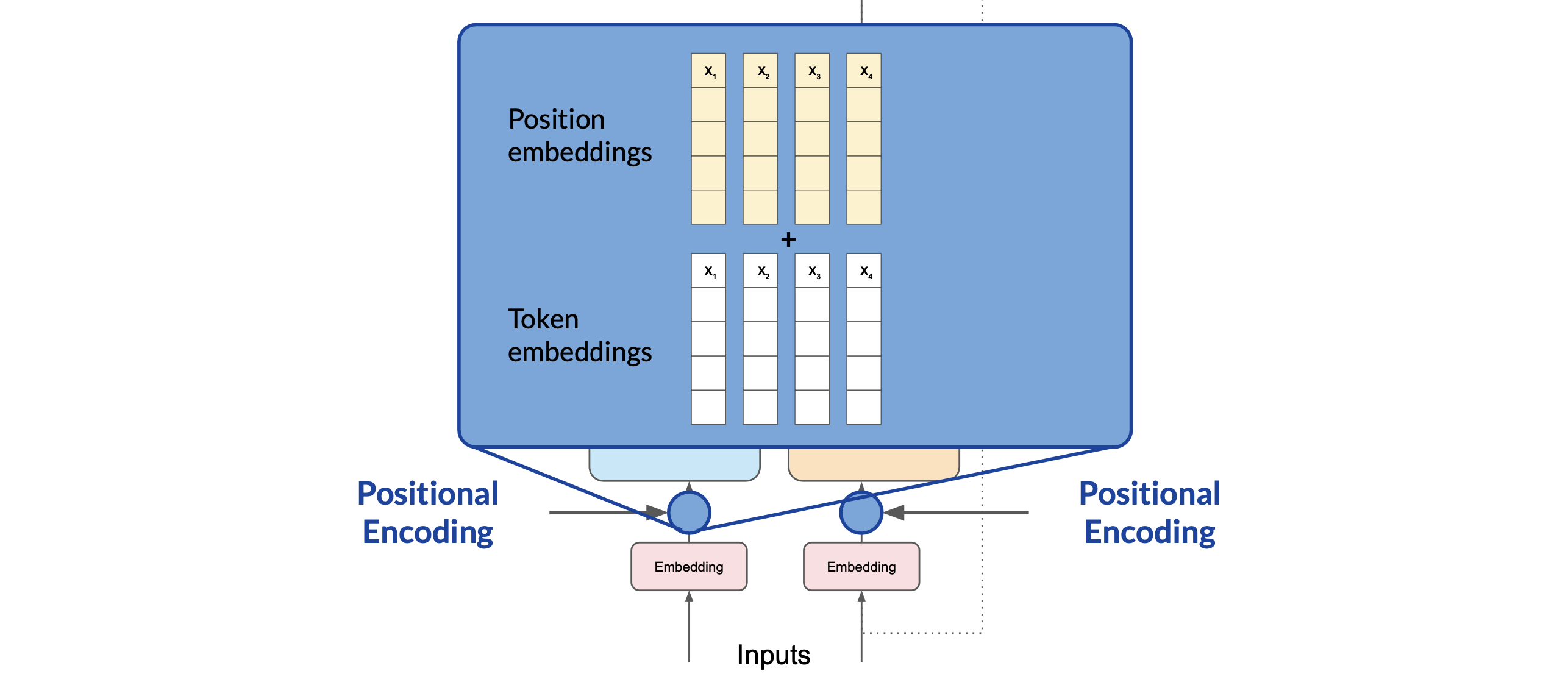
The model analyzes the relationships between the tokens in your input sequence. This allows the model to attend to different parts of the input sequence to better capture the contextual dependencies between the words.
Self attention
The self-attention weights that are learned during training and stored in these layers reflect the importance of each word in that input sequence to all other words in the sequence. But this does not happen just once, the transformer architecture actually has multi-headed self-attention.
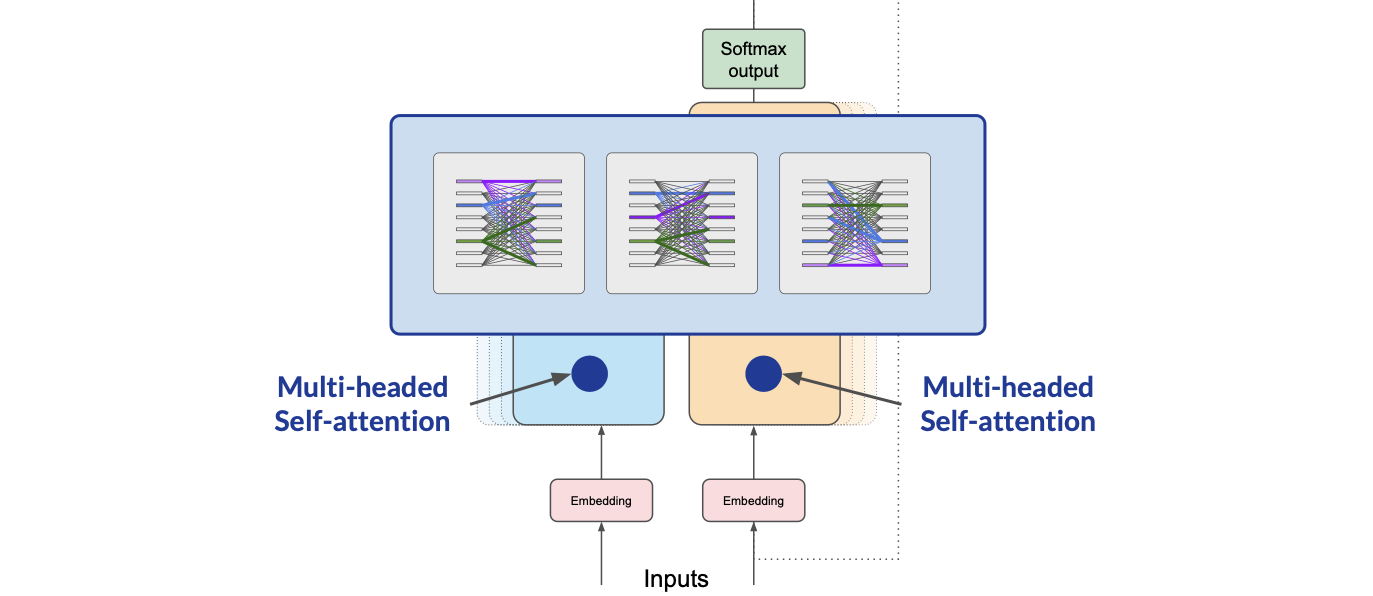
This means that multiple sets of self-attention weights or heads are learned in parallel independently of each other. The number of attention heads included in the attention layer varies from model to model, but numbers in the range of 12 to 100 are common.
The intuition here is that each self-attention head will learn a different aspect of language. For example, one head may see the relationship between the people entities in our sentence. While another head may focus on the activity of the sentence.
It is important to note that we don't dictate ahead of time what aspects of language the attention heads will learn. The weights of each head are randomly initialized and given sufficient training data and time, each will learn different aspects of language.
Feed foward + Softmax layer
Now the output is processed through a fully-connected feed-forward network followed by a softmax layer. The output of this layer is a vector of logits proportional to the probability score for each and every token in the tokenizer dictionary. You can then pass these logits to a final softmax layer, where they are normalized into a probability score for each word
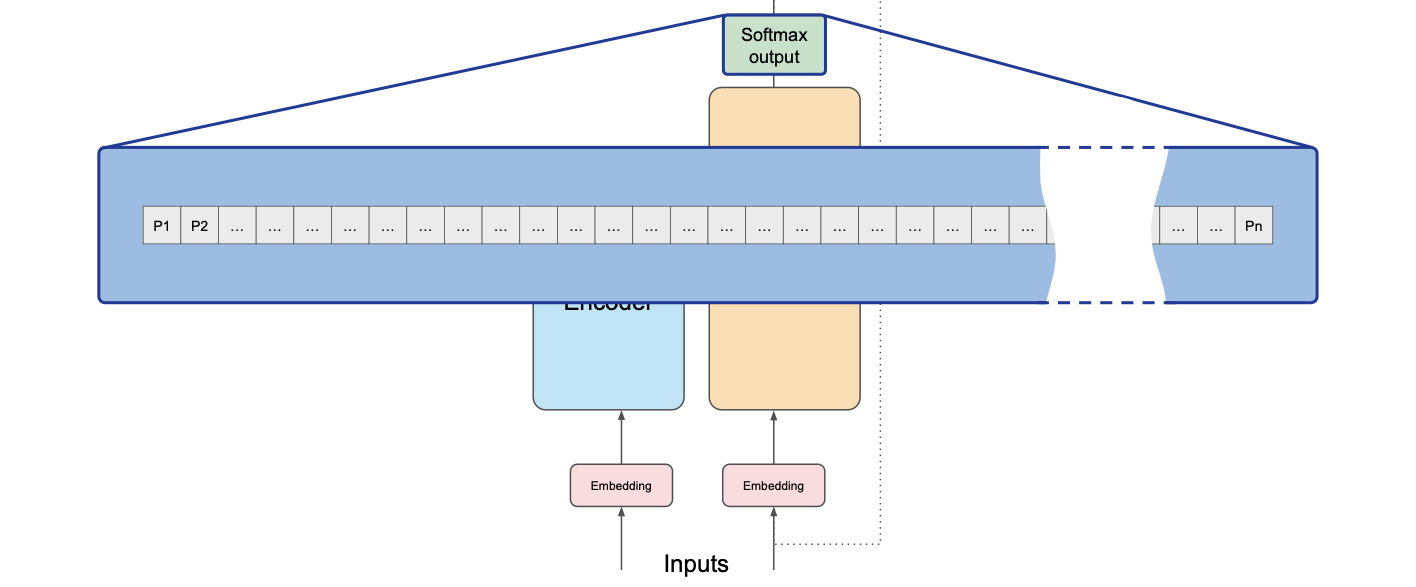
The outputs are normalized into a probability score for each word. This output includes a probability for every single word in the dictionary, so there’s likely to be thousands of scores here.